继续分享Python正则表达式的基础知识,今天给大家分享的特殊字符是[\u4E00-\u9FA5],这个特殊字符最好能够记下来,如果记不得的话通过百度也是可以一下子查到的。

该特殊字符是固定的写法,其代表的意思是汉字。换句话说,只要字符中是汉字,就可以通过该字符进行匹配,该特殊字符也是用中括号括起来的。具体的代码演示如下。
1、原始字符串是“加油”,两个汉字,然后将匹配模式直接为[\u4E00-\u9FA5],如下图所
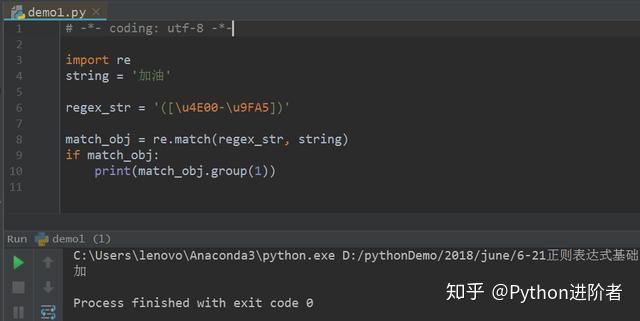
可以看到此时的输出结果仅仅出现了一个“加”字,因为该匹配模式默认是匹配一个字符。
2、如何想匹配多个字符,只需要在匹配模式后面加一个“+”号即可,表示匹配连续出现的汉字,如下图所示。
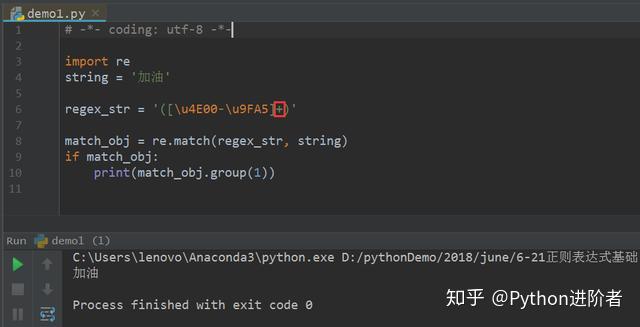
此时可以看到“加油”全都匹配出来了。
3、为了进一步加强对该特殊字符的理解,现在将“加油”两字中嵌入非汉字,如下图所示。
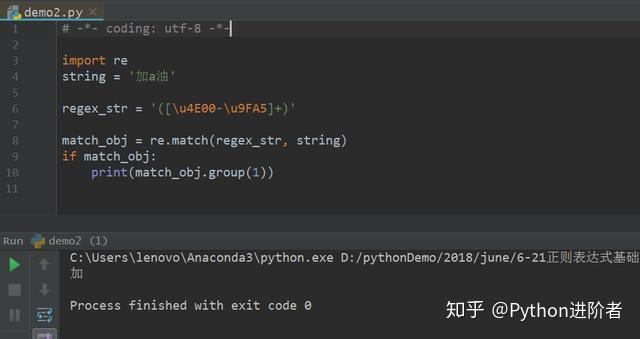
可以看到只匹配到了“加”,但是非汉字字符“a”及其以后的字符全部都匹配不到了,因为原始字符串并不是连续出现的汉字。
4、将非汉字字符放到字符串最后边,如下图所示。
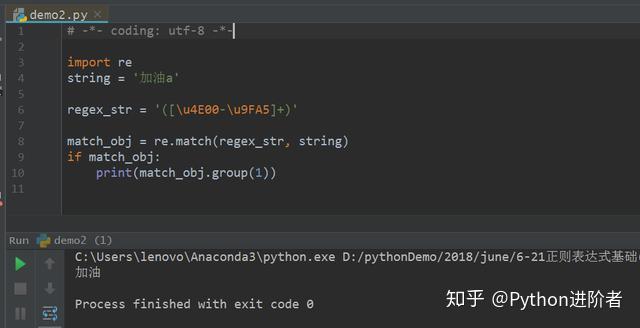
此时可以看到“加油”这两个连续的汉字可以成功匹配,但是非汉字字符匹配不到。
5、如果将“加油”中间加个空格,改为“加 油”,其他的保持不变,如下图所示。
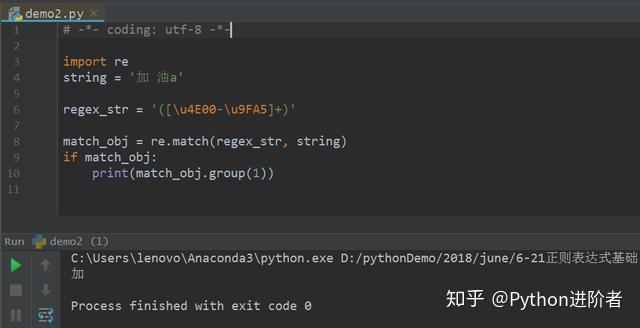
此时可以看到输出的结果仅仅是个“加”字,空格及其之后的字符都匹配不到,因为原始字符串并不是连续出现的汉字。
6、举个栗子,在实际应用中,往往会需要用到连续匹配汉字的地方。如现在有个需求,需要匹配字符串中的“XX”大学,如“清华大学”、“北京大学”、“中山大学”等,我们只知道字符“XX”是连续的中文,此时就可以用到本文介绍的汉字字符,如下图所示。
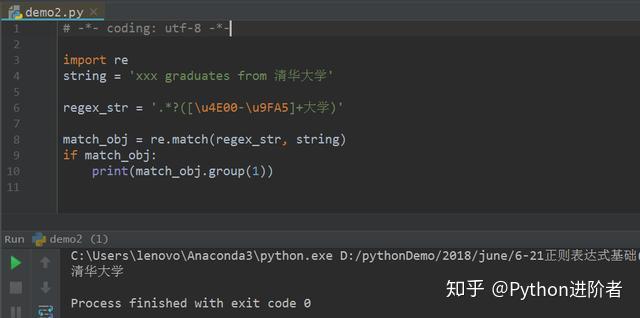
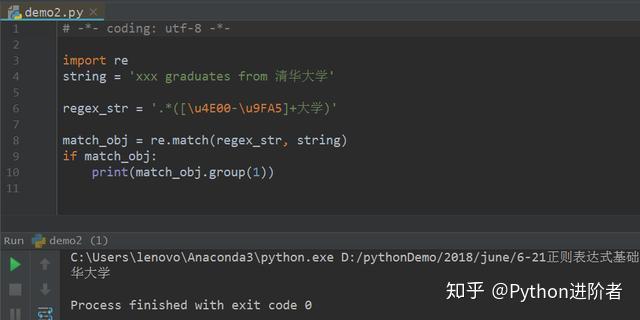
此时可以看到“清华大学”匹配成功。需要注意的是特殊字符“?”记得加上,代表非贪婪模式,如果不加这个字符的话,则匹配模式从字符的后面往前取,得到的结果仅仅为“华大学”,如下图所示。
7、同样的,如果要匹配“上海交通大学”,也是如此,如下图所示。
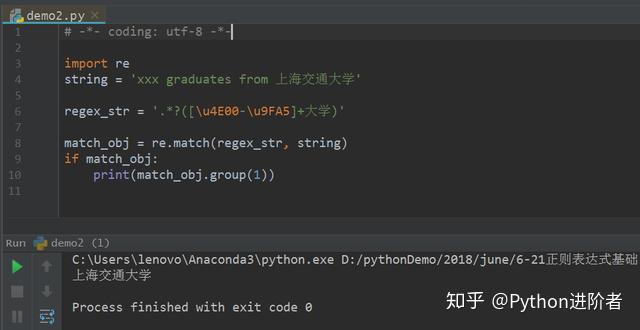
小伙伴们,关于汉字匹配字符,你们get到了么?
