/1 前言/
还在为在线看小视频缓存慢发愁吗?还在为想重新回味优秀作品但找不到资源而忧虑吗?莫要慌,让python来帮你解决,40行代码教你爬遍小视频网站,先批量下载后仔细观看,岂不美哉!
/2 整理思路/
这类网站一般大同小异,本文就以凤凰网新闻视频网站为例,采用倒推的方式,给大家介绍如何通过流量分析获得视频下载的url,进而批量下载。
/3 操作步骤/
/3.1 分析网站,找出网页变化规律/
1、首先找到网页,网页详情如下图所示。
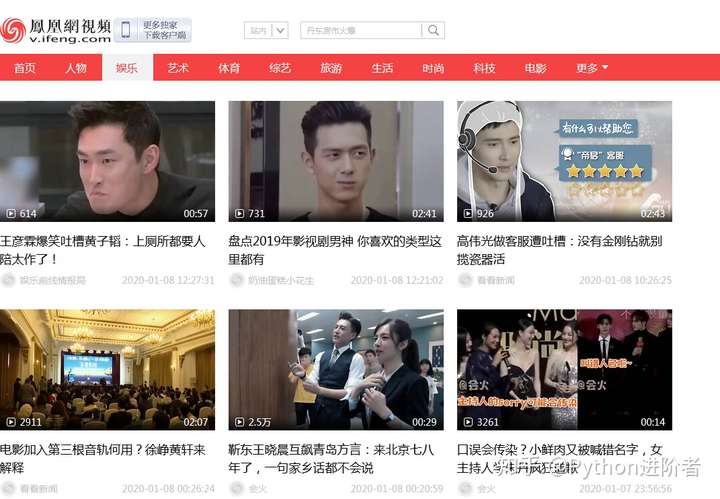
2、该视频网站分为人物、娱乐、艺术等不同类型,本文以体育版块为例,下拉到底端,如下图所示。
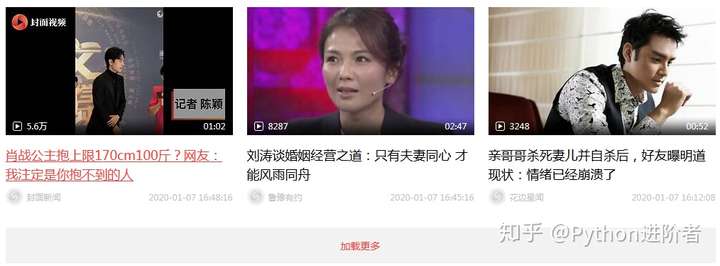
3、根据上图的结果,我们可以发现该网站是动态网页,打开浏览器自带流量分析器,点击加载更多,找出网页变化规律,第一个就是,请求网址和返回结果如下图。标记处为页码,此时是第3页。

4、返回结果包含视频的title、网页url、guid(相当于每个视频的标志,后续有用)等信息,如下图所示。

5、每个网页里边包含24个视频,打印出来是这样的,如下图所示。

/3.2 寻找视频网页地址规律/
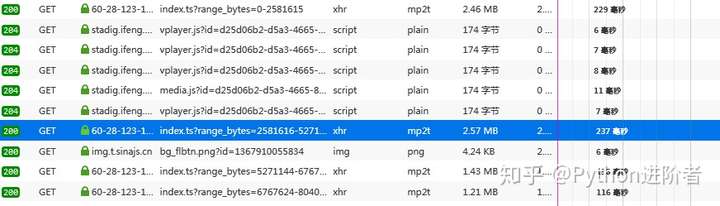
1、先打开流量分析器,播放视频进行抓包,找到几个mp2t文件,如下图所示。
2、它们的网址我依次找了出来,放到文本文件中存放起来,以发现它们之间的规律,如下图所示。
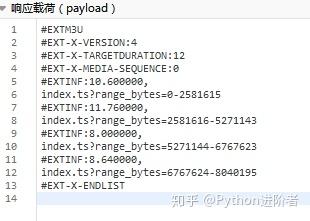
3、大家发现规律了吗?网址中的p26275262-102-9987636-172625参数就是视频的guid(上述已经得到),只有range_bytes参数是变化的,而且是从0到6767623,很显然这是视频的大小,而且视频是分段合成的。找到这些规律之后,接下来我们需要继续进行细挖视频地址的出处。
/3.3 寻找视频的下载原始地址/
1、先考虑一个问题,视频的地址是从哪来的呢?一般情况下,先在视频网页里看看有没有,如果没有,我们就在流量分析器里,沿着第一个分段视频往上找,肯定是有某个网址返回了这些信息,很快,我在1个vdn.apple.mpegurl文件里发现了下图这个。

2、太惊喜了,这不就是我们要找的信息么,再看看它的url参数,如下图所示。

3、上图参数看起来很多的样子,不过不用怕。还是利用老办法,先在网页里看看有没有,没有的话还在流量分析器里往上找,功夫不负有心人,我找到了下图这个。

4、它的url如下图所示。

5、仔细找找规律,我们发现唯一需要变化的就是每个视频的guid了,这个第一步已经得到了。另外,返回结果包含了上述除了vkey的所有参数,而且这个参数最长,那该怎么办呢?
6、不要慌,万一这个参数没有用呢,先把vkey去掉试一试。果不其然,果然没有什么用,现在整个过程已经捋顺了,现在可以撸代码了。
/3.4 代码实现/
1、在代码里边,设置多线程下载,如下图所示,其中页码可以自己进行修改哈。

2、解析返回参数,json格式的,使用json库进行处理,如下图所示。通过解析,我们可以得到每个视频的title、网页url、和guid。
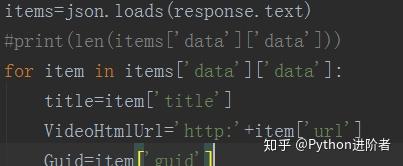
3、模拟请求,获得除Vkey外的参数,如下图所示。

4、利用上一步中的参数,进行模拟请求,获得包含分段视频的信息,如下图所示。

5、将分段视频合并,保存在1个视频文件,并以title命名,如下图所示。

/3.5 效果呈现/
1、当程序运行之后,我们便可以看到网页中的视频哗啦哗啦的在本地文件夹中进行呈现,如下图所示。接下来,妈妈再也不用担心我喜欢的视频找不着了,真香!
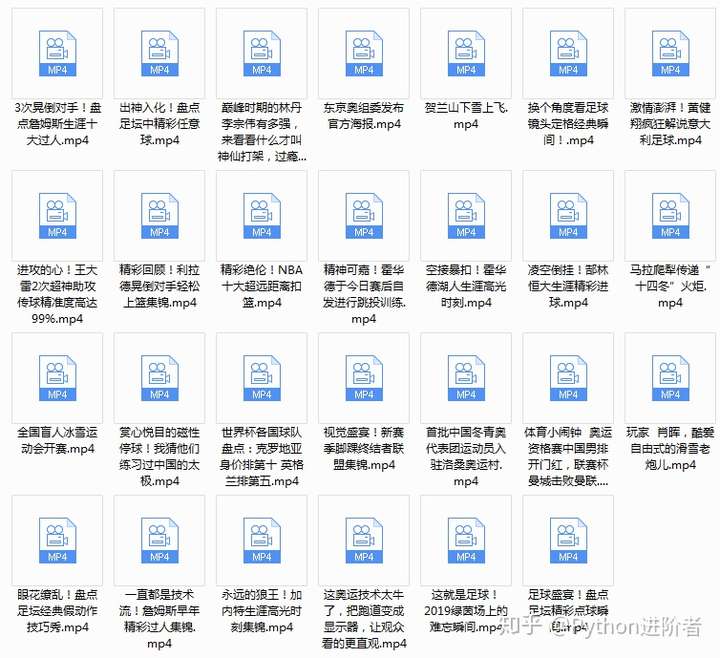
当然了,如果想更加直观的话,可以在代码中加入维测信息,这个大家可以自己手动设置一下。
/4 总结/
本文主要基于Python网络爬虫,利用40行代码,针对小视频网页,进行批量获取网页视频到本地。方法简单易行,而且行之有效,欢迎大家踊跃尝试。如果想获取本文代码,请zhi姐访问https://github.com/cassieeric/python_crawler/tree/master/little_video_crawler,即可获取代码链接,如果觉得不差,记得给个star噢。
