文首声明:此文中的所有数据均为个人在14年初收集而来,不保证其有效性,请勿使用该数据进行商业活动。
再声明:这个模型是我两年前做的东西了,有一些细节可能因为记忆问题有错误,各位有看不懂的地方请直接问,我尽量解答。
上一篇我写了个建模的流程,有过建模经验的人自然懂,没有经验的各位也不要着急,这次我以一个真实模型为例,给大家详细讲述建模的各个步骤。
照例,先上流程图:
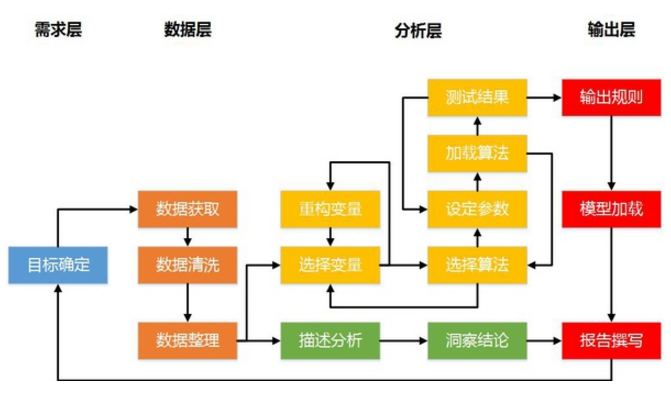
大家可以看到,这个图是由我之前文章中的两张图拼合而来,而我今天讲的这个真实模型,将把图中所有的流程都走一遍,保证一个步骤都不漏。
Step 0:项目背景
话说这个项目跟我加入百度有直接关系……
2013年的最后一天,我结束了在三亚的假期,准备坐飞机回家,这时候接到一个知乎私信,问我对百度的一个数据科学家(其实就是数据分析师啦)职位是否感兴趣,我立刻回信,定了元旦假期以后去面试。两轮面试过后,面试官——也是我加入百度后的直属Leader——打电话给我,说他们对我的经历很满意,但是需要我给他们一份能体现建模能力的报告。
按说这也不是一件难事,但我翻了翻电脑后发现一个问题:我从上家公司离职时,为了装13,一份跟建模相关的报告文件都没带……最后双方商定,我有一个星期时间来做一份报告,这份报告决定了我是否能加入百度。
那么,是时候展示我的技术了!我的回合,抽卡!
Step 1:目标确定
看看报告的要求:
数据最好是通过抓取得来,需要用到至少一种(除描述统计以外)的建模技术,最好有数据可视化的展示
看来是道开放题,那么自然要选择一个我比较熟悉的领域,因此我选择了……《二手主机游戏交易论坛用户行为分析》
为啥选这个呢?你们看了我那么多的Mario图,自然知道我会选主机游戏领域,但为什么是二手?这要说到我待在国企的最后半年,那时候我一个月忙三天,剩下基本没事干,因此泡在论坛上倒卖了一段时间的二手游戏……
咳咳……总之,目标就确定了:分析某二手主机游戏交易论坛上的帖子,从中得出其用户行为的描述,为用户进行分类,输出洞察报告。
Step 2:数据获取
简单来说,就是用python写了个定向爬虫,抓了某个著名游戏论坛的二手区所有的发帖信息,包括帖子内容、发帖人信息等,基本上就是长这个样子:
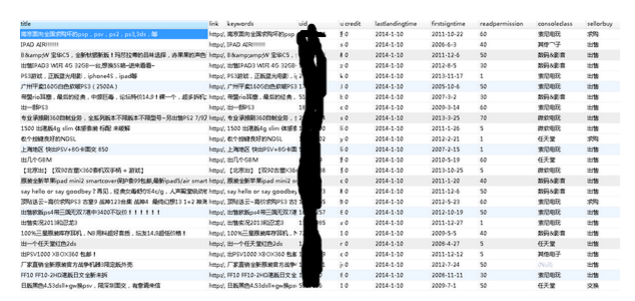
(打码方式比较简单粗暴,请凑合看吧……)
Step 3:数据清洗
这个模型中的数据清洗,主要是洗掉帖子中的无效信息,包括以下两类:
1、论坛由于其特殊性,很多人成交后会把帖子改成《已出》等标题,这一类数据需要删除:
2、有一部分人用直接贴图的方式放求购信息,这部分体现为只抓到图片链接,需要删除。
数据清洗结束了么?其实并没有,后边会再进行一轮清洗……不过到时再说。
Step 4:数据整理
用上面的那些帖子数据其实是跑不出啥结果的,我们需要把数据整理成可以进一步分析的格式。
首先,我们给每条帖子打标签,标签分为三类:行为类型(买 OR 卖 OR 换),目标厂商(微软 OR 索尼 OR 任天堂),目标对象(主机 OR 游戏软件)。打标签模式是”符合关键词—打相应标签“的方法,关键词表样例如下:
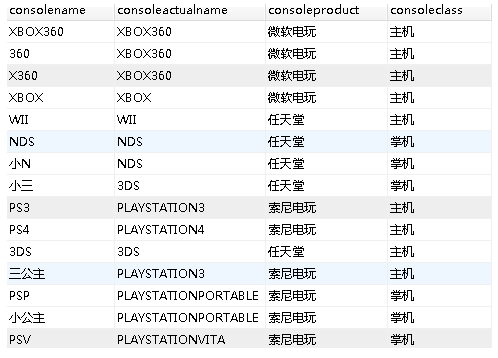
(主机掌机那个标签后来我在实际操作时没有使用)
打完标签之后,会发现有很多帖子没有打上标签,原因有两种:一是关键词没有涵盖所有的产品表述(比如三公主这种昵称),二是有一部分人发的帖子跟买卖游戏无关……

这让人怎么玩……第二次数据清洗开始,把这部分帖子也洗掉吧。
其次,我们用发帖用户作为视角,输出一份用户的统计表格,里边包含每个用户的发帖数、求购次数、出售次数、交换次数、每一类主机/游戏的行为次数等等,作为后续搭建用户分析模型之用。表格大概长这个样子:
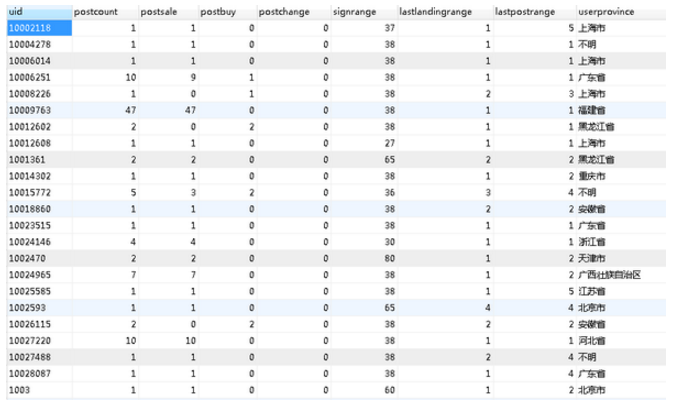
之后这个表的列数会越来越多,因为数据重构的工作都在此表中进行。
整理之后,我们准备进行描述统计。
Step 5 & 6:描述统计 & 洞察结论
描述统计在这个项目中的意义在于,描述这一社区的二手游戏及主机市场的基本情况,为后续用户模型的建立提供基础信息。
具体如何进行统计就不说了,直接放成品图,分别是从各主机市场份额、用户相互转化情况、地域分布情况进行的洞察。
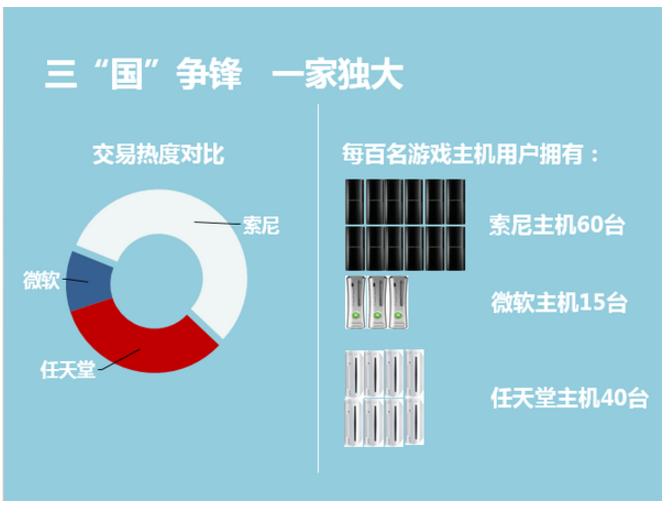
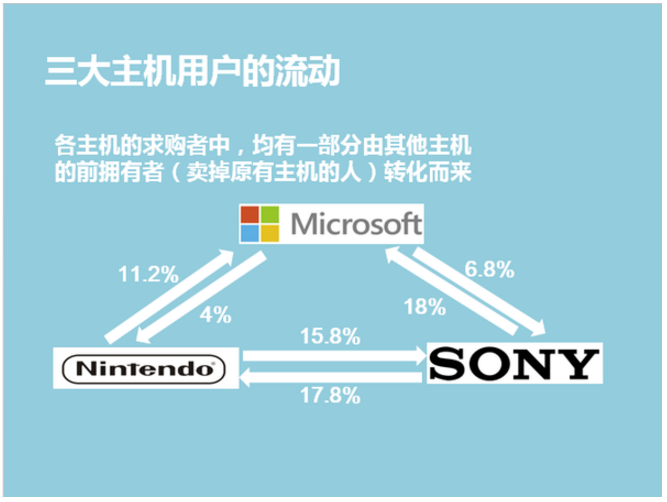
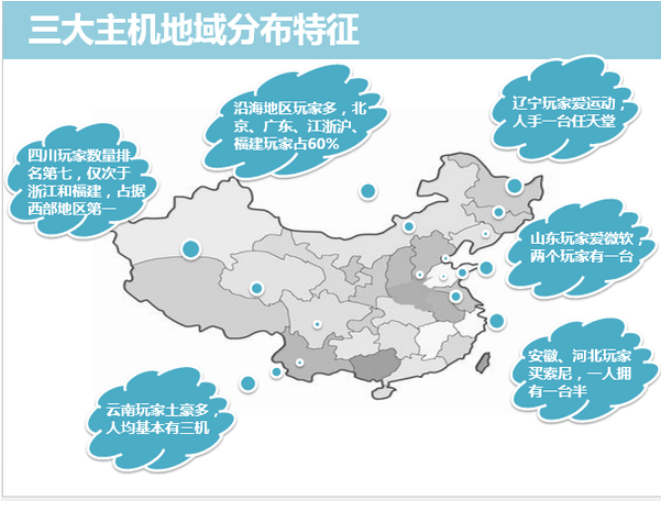
Step 7 & 8:选择变量 & 选择算法
因为我要研究的是这些用户与二手交易相关的行为,因此初步选择变量为发帖数量、微软主机拥有台数、索尼主机拥有台数、任天堂主机拥有台数。
算法上面,我们的目标是将用户分群,因此选择聚类,方法选择最简单的K-means算法。
Step 9 & 10:设定参数 & 加载算法
K-means算法除了输入变量以外,还需要设定聚类数,我们先拍脑袋聚个五类吧!
(别笑,实际操作中很多初始参数都是靠拍脑袋得来的,要通过结果来逐步优化)
看看结果:
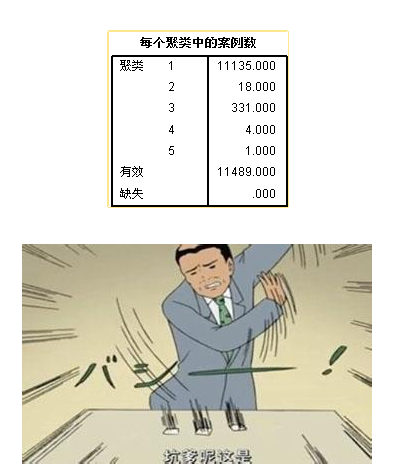
第一类别的用户数跟总体已经很接近了,完全没有区分度啊!
Step 7‘ & 8’ & 9‘ & 10’ & 11:选择变量 & 选择算法 &设定参数 & 加载算法 &重构变量
这一节你看标题都这么长……
既然我们用原始值来聚类的结果不太好,那么我把原始值重构成若干档次,比如发帖1-10的转换为1,10-50的转换为2,依次类推,再聚一次看看结果。
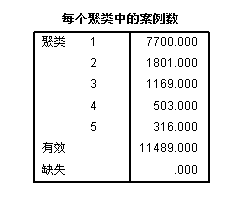
哦哦!看上去有那么点意思了!不过有一类的数量还是有一点少,我们聚成四类试试:
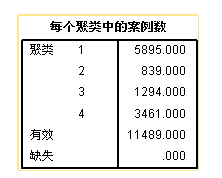
哦哦,完美! 我们运气不错,一次变量重构就输出了一个看上去还可以的模型结果,接下来去测试一下吧。
Step 12:结果测试
测试过程中,很重要的一步是要看模型的可解释性,如果可解释性较差,那么打回重做……
接下来,我们看看每一类的统计数据:
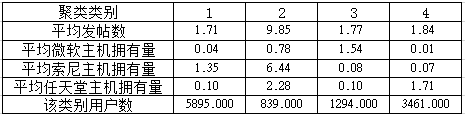
这个表出来以后,基本上可以对我们聚类结果中的每一类人群进行解读了。结果测试通过!
Step 13 & 14 & 15:输出规则 & 模型加载 & 报告撰写
这个模型不用回朔到系统中,因为仅仅是一个我们用来研究的模型而已。因此,输出规则和模型加载两步可以跳过,直接进入报告撰写。
聚类模型的结果可归结为下图:

眼熟不?在我的第二篇专栏文章第一份数据报告的诞生 - 一个数据分析师的自我修养 - 知乎专栏 中,我用这张图来说明了洞察结论的重要性,现在你们应该知道这张图是如何得来的了。
撰写报告的另外一部分,在描述统计-洞察结论的过程中已经提到了,把两部分放在一次,加上背景、研究方法等内容,就是完整的报告啦!
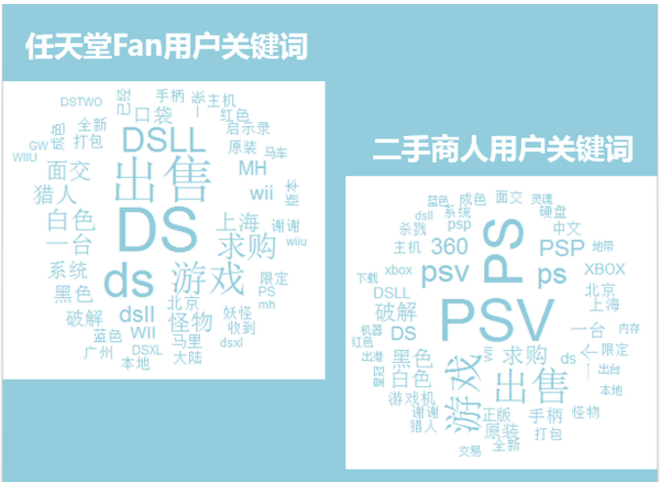
最后附送几张各类用户发帖内容中的关键词词云图:

那么,这篇文章就到此结束了,最后的最后,公布一下我做这份报告用到的工具:
大家可以看到,要当一个数据分析师,要用到很多类别的工具,多学一点总是没有坏处的,在此与大家共勉。




