本文针对百年孤独小说评论的主题分析
词云图


代码:
install.packages("jiebaRD")
install.packages("jiebaR")
install.packages("lda")
install.packages("LDAvis")
library(jiebaRD)
library(jiebaR)
library(lda)
library(LDAvis)
#去数字、字母
data<-read.csv("comments.csv",header=T, stringsAsFactors=T)
removeNumbers=function(x){ret=gsub("[0-9 0 1 2 3 4 5 6 7 8 9]","",x)}
sample.words<-lapply(data$comments,removeNumbers)
head(sample.words)
doc=c(NULL)
for(i in 1:dim(data)[1]){doc=c(doc,sample.words[i])}
#字母处理
doc=gsub(pattern="[a-zA-Z]+","",doc)
head(doc)
write.table(doc,"comments.txt")#文本
#从网上搜索结合哈工大停用词表、四川大学机器智能实验室停用词库、百度停用词表命名为stopWords。创建分词器,其中bylines是否按行来分,user用户词典这里没有设置,stop_word停用词典。
cutter <- worker(bylines = T,stop_word = "中文停词库.txt")
#文件分词,直接输入文件地址,分完后自动保存成文件
comments_seg <- cutter["comments.txt"]
#由于LDA主题模型不是对文本进行运算,在做主题建模前,还需将文本转化为向量,用数字来代替文本,从而方便运算。#读取分词结果
comments_segged<- readLines("comments.segment.2019-04-07_16_34_11.txt",encoding="UTF-8")
#将向量转化为列表
comments <- as.list(comments_segged)
#将每行文本,按照空格分开,每行变成一个词向量,储存在列表里
doc.list <- strsplit(as.character(comments),split=" ")
#创建一个词典,并给每个词取一个编号
#这里有两步,unlist用于统计每个词的词频;table把结果变成一个交叉表式的factor,原理类似python里的词典,key是词,value是词频
term.table <- table(unlist(doc.list))
#按照词频降序排列
term.table <- sort(term.table, decreasing = TRUE)
#用stop_words去掉了数字、标点符号、虚词等,由于现代汉语里用单字表示一个词语的词已经很少了,这里为了提高建模效果,我们可以将单字去掉,同时也可以把出现次数少于5次的词去掉。#把不符合要求的筛出来
del <- term.table < 5| nchar(names(term.table))<2
#去掉不符合要求的
term.table <- term.table[!del]
write.table(term.table,"words.freq.txt")#读出分词结果及词频
write.csv(term.table,"words.freq.csv")
#绘制词云图
a2=read.csv("words.freq.csv")
a2=a2[1:182,2:3]
install.packages("wordcloud2")
library(wordcloud2)
wordcloud2(a2,shape='star',color='random-dark',backgroundColor="white",size=1)
#创建词库
vocab <- names(term.table)
#把文本的格式整理成lda包建模需要的格式
get.terms <- function(x)
{
index <- match(x, vocab) # 获取词的ID
index <- index[!is.na(index)] #去掉没有查到的,也就是去掉了的词
rbind(as.integer(index - 1), as.integer(rep(1, length(index)))) #生成上图结构
}
documents <- lapply(doc.list, get.terms)
#LDA主题建模
K <-4 #主题数
G <- 5000 #迭代次数
alpha <- 0.10
eta <- 0.02
library(lda)
set.seed(357)
result<- lda.collapsed.gibbs.sampler(documents = documents, K = K, vocab = vocab, num.iterations = G, alpha = alpha, eta = eta, initial = NULL, burnin = 0, compute.log.likelihood = TRUE)
Topics <- apply(top.topic.words(result$topics, 8, by.score=TRUE),
2, paste, collapse=" ")
aa=length(Topics)
t=c()
for(i in 1:aa)
{t[i]=paste(i,Topics[i],sep="")}
a=apply(result$document_sums,
1,sum)
names(a)<-t
p=data.frame(a=t,b=a)
p=p[order(p[,2],decreasing=T),]
a1=c()
c=c("a","b","c","d","e","f","g","h","i","j","k","l","m","n","o","p","q","r","s","t","u","v","w","x","y","z"
,"za","zb","zc","zd")
for(i in 1:aa)
{
a1[i]= paste(c[i],p$a[i],sep="")
}
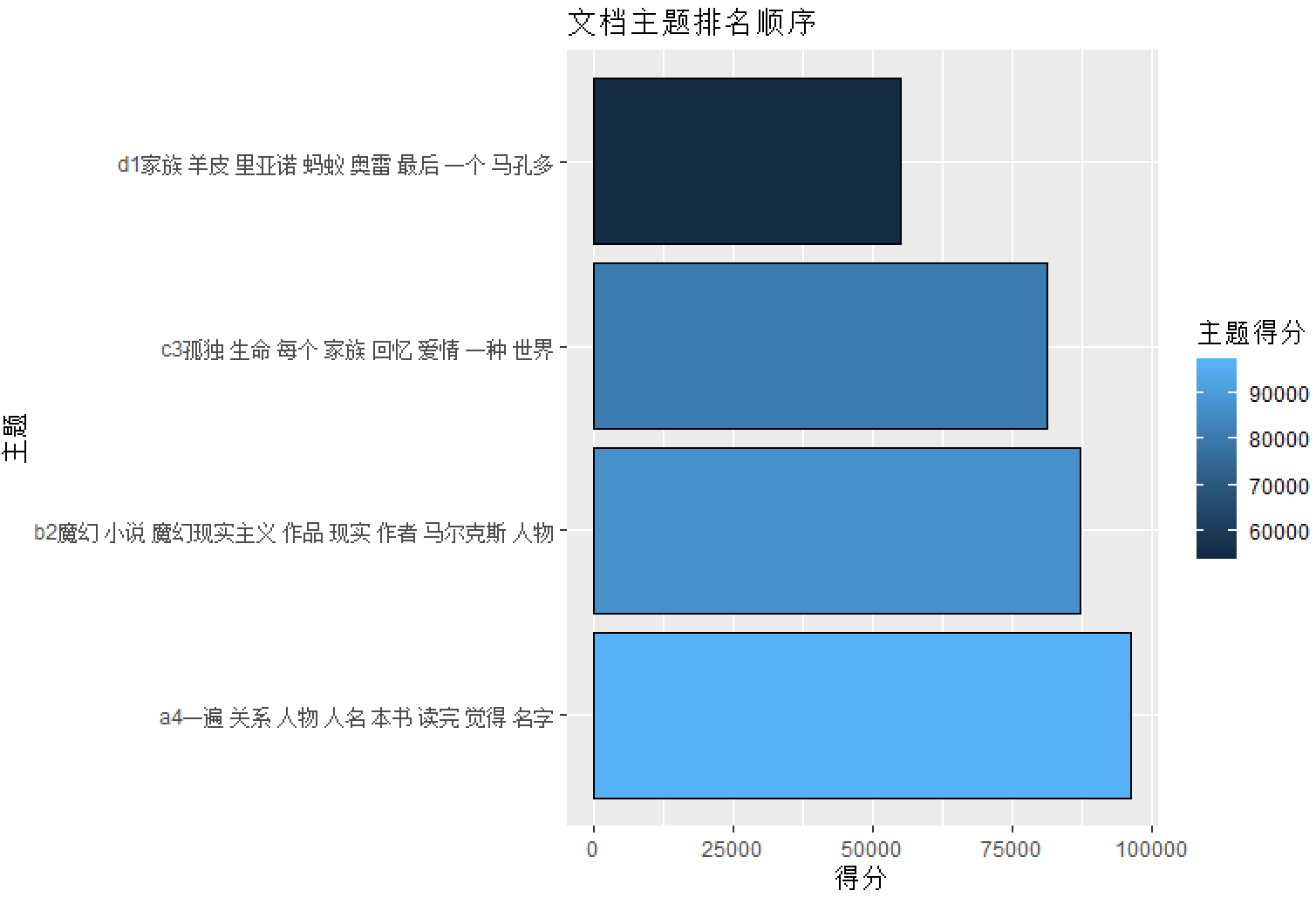
p1=data.frame(a=a1,主题得分=p$b)
library(ggplot2)
ggplot(data=p1, aes(x=a, y=主题得分, fill=主题得分)) +
geom_bar(colour="black", stat="identity") +
labs(x = "主题", y = "得分") + ggtitle("文档主题排名顺序")+ coord_flip()
Topics <- top.topic.words(result$topics, 20, by.score=TRUE)
a=c()
b=c()
for(i in 1:4)
{
a=c(a,Topics[,i])
b=c(b,rep(paste("主题",i,sep=""),20))
}
a = table(a, b)
a = as.matrix(a)
install.packages("wordcloud")
install.packages("RColorBrewer")
library(wordcloud)
comparison.cloud(a, scale = c(1, 1), rot.per = 0.5, colors = brewer.pal(ncol(a),"Dark2"))
