之前的博客讲了使用某种实验评估方法测得学习器的某个性能度量结果,但是怎么比较这些性能度量的结果呢?
统计假设检验为我们进行学习器性能的比较提供了重要依据。基于假设检验结果可以推断出:若在测试集上观察到学习器A比B好,则A的泛华能力是否在统计意义上优于B,以及这个结论的把握有多大。由于自己的统计学知识储备不够,还没有往深处理解假设检验的能力,因此,这里几乎不会涉及到公式,只有简单的理论。
假设检验中的假设是对学习器泛华错误率分布的某种判断或者猜想。现实中我们只能获取测试错误率,而不能获取真正的泛华错误率。但是直观上,二者接近的可能性应比大,相差很远的可能性会比较小,所以,可以根据测试错误率估推出泛华错误率的分布。
1.交叉验证t检验
对两个学习器A和B,如果使用K折交叉验证会得到很多测试错误率,可以使用成对t检验来进行比较检验。这里的思想是,若两个学习器的性能相同,则它们使用相同训练集/测试集得到的测试错误率应该相同。
2.McNemar检验(麦克尼马尔检验)也称配对资料检验法
对于二分类问题,使用留出法不仅可以估计学习器AB 的测试错误率,还可以获得两学习器分类结果的差别。如下边的表格: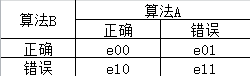 如果我们假设两学习器性能相同,则应该有e01=e10
如果我们假设两学习器性能相同,则应该有e01=e10
3.Friedman检验与Nemenyi后续检验
交叉验证t检验和McNemar检验都是在一个数据集上比较两个算法的性能,Friedman检验是在一组数据集上对多个算法进行比较,当有多个算法参与比较时,一种做法是在每个数据集上分别列出两两比较结果,两两比较可以使用前边的方法;另一种方法是使用基于算法排序的Friedman检验。当所有算法的性能相同这个假设被拒绝,则说明算法的性能显著不同,这时需要后续检验来进一步区分各算法。常用的有Nemenyi后续检验。具体见周志华《机器学习》44页。
4.偏差与方差
对学习算法除了通过实验估计其泛化性能,人们还希望了解它为什么具有这样的性能,偏差-方差分解就是这样一种方法。泛化误差可以理解为偏差、方差与噪声之和。偏差度量了学习算法的期望预测与真实结果的偏离程度,方差度量了同样大小的训练集的变动所导致的学习性能的变化,噪声则表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界。用于回归任务。
