通过连接,可以访问hive中表数据,和访问关系型数据库中数据表一样,语尽,详细操作如下:
1、修改E:\kettle5.1.0\data-integration\plugins\pentaho-big-data-plugin下的plugin.properties
修改active.hadoop.configuration=hdp20
2、 修改E:\kettle5.1.0\data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\hdp20文件夹下的
yarn-site.xml
mapred-site.xml
core-site.xml
hbase-site.xml
将集群里的对应xml文件(/etc/hyperbase1/conf和/etc/yarn1/conf)替换上面
3、 替换该文件夹下的相关jar包
E:\kettle5.1.0\data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\hdp20\lib
可通过在集群上运行sh getTranswarpJDBC.sh获取相关jar包
4、新建数据源,配置如下信息

5、把经过kettle处理之后的数据放到inceptor表中,注意:分区的表可以会有一个限制,有些分区表插入只能从分区表插入(排除步骤如下):
5.1) 直接通过kettle生成inceptor表,插入数据时出现错误
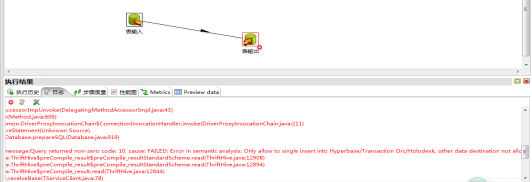
5.2)在inceptor中建立分区的orc表

5.3)出现错误

5.4)建立没有分区的orc表,结果ok!
create table vio_surveil_bak2 (rqbm string,inde int) CLUSTERED by (rqbm) into 2 BUCKETS STORED AS ORC tblproperties("transactional"="true");
附:
错误代码:
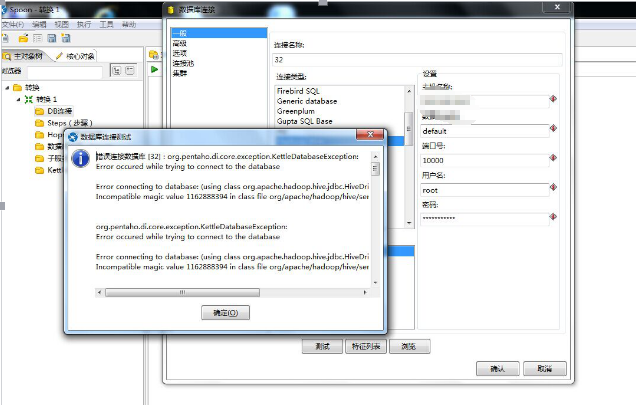
解决方法:第一次把hive-jdbc-0.12.0-transwarp-tdh40.jar删掉了,然后再加上好了????
上面这些jar不能放到E:\kettle5.1.0\data-integration\lib 下,负责报错
参考地址:
http://qq85609655.iteye.com/blog/2109124
获取jar的sh(getTranswarpJDBC.sh)
dir=TranswarpJDBC
rm -rf $dir
mkdir $dir
cd $dir
array=(
"commons-"
"commons-"
"commons-"
"commons-"
"commons-"
""
""
""
""
""
""
"slf4j-"
"slf4j-"
)
for app in ${array[@]}
do
var=`ls -r /usr/lib/hive/lib/$app* |grep $app\.[0-9]*\.[0-9]*\.[0-9]*\.jar`
arr=(${var// /})
echo ${arr[0]}
cp ${arr[0]} ./
done
array=(
"hive-common-0.12.0-transwarp-tdh40.jar"
"hive-jdbc-0.12.0-transwarp-tdh40.jar"
"hive-metastore-0.12.0-transwarp-tdh40.jar"
"hive-serde-0.12.0-transwarp-tdh40.jar"
"hive-service-0.12.0-transwarp-tdh40.jar"
)
for app in ${array[@]}
do
echo /usr/lib/hive/lib/$app
cp /usr/lib/hive/lib/$app ./
done
cp /usr/lib/hadoop/hadoop-annotations-2.5.2-transwarp.jar ./
echo "/usr/lib/hadoop/hadoop-annotations-2.5.2-transwarp.jar"
cp /usr/lib/hadoop/hadoop-auth-2.5.2-transwarp.jar ./
echo /usr/lib/hadoop/hadoop-auth-2.5.2-transwarp.jar
cp /usr/lib/hadoop/hadoop-common-2.5.2-transwarp.jar ./
echo /usr/lib/hadoop/hadoop-common-2.5.2-transwarp.jar
cp /usr/lib/hadoop-hdfs/hadoop-hdfs-2.5.2-transwarp.jar ./
echo /usr/lib/hadoop-hdfs/hadoop-hdfs-2.5.2-transwarp.jar
count=`ls |wc -l`
if [ $count != "22" ]; then
echo "********************************"
echo "* Should be 22 files in all! *"
echo "********************************"
fi
cd ..
不喜勿喷,欢迎指点〉〉〉OK

