作者简介:
Treant 人工智能爱好者社区专栏作者
博客专栏:https://www.cnblogs.com/en-heng
1.引言
顶级数据挖掘会议ICDM于2006年12月评选出了数据挖掘领域的十大经典算法:C4.5, k-Means, SVM, Apriori, EM, PageRank, AdaBoost, kNN, Naïve Bayes与 CART。 以前看过关于这些数据挖掘算法,但对背后数学原理未做过多探究,因而借此整理以更深入地理解这些算法。
本文讨论的kNN算法是监督学习中分类方法的一种。所谓监督学习与非监督学习,是指训练数据是否有标注类别,若有则为监督学习,若否则为非监督学习。监督学习是根据输入数据(训练数据)学习一个模型,能对后来的输入做预测。在监督学习中,输入变量与输出变量可以是连续的,也可以是离散的。若输入变量与输出变量均为连续变量,则称为回归;输出变量为有限个离散变量,则称为分类;输入变量与输出变量均为变量序列,则称为标注[2]。
2.kNN算法
kNN算法的核心思想非常简单:在训练集中选取离输入的数据点最近的k个邻居,根据这个k个邻居中出现次数最多的类别(最大表决规则),作为该数据点的类别。
算法描述
训练 ,其类别
,其类别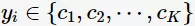 ,训练集中样本点数为N,类别数为K。输入待预测数据
,训练集中样本点数为N,类别数为K。输入待预测数据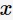 ,则预测类别
,则预测类别
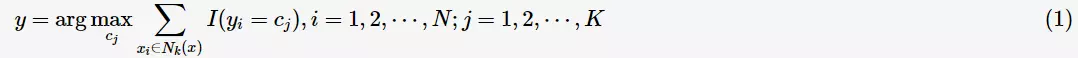
其中,涵盖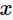 的k邻域记作
的k邻域记作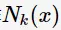 ,当
,当 时指示函数
时指示函数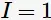 ,否则
,否则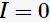 。
。
分类决策规则
kNN学习模型:输入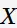 ,通过学习得到决策函数:输出类别
,通过学习得到决策函数:输出类别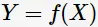 。假设分类损失函数为0-1损失函数,即分类正确时损失函数值为0,分类错误时则为1。假如给
。假设分类损失函数为0-1损失函数,即分类正确时损失函数值为0,分类错误时则为1。假如给 预测类别为
预测类别为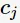 ,即
,即 ;同时由式子(1)可知k邻域的样本点对学习模型的贡献度是均等的,则kNN学习模型误分类率为
;同时由式子(1)可知k邻域的样本点对学习模型的贡献度是均等的,则kNN学习模型误分类率为
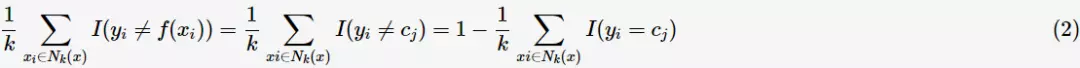
若要最小化误分类率,则应
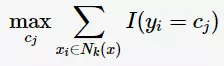
所以,最大表决规则等价于经验风险最小化。
存在问题
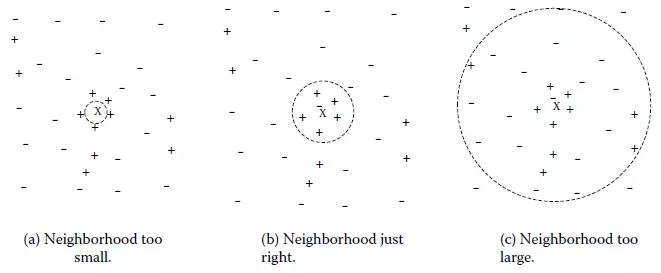
k值得选取对kNN学习模型有着很大的影响。若k值过小,预测结果会对噪音样本点显得异常敏感。特别地,当k等于1时,kNN退化成最近邻算法,没有了显式的学习过程。若k值过大,会有较大的邻域训练样本进行预测,可以减小噪音样本点的减少;但是距离较远的训练样本点对预测结果会有贡献,以至于造成预测结果错误。下图给出k值的选取对于预测结果的影响:
前面提到过,k邻域的样本点对预测结果的贡献度是相等的;但距离更近的样本点应有更大的相似度,其贡献度应比距离更远的样本点大。可以加上权值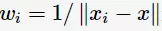 进行修正,则最大表决原则变成:
进行修正,则最大表决原则变成:
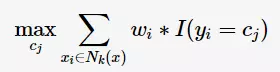
3.参考资料:
[1] Michael Steinbach and Pang-Ning Tan, The Top Ten Algorithms in Data Mining.
[2] 李航,《统计学习方法》.
往期回顾:
【十大经典数据挖掘算法】C4.5
【十大经典数据挖掘算法】k-means
【十大经典数据挖掘算法】SVM
【十大经典数据挖掘算法】Apriori
【十大经典数据挖掘算法】EM
【十大经典数据挖掘算法】PageRank
【十大经典数据挖掘算法】AdaBoost
【从传统方法到深度学习】图像分类

公众号后台回复关键词学习
回复 免费 获取免费课程
回复 直播 获取系列直播课
回复 Python 1小时破冰入门Python
回复 人工智能 从零入门人工智能
回复 深度学习 手把手教你用Python深度学习
回复 机器学习 小白学数据挖掘与机器学习
回复 贝叶斯算法 贝叶斯与新闻分类实战
回复 数据分析师 数据分析师八大能力培养
回复 自然语言处理 自然语言处理之AI深度学习

