
作者:凡人求索
來源:简书
转载自:Python数据科学
众所周知,统计学是数据分析的基石。学了统计学,你会发现很多时候的分析并不那么准确,比如很多人都喜欢用平均数去分析一个事物的结果,但是这往往是粗糙的。而统计学可以帮助我们以更科学的角度看待数据,逐步接近这个数据背后的“真相”。 大部分的数据分析,都会用到统计方面的以下知识,可以重点学习:
阅读路线:
概率介绍
离散型概率分布和连续型概率分布
抽样和抽样分布
区间估计
假设检验
01 概率介绍
概率是指的对于某一个特定事件的可能性的数值度量,且在0-1之间。我们抛一枚硬币,它有正面朝上和反面朝上两种结果,通常用样本空间S表示,S={正面,反面},而正面朝上这一特定的试验结果叫样本点。对于样本空间少的试验,我们极易观察出他们样本空间的大小,而对于较复杂的试验,我们就需要学习些计数法则了。
计数法则
如果一个试验可以分为循序的k个步骤,在第1步中有N1种试验结果,在第2步中有N2种试验结果...以此类推。那么所有的试验结果的总数为N1*N2*N3...*Nk。
举例:抛两枚硬币,第一枚有正反两种结果,第二枚有正反两种结果。所以试验结果的总数是 2X2=4
从N项中任取n项的组合数

N和n的上下位置与我们平常见的是相反的。因为我们这里是以欧美规范为主。
举例子:从5个彩色球中,选出2个彩球,有多少种选法?
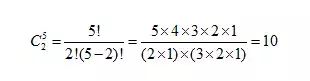
从N项中任取n项的排列数
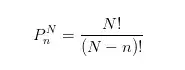
举例子:从5个彩色球中,选出2个彩球,有多少种排列方法?
代入得出答案是20种
事件及其概率
其实事件为样本空间的一个子集,通常,如果能确定一个试验的所有样本点并且能够知晓每个样本点的概率,那么我们就能求出事件的概率。
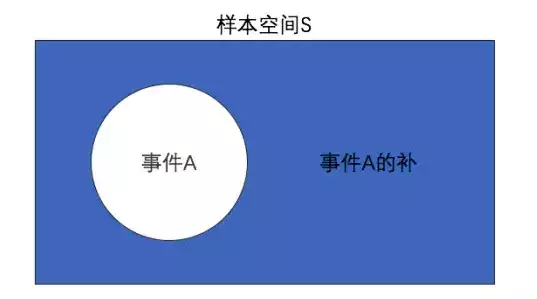
事件A的补:指的是所有不包含在事件A中的样本点所以事件A发生的
概率 P(A)=1-P(A-)
事件的组合:并和交
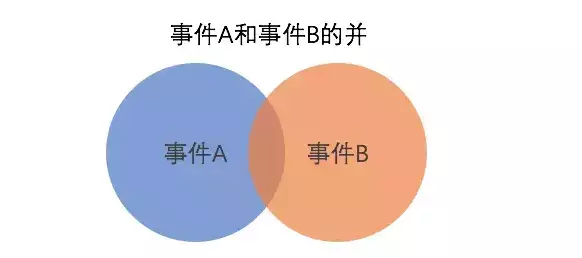
两个圆形区域所在的部分就是事件A和B的并,其中重叠的部分说明有一些样本点即属于A又属于B,它可以称之为交。
得出加法公式为:
P(A∪B) = P(A)+P(B) – P(A∩B)。P(A∪B) 是两个圆形面积,P(A)是蓝色圆面积,P(B)是橙色圆面积,当两者相加时,会多出一块重叠区域,于是减去P(A∩B)进行修正,得出正确的结果。
如果某个事件A发生的可能性受到另外一个事件B的影响,此时A发生的可能性叫做条件概率,记作P(A|B)。表明我们是在B条件已经发生的条件下考虑A发生的可能性,统计学中称为给定条件B下事件A的概率。
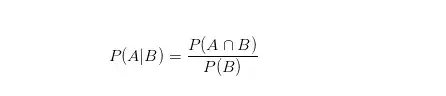
进而又得出了乘法公式:
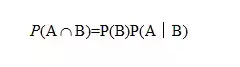
简单的来讲,贝叶斯定理其实就是,我们先假设一个事件发生的概率,然后又找到一个信息,最后得出在这个信息下这一事件发生的概率。
举一个我们生活中的例子,当我们和一个被怀疑做坏事的人聊天时,我们首先假设他做坏事的概率为a,然后我们根据和他交谈的信息,得出对他新的认识,重新判断他做坏事的概率b.
贝叶斯就是阐述了这么一个事实:
新信息出现后B的概率=B的概率 X 新信息带来的调整
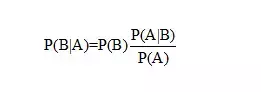
如果当直接计算P(A)较为困难时,而P(Bj),P(A|Bj) (j=1,2,...)的计算较为简单时,可以利用全概率公式计算P(A)。
思想就是,将事件A分解成几个小事件,通过求小事件的概率,然后相加从而求得事件A的概率,而将事件A进行分割的时候,不是直接对A进行分割,而是先找到样本空间Ω的一个个划分B1,B2,...Bn,这样事件A就被事件AB1,AB2,...ABn分解成了n部分,即A=AB1+AB2+...+ABn, 每一Bj发生都可能导致A发生相应的概率是P(A|Bj),由加法公式得
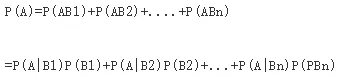
所以调整后的贝叶斯公式为:
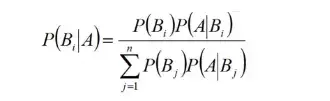
02 离散型概率分布和连续型概率分布
概率中通常将试验的结果称为随机变量。随机变量将每一个可能出现的试验结果赋予了一个数值,包含离散型随机变量和连续型随机变量。
既然随机变量可以取不同的值,统计学家就用概率分布描述随机变量取不同值的概率。相对应的,有离散型概率分布和连续型概率分布。
数学期望和方差
数学期望是对随机变量中心位置的一种度量。是试验中每次可能结果乘以其结果的概率的总和。简单说,它是概率中的平均值。
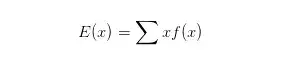
方差随机变量的变异性或者是分散程度的度量。
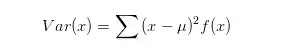
其中的u就是E(x).
离散型概率分布
二项分布是一种离散型的概率分布。故明思义,二项代表它有两种可能的结果,把一种称为成功,另外一种称为失败。
除了结果的规定,它还需要满足其他性质:每次试验成功的概率均是相同的,记录为p;失败的概率也相同,为1-p。每次试验必须相互独立,该试验也叫做伯努利试验,重复n次即二项概率。掷硬币就是一个典型的二项分布。当我们要计算抛硬币n次,恰巧有x次正面朝上的概率,可以使用二项分布的公式:
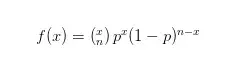
且二项概率的数学期望为E(x) = np,方差Var(x) = np(1-p)。
泊松概率是另外一个常用的离散型随机变量,它主要用于估计某事件在特定时间或空间中发生的次数。比如一天内中奖的个数,一个月内某机器损坏的次数等。
泊松概率的成立条件是在任意两个长度相等的区间中,时间发生的概率是相同的,并且事件是否发生都是相互独立的。
泊松概率既然表示事件在一个区间发生的次数,这里的次数就不会有上限,x取值可以无限大,只是可能性无限接近0,f(x)的最终值很小。
x代表发生x次,u代表发生次数的数学期望,概率函数为:

其中泊松概率分布的数学期望和方差是相等的。
连续型概率分布
上述分布都是离散概率分布,当随机变量是连续型时,情况就完全不一样了。因为离散概率的本质是求x取某个特定值的概率,而连续随机变量不行,它的取值是可以无限分割的,它取某个值时概率近似于0。连续变量是随机变量在某个区间内取值的概率,此时的概率函数叫做概率密度函数。
随机变量x在任意两个子区间的概率是相同的。
均匀概率密度函数
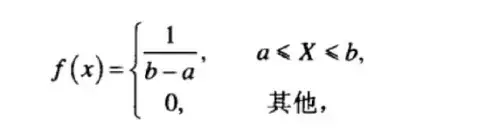
数学期望
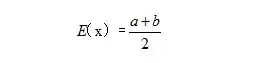
方差
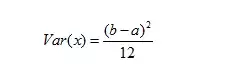
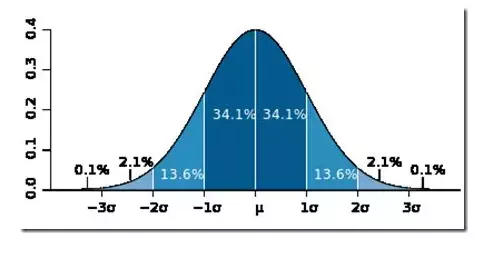
正态概率分布是连续型随机变量中最重要的分布。世界上绝大部分的分布都属于正态分布,人的身高体重、考试成绩、降雨量等都近似服从。
正态分布如同一条钟形曲线。中间高,两边低,左右对称。想象身高体重、考试成绩,是否都呈现这一类分布态势:大部分数据集中在某处,小部分往两端倾斜。
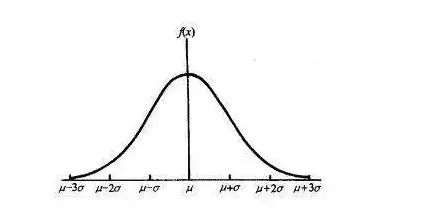
正态概率密度函数为:
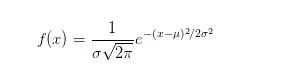
u代表均值,σ代表标准差,两者不同的取值将会造成不同形状的正态分布。均值表示正态分布的左右偏移,标准差决定曲线的宽度和平坦,标准差越大曲线越平坦。
一个正态分布的经验法则:
正态随机变量有69.3%的值在均值加减一个标准差的范围内,95.4%的值在两个标准差内,99.7%的值在三个标准差内。
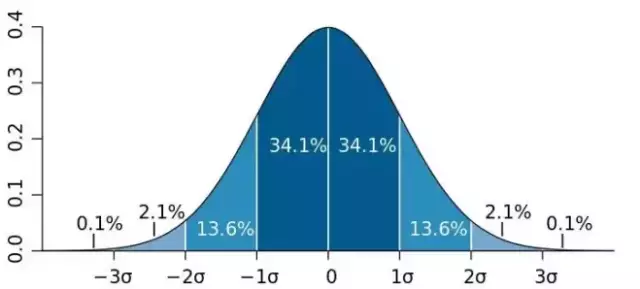
均值u=0,标准差σ=1的正态分布叫做标准正态分布。它的随机变量用z表示,将均值和标准差代入正态概率密度函数,得到一个简化的公式:
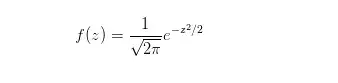
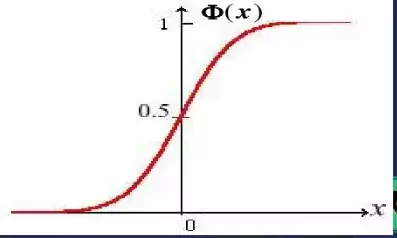
为了计算概率需要学习一个新的函数叫累计分布函数,它是概率密度函数的积分。用P(X<=x)表示随机变量小于或者等于某个数值的概率,F(x) = P(X<=x)。
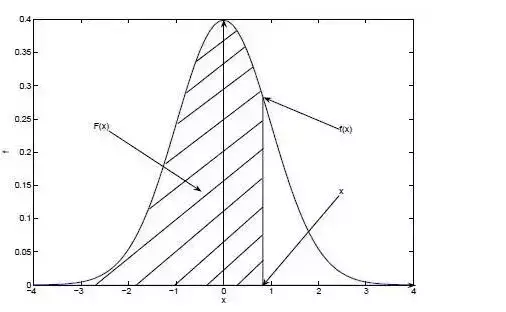
曲线f(x)就是概率密度函数,曲线与X轴相交的阴影面积就是累计分布函数。
标准正态分布的分布函数
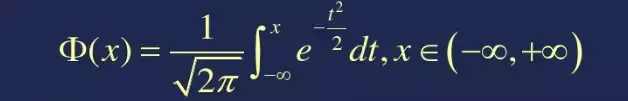
图像如下:
计算三种类型的概率(这里需要说明一点,只有标准正态分布时,随机变量才用z表示)
1. z小于或者等于某个给定值的概率,直接带入分布函数得出
如:p(z<=1)=φ(1)=0.8413 (1值左边标准正态曲线下的面积)
2. z在给定的两个值之间的概率
如:P(-1<=z<=1.25) = P(z<=1.25) – P(z<=-1) =φ(1.25)-φ(1) =0.735
3. z大于或者等于某个给定值的概率
如:P(z>1) = 1-P(z<=1) =1-φ(1)= 0.1586
标准正态分布与一般的正态分布的关系:
任何一个一般的正态分布都可以通过线性变换转化为标准正态分布。它依据的定理如下:

下面做一道题目练习吧!
现在有一个u=10和σ=2的正态随机变量,求x在10与14之间的概率是多少?
当x=10时,z=(10-10)/2=2。当x=14时,z=(14-10)/2=2。于是x在10和14之间的概率等价于标准正态分布中0和2之间的概率。计算P(0<=z<=2) =P(z<=2) – P(z<=0) =0.4772。
指数概率密度函数
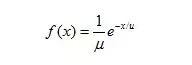
其中,x>=0,u为均值,e=2.71828;
计算概率
指数随机变量取小于或者等于某一特定值X0的概率
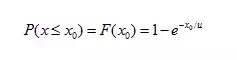
且指数概率分布的期望=标准差
泊松分布:1.是离散型概率分布 2.描述每一区间中事件发生的次数
指数分布:1.是连续型概率分布 2.描述事件发生的时间间隔的长度
为了说明问题,简单举两个小例子
a.20分钟内购买肯德基早餐的人数的均值是10人,那么如果求每20分钟有x人购买的概率,就应该用泊松概率函数
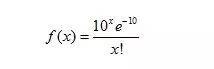
b.20分钟内购买肯德基早餐的人数的均值是10人,那么如果求每20分钟这一区间内,两位顾客购买的时间间隔为小于x0的概率,就应该用指数概率函数。
购买的间隔均值为u=10/20=0.5
把u带入下面的公式
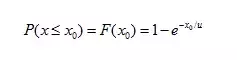
03 抽样和抽样分布
首先不管是从有限总体中抽样还是从无限总体中抽样都应该满足抽样的随机性。
抽样
我们抽样得出样本统计量就是为了估计总体的参数
样本均值(x拔)是总体均值的u的点估计
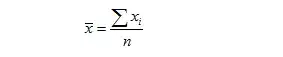
样本标准差s是总体的标准差σ的点估计
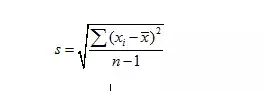
样本比率(p拔)是总体比率的p的点估计
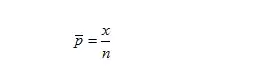
抽样分布
其实当我们抽样的时候,我们抽取的每个样本的均值、方差、比率,可能都是不同的,如果我们把抽取一个简单的随机样本看作一次试验,那么(x拔)就有期望、方差、标准差和概率分布了((x拔)的概率分布也就是(x拔)的抽样分布)
(x拔)的抽样:样本均值(x拔)的所有可能值的概率分布
(x拔)的数学期望:
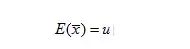
其中u是总体的期望
(x拔)的标准差
当样本容量占总体5%以上时,有求样本标准差公式如下:
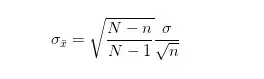
当样本容量占总体5%以下时,公式可以简化成:
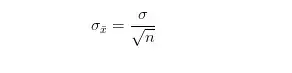
其中n是样本容量,N是总体容量,σ是总体标准差,σ(x拔)是样本标准差
重点来了:
1. 如果总体服从正态分布时:任何样本容量下的(x拔)的抽样分布都是正态分布。
2. 总体不服从正态分布时:
a.中心极限定理:从总体中抽取容量为n的简单随机样本,当样本的容量额很大时,样本均值(x拔)的抽样分布近似服从正态概率分布。
b.其实在大多数的应用中,样本容量大于30时,(x拔)的抽样分布近似服 从正态概率分布
(p拔)的抽样:样本比率(p拔)的所有可能值的概率分布

其中:x=具有感兴趣特征的个体的个数,n=样本容量
(p拔)的数学期望:
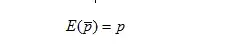
其中,p=总体比率
(p拔)的标准差:
当样本容量占总体5%以上时,有求样本标准差公式如下:
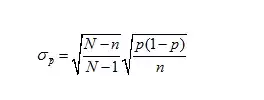
当样本容量占总体5%以下时,公式可以简化成:
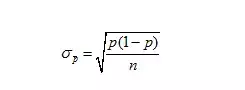
其中n是样本容量,N是总体容量,p是总体比率,σ(p拔)是样本标准差
(p拔)的抽样分布形态:
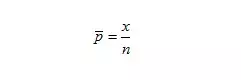
在上面的公式之中,x是一个服从二项分布的随机变量,n为常数,所以(p拔)也是离散型的概率分布。其实,如果样本容量足够大,并且np>=5和n(1-p)>=5,二项分布可用正态分布近似,(p拔)的抽样分布可用正态分布来近似。
04 区间估计
点估计是用于估计总体参数的样本统计量,但是我们不可能通过点估计就给出总体参数的一个精确值,更稳妥的方法是加减一个边际误差,通过一个区间值来估计(区间估计)
总体均值的区间的估计
对总体均值进行估计时:
1. 要利用总体标准差σ计算边际误差
2. 抽样前可通过大量历史数据估计总体标准差。
下面做一道例题感受下吧
这是一道有关顾客购物消费额的问题,根据历史数据,σ=20美元,并且总体服正态分布。现在抽取n=100名顾客的简单随机样本,其样本均值(x拔)=82美元。求总体均值的区间估计
开始解答了:
1. 总体服从正态分布,所以样本均值的抽样分布也是正态分布。
2. 根据σ=20美元,得出
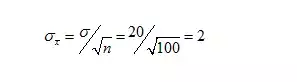
3. 所以x拔的抽样分布服从标准差为σ(x拔)=2的正态分布
4. 任何正态分布的随机变量都有95%的值在均值附近加减1.96个标准差以内(通过查表可得)
5. σ(x拔)=2,(x拔)所有值的95%都落在【u加减1.96σ(x拔)也即是u加减3.92】
也即是:
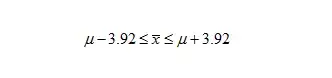
(x拔)=82美元


所以u的区间估计是(78.08,85.92)
其中这个区间是在95%置信水平下建立的,置信系数为0.05。区间(78.08,85.92)为95%的置信区间。
根据公式来计算区间,边际误差、区间估计如下图所示:

所以:
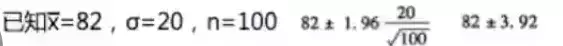
在90%,95%,99%的置信水平情况下:
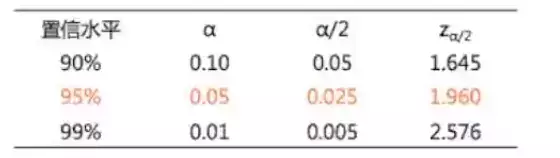
所以90%,99%的置信水平下的置信区间为:

其实我们也能得出这样的结论:想要达到的置信水平越高,边际误差就要越大,置信区间也是越宽。
1. 当σ未知时,我们需要利用同一个样本估计u和σ两个参数
2. 用s估计σ时,边际误差和总体均值的区间估计依据t分布
并且总体是不是正态分布用t分布来估计效果都是挺好的。
t分布
有一类相似的概率分布组成的分布族;某个特定的t分布依赖于自由度的参数;自由度越大,t分布与标准正态分布的差别越小;t分布的均值为0;
其中与z分布有类似的情况的是:
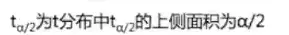
例如:

利用的计算公式如下:
边际误差:
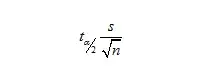
区间估计
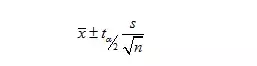
样本标准差
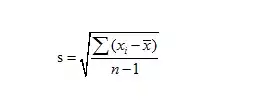
自由度:n-1
注:

我们可以选择足够的样本容量以达到所希望的边际误差
由于边际误差公式为:

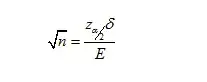
所以总体均值区间估计中的样本容量为:
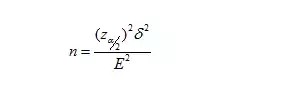
注:

如果σ未知,可通过以下方法确定σ的初始值
1. 根据以前研究中的数据计算总体标准差的估计值
2. 利用实验性研究,选取一个初始样本,以初始样本的标准差做估计值
3. 对σ进行判断或最优猜测:计算极差/4为标准差的粗略估计
总体比率p的区间估计
由于和总体均值的区间估计类似,这里就不详细说明了,直接上公式:
边际误差:
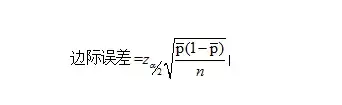
区间估计:
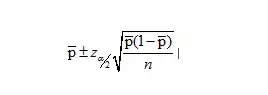
我们可以选择足够的样本容量以达到所希望的边际误差
边际误差:
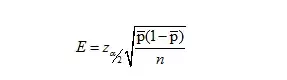
所以样本容量为:
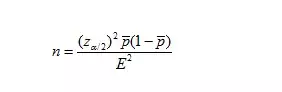
由于抽样前(p拔)是未知的,不能用于计算达到预期的边际误差所要的样本容量,因此令(p星)表示(p拔)的计划值

p星的确定
1. 用以前研究中类似的样本的样本比率作为计划值
2. 利用实验性的研究,选取一个初始样本,以初始样本的样本比例作为计划值。
3. 使用判断或最优猜测作为计划值
4. 如果上述均不可,计划值取为0.5,这是因为p(星)=0.5时,p星*(1-p星)取得最大值,同时样本容量也能取的最大值。
05 假设检验
何为假设检验?假设检验是对总体参数做一个尝试性的假设,该尝试性的假设称为原假设,然后定义一个和原假设完全对立的假设叫做备选假设。其中备选假设是我们希望成立的论断,原假设是我们不希望成立的论断。
假设检验涉及讨论的内容有:
1. 总体均值的检验:σ已知和σ未知情形
2. 总体比率的假设检验:σ已知和σ未知道
但是下面主要讨论在σ已知情形下,总体均值的检验,其他的根据区间估计中的证明和下面的例题都能很方便的理解出来。
总体均值的检验:
准备一道例题,通过例子说明思路
质检机构检查某品牌咖啡的标签上显示装有3磅咖啡,现在质检机构需要确定每罐咖啡的质量至少有三磅,以保证消费者权益。已知道σ=0.18,现在取得n=36罐咖啡组成一个随机样本,计算出(x拔)=2.92
开始解答了:
1. 首先我们明白想要的结果是证明u<3,所以就提出了原假设和备选假设如下:H0:u>=3;Ha:u<3
2. 其中我们在检验的过程允许以1%的可能性犯错误也即是 α=0.01
3. 由于样本n=36,σ=0.18,所本均值的抽样分布是服从正态概率分布
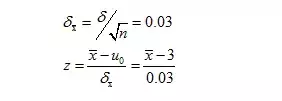
4. 所以当(x拔)=2.92时,z=-2.67
5. 因为原假设u是大于等于3的,所以我们就观察z小于或等于-2.69的值,让p值等于检验统计值z小于或等于-2.69的概率;利用标准正态概率表,z=-2.69时,p值=0.0038
其中我们可以这样理解z小于或者等于-2.69的概率p=0.0038这一事件的发生概率是非常的小,又加上允许犯错的概率是0.01(也即是发生的概率是0.01结果是非常小的,我直接忽略了)。
所以我们直接认为z小于或者等于-2.69这一事件太小以至于我们认为他是不发生的。所以我们拒绝了H0:u>=3这一假设。所以,在0.01的显著水平下有足够的统计证据拒绝H0。

往期精选
数据分析师的发(xing)展(fu)方(sheng)向(huo)
介绍一个2000+star的Github项目
强推 | 学习自然语言处理(NLP)的学习方法和资料合集
2018年终精心整理|人工智能爱好者社区历史文章合集(作者篇)
2018年终精心整理 | 人工智能爱好者社区历史文章合集(类型篇)
公众号后台回复关键词学习
回复 免费 获取免费课程
回复 直播 获取系列直播课
回复 Python 1小时破冰入门Python
回复 人工智能 从零入门人工智能
回复 深度学习 手把手教你用Python深度学习
回复 机器学习 小白学数据挖掘与机器学习
回复 贝叶斯算法 贝叶斯与新闻分类实战
回复 数据分析师 数据分析师八大能力培养
回复 自然语言处理 自然语言处理之AI深度学习

