作者:国服帅座 经济学在读硕士
公众号:统计之家
无论是爬取静态网页,还是利用高德地图API获得数据,本文作者都偏好使用requests模块。在本文中,本人爬取京东书评,运用的是Scrapy框架。
观察页面结构
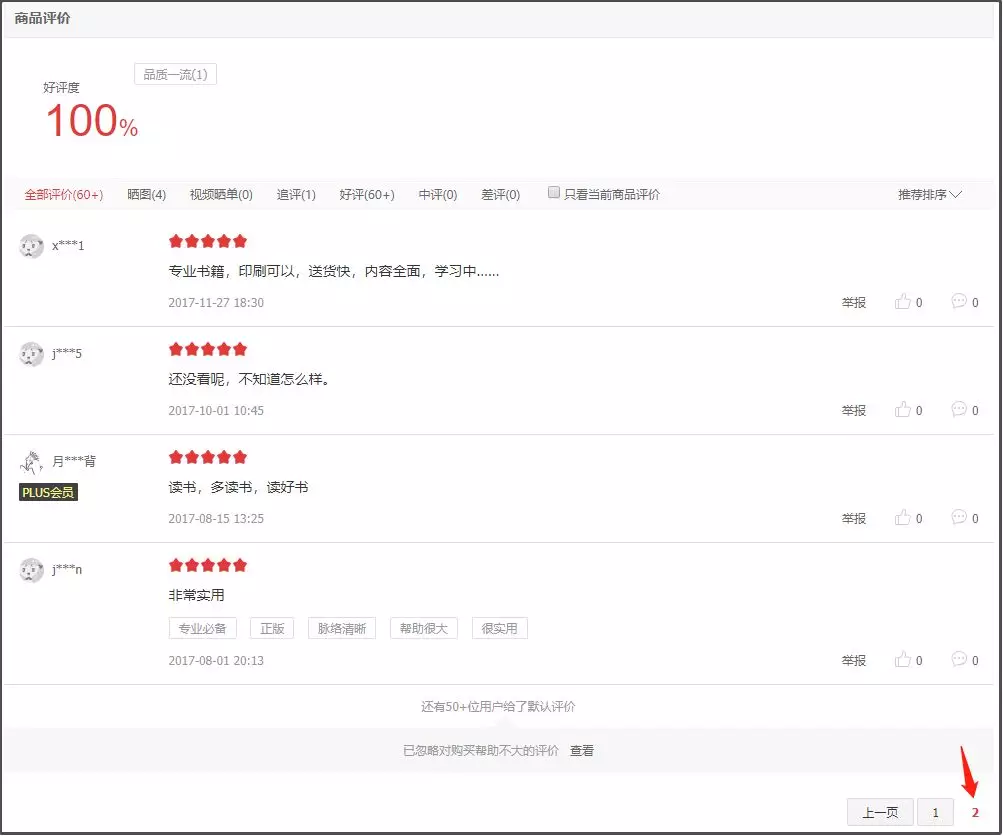
首先,在京东上搜索某书,以丘祐玮老师的《数据科学:R语言实现》为例,该书评价页面仅有2页,共计14条评论。
其次,在Chrome中右击“检查”,点击“Network“下的”JS”,寻找到“productPageComments”。

然后,双击该链接,观察页面发现,这是JSON字符串,在转化为Python字典前,需要先把大括号外面的多余字符串去除。

 爬取京东书评
爬取京东书评
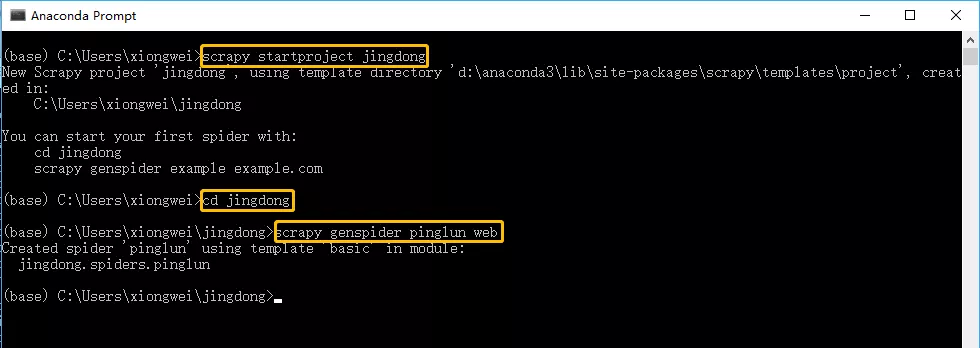
在命令提示符中输入以下代码,先创建一个目录(jingdong),然后进入该目录,在该目录的spiders目录中生成爬虫文件(pinglun.py)。
打开pinglun.py文件,输入以下代码:
# -*- coding: utf-8 -*-
import scrapy
import json
class PinglunSpider(scrapy.Spider):
name = 'pinglun'
allowed_domains = ['web']
start_urls = ['https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv27
&productId=12088321&score=0&sortType=5&page={}&pageSize=10&isShadowSku=0&fold=1'.format(i) for i in range(0,2)]
# 上步在page参数位置使用for循环,取值与评论页数有关
def parse(self, response):
jd = json.loads(response.text.lstrip('fetchJSON_comment98vv27(').rstrip(');'))
pinglun = jd['comments'] # 上步将JSON字符串转化为Python字典格式
for i in pinglun:
results = {}
results['content'] = i['content'] # 评论内容
results['time'] = i['creationTime'] # 评论时间
print (results)
接着,在命令提示符中输入以下命令:
获得结果如下,合计14条评论。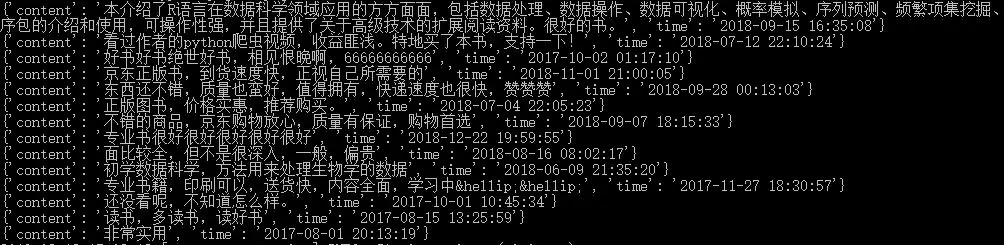

往期精彩传送
爬虫三步走——以R语言爬取经纬度为例
Python调用高德地图API爬取经纬度
Python调用百度地图API爬取经纬度
听说过高德版本的天气预报么
Python双Y轴可视化
这是一份【洗浴推拿指南】,敬请查收!
您是否知道,回家的路究竟有多长?
大年初六中午,全国各区县哪里最冷?


