
1.命令行创建core
D:\soft\worksoft\solr-6.3.0>bin\solr.cmd create -c SparkHtmlPage //SparkHtmlPage是core名称
2.启动server后查看,可以通过web界面的Schema操作filed
3.managed-schema文件更改
3.1命令行产生之后,会在solr-6.3.0\server\solr生成SparkHtmlPagem目录,更改对应conf下面的managed-schema文件内容
3.2 managed-schema内容更改
<?xml version="1.0" encoding="UTF-8" ?>
<schema name="SparkHtmlPage" version="1.6">
<field name="_version_" type="long" indexed="false" stored="false"/>
<field name="_root_" type="string" indexed="true" stored="false" docValues="false" />
<field name="jobId" type="mmseg4j_simple" indexed="true" stored="true" required="true" multiValued="false" />
<field name="submitted" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="duration" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="stages" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="tasks" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="description" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="url" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<!-- 建立拷贝字段,将所有的全文本复制到一个字段中,进行统一的检索 -->
<field name="text" type="text_general" indexed="true" stored="false" multiValued="true" />
<!-- 拷贝需要的字段 -->
<copyField source="submitted" dest="text"/>
<copyField source="url" dest="text"/>
<uniqueKey>jobId</uniqueKey>
<!-- 中文IK分词 <fieldType name="text_ik_analyzer" positionIncrementGap="100" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.solr.IKTokenizerFactory"/>
<filter class="solr.StopFilterFactory" enablePositionIncrements="true" words="stopwords.txt" ignoreCase="true"/> <!-- 停用词 -->
<filter class="solr.WordDelimiterFilterFactory" splitOnCaseChange="1" catenateAll="0" catenateNumbers="1" catenateWords="1" generateNumberParts="1" generateWordParts="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPorterFilterFactory" protected="protwords.txt"/>
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.solr.IKTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" ignoreCase="true" expand="true" synonyms="synonyms.txt"/> <!-- 同义词 -->
<filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true"/>
<filter class="solr.WordDelimiterFilterFactory" splitOnCaseChange="1" catenateAll="0" catenateNumbers="0" catenateWords="0" generateNumberParts="1" generateWordParts="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPorterFilterFactory" protected="protwords.txt"/>
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
</fieldType>
-->
<!-- mmseg4j分词
<fieldType name="mmseg4j_complex" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" dicPath="dic"/>
</analyzer>
</fieldType>
<fieldType name="mmseg4j_max_word" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word" dicPath="dic"/>
</analyzer>
</fieldType>
-->
<fieldType name="mmseg4j_simple" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" dicPath="D:\soft\worksoft\solr-6.3.0\server\solr\SparkHtmlPage\dic"/>
</analyzer>
</fieldType>
</schema>
4.java bean代码编写
public class SparkHtmlPage {
@Field
private String jobId;
@Field
private String submitted;
@Field
private String duration;
@Field
private String stages;
@Field
private String tasks;
@Field
private String description;
@Field
private String url; //url
public SparkHtmlPage() {
}
...
}5. util编写
import java.util.List;
import java.util.Properties;
import org.apache.commons.lang.StringUtils;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.apache.solr.client.solrj.impl.XMLResponseParser;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class SolrUtil {
public static final Logger log = LoggerFactory.getLogger(SolrUtil.class);
private static final String FILENAME = Config.CONF_SPIDER_NAME;
private static final String URL = "solr.url";
private static HttpSolrClient client;
static{
Properties props = PropUtil.getProperties(FILENAME);
client = new HttpSolrClient.Builder(props.getProperty(URL)).build();
client.setParser(new XMLResponseParser());//设定xml文档解析器
client.setConnectionTimeout(10000);//socket read timeout
client.setAllowCompression(true);
client.setMaxTotalConnections(100);
client.setDefaultMaxConnectionsPerHost(100);
client.setFollowRedirects(true);
}
//创建索引
public static void addIndex(Object obj){
try {
client.addBean(obj);
client.optimize();
client.commit();
} catch (Exception e) {
// TODO Auto-generated catch block
log.info(" addIndex --> ",e);
e.printStackTrace();
}
}
//删除索引
public static void delIndex(){
try {
client.deleteByQuery("*:*");
client.commit();
} catch (Exception e) {
log.info(" delIndex --> ",e);
e.printStackTrace();
}
}
//查询
@SuppressWarnings("unchecked")
public static Object searchObj(String sname,String skey,Object obj) throws Exception {
SolrQuery params = new SolrQuery();
params.set("q", sname+":"+skey);
QueryResponse response = client.query(params);
List<Object> results = (List<Object>) response.getBeans(obj.getClass());
return results.get(0);
}
//列表查询
@SuppressWarnings("unchecked")
public static List<Object> search(String sname,String skey, int start, int range,
String sort,String field,Object obj) throws Exception {
SolrQuery params = new SolrQuery();
if (StringUtils.isNotBlank(skey)) {
params.set("q",sname+":"+skey);
} else {
params.set("q", "*:*");
}
params.set("start", "" + start);
params.set("rows", "" + range);
if(StringUtils.isNotBlank(sort)){
if(sort.equals("asc")){
params.setSort(field, SolrQuery.ORDER.asc);
}else{
params.setSort(field, SolrQuery.ORDER.desc);
}
}
QueryResponse response = client.query(params);
List<Object> results = (List<Object>) response.getBeans(obj.getClass());
return results;
}
//查询记录数
public static int getCount(String sname,String skey) {
int count = 0;
SolrQuery params = new SolrQuery();
if (StringUtils.isNotBlank(skey)) {
params.set("q", sname+":"+skey);
} else {
params.set("q", "*:*");
}
try {
QueryResponse response = client.query(params);
count = (int) response.getResults().getNumFound();
} catch (Exception e) {
// TODO Auto-generated catch block
log.info(" getCount --> ",e);
e.printStackTrace();
}
return count;
}
public static HttpSolrClient getClient() {
return client;
}
}
6. solr和hbase文档添加
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.paic.spider.entity.SparkHtmlPage;
import com.paic.spider.service.IStoreService;
import com.paic.spider.util.HbaseUtil;
import com.paic.spider.util.RedisUtil;
import com.paic.spider.util.SolrUtil;
public class HbaseStoreService implements IStoreService{
public static final Logger log = LoggerFactory.getLogger(HbaseStoreService.class);
public boolean save(SparkHtmlPage page) {
// TODO Auto-generated method stub
return false;
}
public boolean saveBatch(List<SparkHtmlPage> pages) {
boolean flag = false;
String regex = "(?<=\\()(.+?)(?=\\))"; //正则获取()内容
Pattern pattern = Pattern.compile(regex);
Matcher matcher;
String tableName = "sparkHtmlPage"; //定义常量方式
String rowKey;
String familyName = "info";
try {
for (SparkHtmlPage sparkHtmlPage : pages) {
matcher = pattern.matcher(sparkHtmlPage.getJobId());
if (matcher.find()) {
rowKey = matcher.group().trim();
//redis添加
RedisUtil.add("solr_rowkey_index", rowKey);
HbaseUtil.insert(tableName, rowKey, familyName,"jobId", sparkHtmlPage.getJobId());
HbaseUtil.insert(tableName, rowKey, familyName,"submitted", sparkHtmlPage.getSubmitted());
HbaseUtil.insert(tableName, rowKey, familyName,"duration", sparkHtmlPage.getDuration());
HbaseUtil.insert(tableName, rowKey, familyName,"tasks", sparkHtmlPage.getTasks());
HbaseUtil.insert(tableName, rowKey, familyName,"url", sparkHtmlPage.getUrl());
HbaseUtil.insert(tableName, rowKey, familyName,"description", sparkHtmlPage.getDescription());
HbaseUtil.insert(tableName, rowKey, familyName,"stages", sparkHtmlPage.getStages());
//solr添加
SolrUtil.addIndex(sparkHtmlPage);
}
}
flag = true;
} catch (Exception e) {
// TODO: handle exception
}
//关闭连接
HbaseUtil.close();
return flag;
}
}
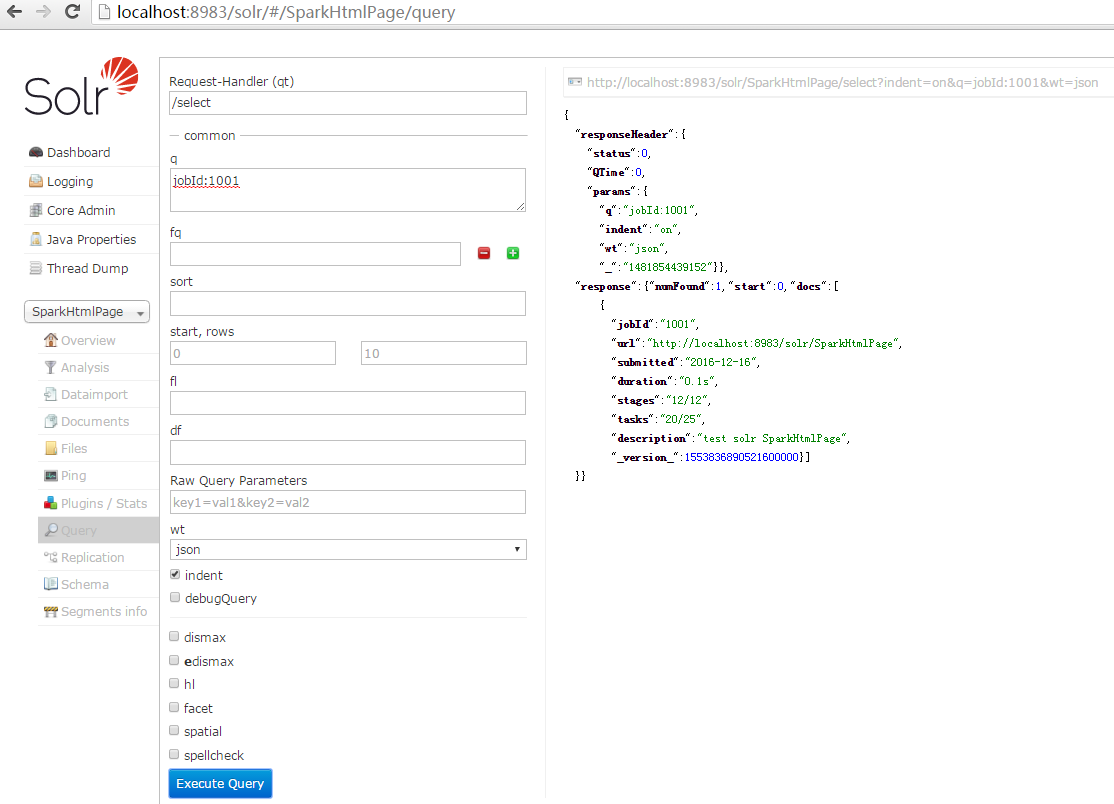
7.查询
@Test
public void runSolrList() throws SolrServerException, IOException{
try {
Object obj = SolrUtil.searchObj("jobId", "1001", new SparkHtmlPage());
System.out.println(obj);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
try {
List<Object> list = SolrUtil.search(null, null, 0, Integer.MAX_VALUE, "desc", "jobId", new SparkHtmlPage());
for (Object obj : list) {
System.out.println(obj);
}
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
8.web查询
异常1
org.apache.solr.client.solrj.impl.HttpSolrServer$RemoteSolrException: Expected mime type application/octet-stream but got text/html.
<title>Error 404 Not Found</title>
url地址错误,应该有core名称,如http://localhost:8983/solr/SparkHtmlPage
异常2
org.apache.solr.client.solrj.impl.HttpSolrClient$RemoteSolrException: Error from server at http://localhost:8983/solr/SparkHtmlPage: Expected mime type application/octet-stream but got text/html. <html>
<title>Error 500 Server Error</title>
Caused by: java.lang.AbstractMethodError: org.apache.lucene.analysis.util.TokenizerFactory.create(Lorg/apache/lucene/util/AttributeFactory;)Lorg/apache/lucene/analysis/Tokenizer;
mmseg4j分词错误,solr-6.3.0\contrib\analysis-extras\lucene-libs的lucene-analyzers-smartcn-6.3.0.jar到solr-6.3.0\server\solr-webapp\webapp\WEB-INF\lib,更改分词器为
<!-- solr自带的smartcn分词器 -->
<fieldType name="text_smart" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.SmartChineseSentenceTokenizerFactory"/>
<filter class="solr.SmartChineseWordTokenFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.SmartChineseSentenceTokenizerFactory"/>
<filter class="solr.SmartChineseWordTokenFilterFactory"/>
</analyzer>
</fieldType>
说明:在最新的lucene-analyzers-smartcn6.x版本jar包中缺少SmartChinese开头的类,可以使用5.x版本的jar包。
本站文章版权归原作者及原出处所有 。内容为作者个人观点, 并不代表本站赞同其观点和对其真实性负责。本站是一个个人学习交流的平台,并不用于任何商业目的,如果有任何问题,请及时联系我们,我们将根据著作权人的要求,立即更正或者删除有关内容。本站拥有对此声明的最终解释权。