为啥我作为一个数学能力并不强的人要在这献丑讲建模的事呢?其实我的目的很简单,就是为了告诉大家一个事实:数据分析中的建模,并没有想象中那么高深莫测,人人都有机会做出自己的模型。
一、从数据分析的定义开始
维基百科对数据分析的定义如下:
Analysis of data is a process of inspecting, cleaning, transforming, and modeling data with the goal of discovering useful information, suggesting conclusions, and supporting decision making. Data analysis has multiple facets and approaches, encompassing diverse techniques under a variety of names, in different business, science, and social science domains.
(来源:Data analysis)
简单翻译:数据分析是一个包含数据检验、数据清洗、数据重构,以及数据建模的过程,目的在于发现有用的信息,有建设性的结论,辅助决策的制定。数据分析有多种形式和方法,涵盖了多种技术,应用于商业、科学、社会学等多个不同的领域。
和上篇文章中我画的图对比一下:
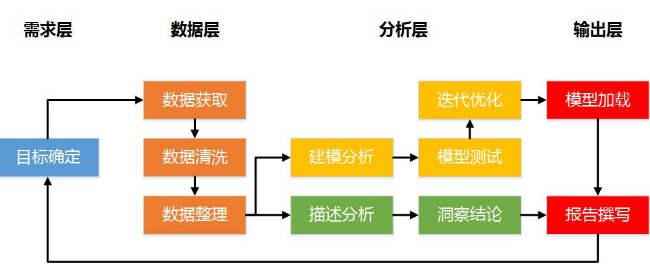
我在上篇文章中为了让初学者更容易走通全流程,简化了数据清洗的过程,实际上数据清洗绝非一次完成,“检验-清洗-检验”的过程可能会重复数次乃至数十次。
而建模呢?再次引用维基上对数据建模的定义:
Data modeling is a process used to define and analyze data requirements needed to support the business processes within the scope of corresponding information systems in organizations. Therefore, the process of data modeling involves professional data modelers working closely with business stakeholders, as well as potential users of the information system.(来源:Data modeling)
简单翻译:数据建模是一个用于定义和分析在组织的信息系统的范围内支持商业流程所需的数据要求的过程。因此,数据建模的过程需要专业建模师与商业人员和信息系统潜在用户的紧密合作。
这段话的定义更偏向信息系统和商业数据建模,我之所以在此引用这段话,是为了明确接下来的讨论内容主要方向是商业数据分析和建模,至于科学研究方向的数据建模,不在这篇文章的讨论范围以内。
请注意上边这段话中的一个核心:支持商业流程。商业数据建模,乃至商业数据分析,其最终目的都是要支持某种商业流程,要么优化原有流程,提高各部分效率;要么重构原有流程,减少步骤;要么告诉决策者,哪些流程改造方向是错误的,以避免走错路。最终的目标,一定是提升效率。但在不同的情况下,提升效率的方式也是不同的,因此在每个模型建立时,都需要确定其解决的具体目标问题。
再往前走一步,数学—主要是统计学,在建模的过程中又扮演什么样的角色呢?继续引用维基:
Mathematical formulas or models called algorithms may be applied to the data to identify relationships among the variables, such as correlation or causation. In general terms, models may be developed to evaluate a particular variable in the data based on other variable(s) in the data, with some residual error depending on model accuracy (i.e., Data = Model + Error)(来源:Data modeling)
简单翻译:数学公式或模型称为算法,可应用于数据以确定变量之间的关系,如相关性或因果关系。在一般情况下,模型开发出来后用于评估一个特定的变量与数据中其他其他变量的关系,根据模型的准确性不同,这些关系中会包含残差(即,数据=模型+错误)
这段描述很明确,统计学在数据建模的过程中,主要用于帮助我们找出变量之间的关系,并对这种关系进行定量的描述,输出可用于数据集的算法。一个好的数据模型,需要通过多次的测试和优化迭代来完成。
综上,给出一个我认为的“数据建模”定义:数据集+商业目标+算法+优化迭代= 数据建模。定义中的每一部分都必不可少。
二、数据模型的建立过程
照例,先上流程图:
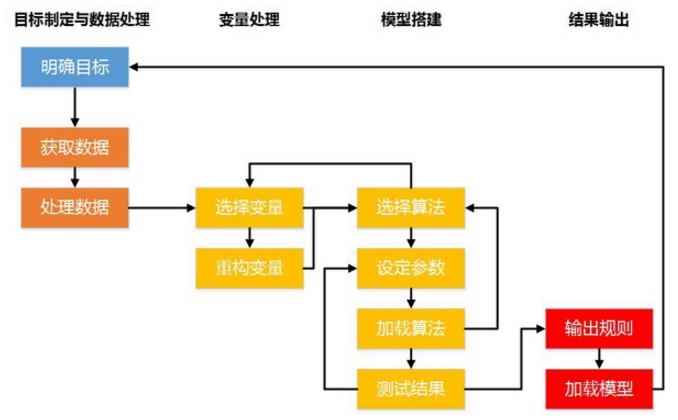
上图的流程颜色对应数据分析全流程,为了方便大家阅读,我把全流程图再贴一次:
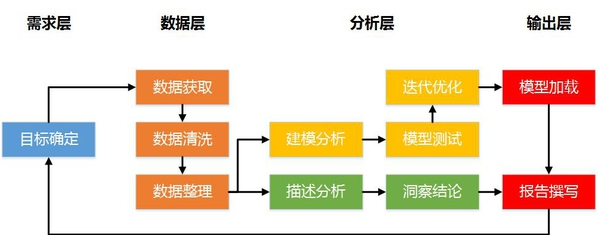
接下来,我重点解读明黄色(浅黄?)部分的内容:
在进行建模之前,首先要考虑的是使用哪些变量来建立模型,需要从业务逻辑和数据逻辑两个方面来考虑:
业务逻辑:变量基于收集到的数据,而数据在收集时,会产生与业务层面相关的逻辑,比如在汽车参数中,一旦我们定义了“家用轿车”这个类别,那么无论什么品牌什么车型,“轮胎数量(不计备胎)”这个变量就有99%以上几率为4……当然在接下来的建模中,我们不会选择这个变量。这一类情况是业务知识来告诉我们哪些变量可以选择,哪些不能选择。
数据逻辑:通常从数据的完整性、集中度、是否与其他变量强相关(甚至有因果关系)等角度来考虑,比如某个变量在业务上很有价值,但缺失率达到90%,或者一个非布尔值变量却集中于两个值,那么这个时候我们就要考虑,加入这个变量是否对后续分析有价值。
我个人认为,在选择变量时,业务逻辑应该优先于数据逻辑,盖因业务逻辑是从实际情况中自然产生,而建模的结果也要反馈到实际中去,因此选择变量时,业务逻辑重要程度相对更高。
而在变量本身不适合直接拿来建模时,例如调查问卷中的满意度,是汉字的“不满意”“一般”“满意”,那么需要将其重构成“1”(对应不满意)“2”(对应一般)“3”(对应满意)的数字形式,便于后续建模使用。
除这种重构方式之外,将变量进行单独计算(如取均值)和组合计算(如A*B)也是常用的重构方法。其他的重构方法还有很多种,在此不一一阐述。
我们在建模时,目标是解决商业问题,而不是为了建模而建模,故此我们需要选择适合的算法。常用建模算法包括相关、聚类、分类(决策树)、时间序列、回归、神经网络等。
以对消费者的建模为例,举一些场景下的常用算法对应:
划分消费者群体:聚类,分类;
购物篮分析:相关,聚类;
购买额预测:回归,时间序列;
满意度调查:回归,聚类,分类;
等等。
确定算法后,要再看一下变量是否满足算法要求,如果不满足,回到选择/重构变量,再来一遍吧。如果满足,进入下一步。
算法选定后,需要用数据分析工具进行建模。针对不同的模型,需要调整参数,例如聚类模型中的K-means算法,需要给出希望聚成的类别数量,更进一步需要给出的起始的聚类中心和迭代次数上限。
这些参数在后续测试中会经过多次调整,很少有一次测试成功的情况,因此请做好心理准备。
算法跑完之后,要根据算法的输出结果来确定该算法是否能够解决问题,比如K-means的结果不好,那么考虑换成系统聚类算法来解决。或者回归模型输出的结果不满足需求,考虑用时间序列来做。
如果不需要换算法,那么就测试一下算法输出的结果是否有提升空间,比如聚类算法中指定聚类结果包含4类人群,但发现其中的两类特征很接近,或者某一类人群没有明显特征,那么可以调整参数后再试。
在不断的调整参数,优化模型过程中,模型的解释能力和实用性会不断的提升。当你认为模型已经能够满足目标需求了,那就可以输出结果了。一个报告,一些规则,一段代码,都可能成为模型的输出。在输出之后,还有最后一步:接收业务人员的反馈,看看模型是否解决了他们的问题,如果没有,回到第一步,再来一次吧少年……
以上,就是建模的一般过程。如果你有些地方觉得比较生涩,难以理解,也没有关系。下一篇专栏中,我将向你们介绍一个具体的数据模型,我会对建模的过程一步步进行拆解,力求简明易懂。
