通过tensorflow的lstm利用AI的思想把简单的问题复杂化(~\/~),预测北京快三的和值(其实就是A+B+C)<21111技术男。类似思想可以做多指标的回归预测。(重在思想和技术提升)
基础数据从mysql获取,如下:
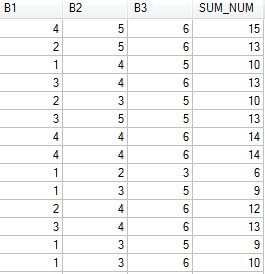
完整代码如下:
#python 使用pymysql
#######################################################0、加载常用的库
import pymysql
import pandas as pd
import numpy as np
import math
import tensorflow as tf
from sklearn.metrics import mean_absolute_error,mean_squared_error
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
#% matplotlib inline
import warnings
warnings.filterwarnings('ignore')
#打开数据库连接
db = pymysql.connect(host = '0.0.0.0',user = 'huaqinglian',
password = '123456',db= 'kuaisan',port = 3306)
#使用cursor方式获取数据
cur = db.cursor()
#####################################################1、查询数据
sql = "select B1,B2,B3,SUM_NUM from fc_sd order by K1 limit 540"
try:
#执行sql语句
cur.execute(sql)
#h获取查询的所有记录
results = cur.fetchall()
#遍历结果
# print("B1","B2","B3","SUM_NUM")
# for row in results:
# B1 = row[0]
# B2 = row[1]
# B3 = row[2]
# SUM_NUM = row[3]
# print(B1,B2,B3,SUM_NUM)
except Exception as e:
raise e
finally:
#关闭连接
db.close()
print("----------")
#print(results)
print("---------------")
data = []
#data.append(list(i) for i in results)
for i in results:
data.append(list(i))
#print(i)
#print(data)
print("------------------")
data = np.array(data)
#print(data)
print(data.shape)
###################################################2、定义常量,并初始化权重
rnn_unit = 10 #hidden layer units
input_size = 3
output_size = 1
lr = 0.0006 #学习率
tf.reset_default_graph()
#输入层、输出层权重,偏置
weights = {
'in' : tf.Variable(tf.random_normal([input_size,rnn_unit])),
'out' : tf.Variable(tf.random_normal([rnn_unit,output_size]))
}
biases = {
'in':tf.Variable(tf.constant(0.1,shape=[rnn_unit,])),
'out':tf.Variable(tf.constant(0.1,shape=[1,]))
}
#######################################3、分割数据集,将数据分为训练集和验证集(最后90天做验证,其他做训练)
#batch_size:打印小节点
def get_data(batch_size=60,time_step=20,train_begnin=0,train_end=420):
batch_index = []
scaler_for_x = MinMaxScaler(feature_range=(0,1)) #按列做minmax缩放
scaler_for_y = MinMaxScaler(feature_range=(0,1))
scalerd_x_data = scaler_for_x.fit_transform(data[:,:-1])
scalerd_y_data = scaler_for_y.fit_transform(np.reshape(data[:,-1],[-1,1]))#reshape实现行转列,从一维转化为二维
label_train = scalerd_y_data[train_begnin:train_end]
label_test = scalerd_y_data[train_end:]
normalized_train_data = scalerd_x_data[train_begnin:train_end]
print("-------------------------------scalerd_x_data")
print(np.shape(scalerd_x_data))
normalized_test_data = scalerd_x_data[train_end:]
print("-------------------------------normalized_train_data")
print(np.shape(normalized_train_data))
print("-------------------------------normalized_test_data")
print(np.shape(normalized_test_data))
train_x,train_y = [],[] #训练集x和y初定义
for i in range(len(normalized_train_data)-time_step):
if i % batch_size == 0:
batch_index.append(i)
x = normalized_train_data[i:i+time_step,:]
y = label_train[i:i+time_step]
train_x.append(x.tolist())
#train_x.append(x)
train_y.append(y.tolist())
#train_y.append(y)
batch_index.append(len(normalized_train_data)-time_step)
size = (len(normalized_test_data)+time_step-1)//time_step #有size个sample,//四舍五入
print("-------------------------------size")
print(size)
print("-------------------------------normalized_test_data")
print(tf.shape(normalized_test_data))
print(len(normalized_test_data))
print(normalized_test_data[0])
print(normalized_test_data[1])
test_x,test_y = [],[]
for i in range(size):
x = normalized_test_data[i*time_step:(i+1)*time_step,:]
y = label_test[i*time_step:(i+1)*time_step]
test_x.append(x.tolist())
test_y.extend(y.tolist())
print("-------------------------------x.tolist()")
print(len(x.tolist()))
#test_x.append((normalized_test_data[size*time_step:,:].tolist()))
#test_y.extend((label_test[size*time_step:].tolist()))
print("-------------------------------test_x")
print(len(test_x))
print(type(test_x))
print(test_x[0])
print(np.shape(test_x))
print(np.shape(train_x))
print(train_x[0])
#print((normalized_test_data[size*time_step:,:].tolist()))
return batch_index,train_x,train_y,test_x,test_y,scaler_for_y
#########################################################4、定义LSTM的网络结构
#----------定义神经网络变量-------------------
def lstm(x):
batch_size = tf.shape(x)[0]
time_step = tf.shape(x)[1]
w_in = weights['in']
b_in = biases['in']
input = tf.reshape(x,[-1,input_size]) #需要将tensor转成2维进行计算,计算后的结果作为隐藏层的输入
input_rnn = tf.matmul(input,w_in) + b_in
input_rnn = tf.reshape(input_rnn,[-1,time_step,rnn_unit]) #将tensor转成3维,作为lstm cell的输入
cell = tf.contrib.rnn.BasicLSTMCell(rnn_unit)
#cell=tf.contrib.rnn.core_rnn_cell.BasicLSTMCell(rnn_unit)
init_state=cell.zero_state(batch_size,dtype=tf.float32)
output_rnn,final_states=tf.nn.dynamic_rnn(cell, input_rnn,initial_state=init_state, dtype=tf.float32) #output_rnn是记录lstm每个输出节点的结果,final_states是最后一个cell的结果
output=tf.reshape(output_rnn,[-1,rnn_unit]) #作为输出层的输入
w_out=weights['out']
b_out=biases['out']
pred=tf.matmul(output,w_out)+b_out
print("================================output===========")
print(np.shape(output))
print("================================w_out===========")
print(np.shape(w_out))
print("================================b_out===========")
print(np.shape(b_out))
return pred,final_states
###############################################5、模型训练与预测
def train_lstm(batch_size=60,time_step=20,train_begnin=0,train_end=420):
x = tf.placeholder(tf.float32,shape=[None,time_step,input_size])
y = tf.placeholder(tf.float32,shape=[None,time_step,output_size])
batch_index,train_x,train_y,test_x,test_y,scaler_for_y = get_data(batch_size,time_step,train_begnin,train_end)
pred,_ = lstm(x)
print("================================pred")
print(np.shape(pred))
print("================================y")
print(np.shape(train_y))
#损失函数
loss = tf.reduce_mean(tf.square(tf.reshape(pred,[-1])-tf.reshape(y,[-1])))
train_op=tf.train.AdamOptimizer(lr).minimize(loss)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
#重复训练5000次
iter_time = 50
for i in range(iter_time):
for step in range(len(batch_index)-1):
_,loss_=sess.run([train_op,loss],feed_dict={x:train_x[batch_index[step]:batch_index[step+1]],y:train_y[batch_index[step]:batch_index[step+1]]})
# if i % 10 == 0:
# print('iter:',i,'loss:',loss_)
print(i)
####predict####
test_predict=[]
print("!!!!!!!!!!!!!!!!!!!!!!test_x")
print(np.shape(test_x))
for step in range(len(test_x)):
prob=sess.run(pred,feed_dict={x:[test_x[step]]})
print("================================prob")
print(np.shape(prob))
print(prob)
predict=prob.reshape((-1))
print("================================predict")
print(np.shape(predict))
print(predict)
test_predict.append(predict)
print("================================test_predict")
print(np.shape(test_predict))
test_predict = scaler_for_y.inverse_transform(test_predict)
print("================================test_predict")
print(np.shape(test_predict))
print(test_predict[0])
tt = [np.round(x) for x in test_predict[0]]
print(tt)
test_y = scaler_for_y.inverse_transform(test_y)
print("================================test_y")
print(np.shape(test_y))
###################统一格式
test_predict = np.reshape(test_predict,[-1,1])
#test_predict = [np.round(x) for x in test_predict]
print("================================test_predict")
print(np.shape(test_predict))
print("----------------------------------------------------------------")
print(test_predict[:20])
print("----------------------------------------------------------------")
print(test_y[:20])
rmse=np.sqrt(mean_squared_error(test_predict,test_y)) #方差是自己跟自己比,RMSE是预报跟观测比,基本可以理解为预报和观测之间的绝对距离
mae = mean_absolute_error(y_pred=test_predict,y_true=test_y)
print ('mae:',mae,' rmse:',rmse)
return test_predict
#################################6、调用train_lstm()函数,完成模型训练与预测的过程,并统计验证误差(mae和rmse)
test_predict = train_lstm(batch_size=60,time_step=20,train_begnin=0,train_end=420)
#################################7、画图分析
plt.figure(figsize=(24,8))
plt.plot(data[:, -1])
plt.plot([None for _ in range(450)] + [x for x in test_predict])
plt.show()huaqinglianhuaqinglianhuaqinglian
运行结果:
预测值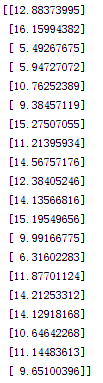 实际值
实际值 可以看出蛮准确的
可以看出蛮准确的
参考来源:https://blog.csdn.net/flying_sfeng/article/details/78852816
华青莲日常点滴,方便自己,成长他人!

