
作者:挖数 腾讯数据产品经理 & 段子手
个人微信公号:washu66
虽然我很讨厌咪蒙,但不可否认的是,咪蒙有很好的文笔~
作为半个程序员的我,是怎么训练我的文笔的呢?今天,我就跟陈独秀一起,分享一些提升文笔的小技巧
一、分词取同类型词
读书时写作文,老羡慕同桌学霸成语用得溜,写描述春天的句子,我只会写春天来了,燕子多了,他偏偏写春回大地,万紫千红,给隔壁班花寄情书,我写你真好看啊,眼睛很大,他偏写你眼波流转,秀色可餐,于是放学后我只能眼睁睁看他们手牵着手。
现在成了半个程序员,成语用得比当年的学霸还溜,你问我怎么学的?文本分析呗。
比如拿起金庸的《鹿鼎记》,我立马可以知道金庸喜欢用哪些成语,它们的使用频次如何,只要跑一段分词代码,把成语提取出来并统计频次

如果你不喜欢武侠小说,拿琼瑶的《窗外》也可以

以下是分词的Python代码
a={'word':[],'count':[]}f=open('c:/python/wenben/chuan.txt','r',encoding='utf8').read()words=list(jieba.cut(f))for word in words: if len(word)>=4: a['word'].append(word) a['count'].append(1)b=pd.DataFrame(a)c=pd.pivot_table(b,index=['word'],values=['count'],aggfunc=np.sum)c.to_csv('c:/python/wenben/chuan.csv',mode='w',encoding='utf8')
二、寻找某一词性最集中的段落
很多时候觉得一篇文章文笔美,是因为它有很多描写事物的辞藻,当读多这样的文章时,自己的文笔也能得到提高。
那假设读文章只读辞藻华丽的部分,抛弃其他部分,这样是不是可以提高你单位时间的吸收效率?
为了简化,把“辞藻华丽程度”量化为一个段落里的“形容词密度”,写一段代码用来统计各段落的形容词密度,然后把徐志摩的几篇散文放进去,让它输出辞藻华丽程度Top5的段落,结果如下:
Top1 《北戴河海滨的幻想》第4段,形容词密度:10.4%
青年永远趋向反叛,爱好冒险;永远如初度航海者,幻想黄金机缘于浩渺的烟波之外:想割断系岸的缆绳,扯起风帆,欣欣的投入无垠的怀抱。他厌恶的是平安,自喜的是放纵与豪迈。无颜色的生涯,是他目中的荆棘;绝海与凶巘,是他爱取自由的途径。他爱折玫瑰;为她的色香,亦为她冷酷的刺毒。
Top2 《北戴河海滨的幻想》第7段,形容词密度:9.6%
流水之光,星之光,露珠之光,电之光,在青年的妙目中闪耀,我们不能不惊讶造化者艺术之神奇,然可怖的黑影,倦与衰与饱餍的黑影,同时亦紧紧的跟着时日进行,仿佛是烦恼、痛苦、失败,或庸俗的尾曳,亦在转瞬间,彗星似的扫灭了我们最自傲的神辉——流水涸,明星没,露珠散灭,电闪不再!
Top3 《翡冷翠山居闲话》最后一段,形容词密度:8.1%
书是理想的伴侣,但你应得带书,是在火车上,在你住处的客室里,不是在你独身漫步的时候。什么伟大的深沉的鼓舞的清明的优美的思想的根源不是可以在风籁中,云彩里,山势与地形的起伏里,花草的颜色与香息里寻得?...
Top4《北戴河海滨的幻想》第6段,形容词密度:8%
幻象消灭是人生里命定的悲剧;青年的幻灭,更是悲剧中的悲剧,夜一般的沉黑,死一般的凶恶。纯粹的,倡狂的热情之火,不同阿拉伯的神灯,只能放射一时的异彩,不能永久的朗照;转瞬间,或许,便已敛熄了最后的焰舌,只留存有限的余烬与残灰,在未灭的余温里自伤与自慰。
Top5 《泰山日出》第7段,形容词密度:6.9%
一方的异彩,揭去了满天的睡意,唤醒了四隅的明霞一光明的神驹,在热奋地驰骋……
Python代码
adj={'content':[],'cnt':[]}for line in open('c:/python/wenben/zhimo.txt','r'): adj['content'].append(line) words = pseg.cut(line) adj_cnt=0 cnt=0 for word, flag in words: if flag in ['Ag','a','ad','an']: adj_cnt+=1 cnt+=1 adj['cnt'].append(adj_cnt/cnt)adj2=pd.DataFrame(adj)adj2=adj2.sort_values(by = 'cnt',axis = 0,ascending = False)print(adj2[:5])
三、利用词向量找同义词
记得小学语文课本上有一篇朱自清的《春》,上面有一段描写
盼望着,盼望着,东风来了,春天的脚步近了。春天像小姑娘,花枝招展的,笑着,走着。
自从学了这篇课文,从此班上同学写春天,都是千篇一律的“春姑娘来了”,“春天的脚步近了”,老师看了特别恼火。
后面我才知道,文笔的好坏,还在于他描写的多样性。写一样东西,如果你能七十二变不重样,应该也算是文笔好之一吧。
由此我想到词向量的应用,如果你学过线性代数应该知道向量这个东西,词向量实际就是把一个词变成一个高维向量,变成向量的好处之一,是通过计算两个向量的相似度,来近似于他们在语料里边的相似度。
比如你想学金庸的描写手法,可以用词向量把他对一件事物的描写手法全部枚举出来。
试试枚举跟笑相关的描述
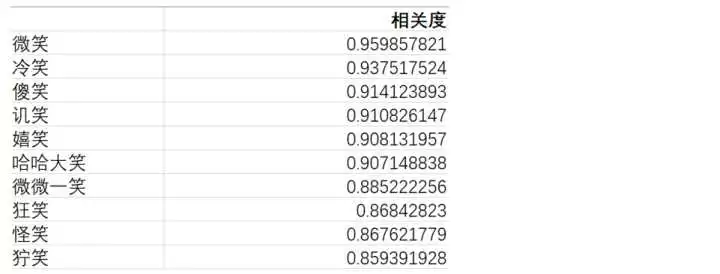
Python代码
#分词并生成语料库f1 =open("c:/python/wenben/lu.txt",encoding='utf8') f2 =open("c:/python/wenben/word.txt", 'w',encoding='utf8') lu=f1.read()lu.replace(' ','').replace('
','').replace(' ','') word = jieba.cut(lu) f2.write(" ".join(word)) f1.close() f2.close()#用语料训练词向量sentences =word2vec.Text8Corpus("c:/python/wenben/word.txt") model =word2vec.Word2Vec(sentences, size=200)#输出同义词y = model.wv.most_similar("笑",topn=20)for item in y: print (item[0], item[1])
Just for fun, don't be serious~

公众号后台回复关键词学习
回复 免费 获取免费课程
回复 直播 获取系列直播课
回复 Python 1小时破冰入门Python
回复 人工智能 从零入门人工智能
回复 深度学习 手把手教你用Python深度学习
回复 机器学习 小白学数据挖掘与机器学习
回复 贝叶斯算法 贝叶斯与新闻分类实战
回复 数据分析师 数据分析师八大能力培养
回复 自然语言处理 自然语言处理之AI深度学习

