
作者:Charlotte77 数学系的数据挖掘民工
博客专栏:http://www.cnblogs.com/charlotte77/
个人公众号:Charlotte数据挖掘(ID:CharlotteDataMining)
精彩回顾:
上篇文章讲了卷积神经网络的基本知识,本来这篇文章准备继续深入讲CNN的相关知识和手写CNN,但是有很多同学跟我发邮件或私信问我关于PaddlePaddle如何读取数据、做数据预处理相关的内容。网上看的很多教程都是几个常见的例子,数据集不需要自己准备,所以不需要关心,但是实际做项目的时候做数据预处理感觉一头雾水,所以我就写一篇文章汇总一下,讲讲如何用PaddlePaddle做数据预处理。
PaddlePaddle的基本数据格式
根据官网的资料,总结出PaddlePaddle支持多种不同的数据格式,包括四种数据类型和三种序列格式:
四种数据类型:
dense_vector:稠密的浮点数向量。
sparse_binary_vector:稀疏的二值向量,即大部分值为0,但有值的地方必须为1。
sparse_float_vector:稀疏的向量,即大部分值为0,但有值的部分可以是任何浮点数。
integer:整型格式
api如下:
paddle.v2.data_type.dense_vector(dim, seq_type=0)
dim(int) 向量维度
seq_type(int)输入的序列格式
说明:稠密向量,输入特征是一个稠密的浮点向量。举个例子,手写数字识别里的输入图片是28*28的像素,Paddle的神经网络的输入应该是一个784维的稠密向量。
参数:
返回类型:InputType
paddle.v2.data_type.sparse_binary_vector(dim, seq_type=0)
说明:稀疏的二值向量。输入特征是一个稀疏向量,这个向量的每个元素要么是0,要么是1
参数:同上
返回类型:同上
paddle.v2.data_type.sparse_vector(dim, seq_type=0)
说明:稀疏向量,向量里大多数元素是0,其他的值可以是任意的浮点值
参数:同上
返回类型:同上
paddle.v2.data_type.integer_value(value_range, seq_type=0)
seq_type(int):输入的序列格式
value_range(int):每个元素的范围
说明:整型格式
参数:
返回类型:InputType
三种序列格式:
SequenceType.NO_SEQUENCE:不是一条序列
SequenceType.SEQUENCE:是一条时间序列
SequenceType.SUB_SEQUENCE: 是一条时间序列,且序列的每一个元素还是一个时间序列。
api如下:
paddle.v2.data_type.dense_vector_sequence(dim, seq_type=0)
说明:稠密向量的序列格式
参数:dim(int):稠密向量的维度
返回类型:InputType
paddle.v2.data_type.sparse_binary_vector_sequence(dim, seq_type=0)
说明:稀疏的二值向量序列。每个序列里的元素要么是0要么是1
参数:dim(int):稀疏向量的维度
返回类型:InputType
paddle.v2.data_type.sparse_non_value_slot(dim, seq_type=0)
dim(int):稀疏向量的维度
seq_type(int):输入的序列格式
说明:稀疏的向量序列。每个序列里的元素要么是0要么是1
参数:
返回类型:InputType
paddle.v2.data_type.sparse_value_slot(dim, seq_type=0)
dim(int):稀疏向量的维度
seq_type(int):输入的序列格式
说明:稀疏的向量序列,向量里大多数元素是0,其他的值可以是任意的浮点值
参数:
返回类型:InputType
说明:value_range(int):每个元素的范围
paddle.v2.data_type.integer_value_sequence(value_range, seq_type=0)
不同的数据类型和序列模式返回的格式不同,如下表:

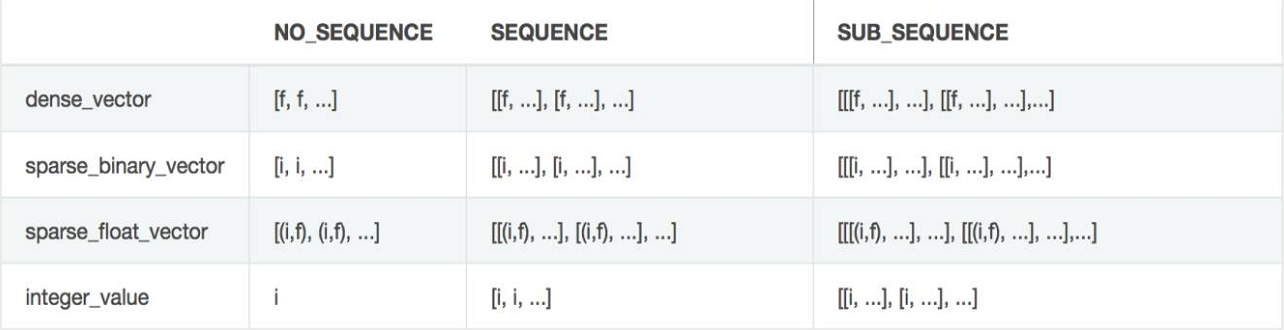
其中f表示浮点数,i表示整数
注意:对sparse_binary_vector和sparse_float_vector,PaddlePaddle存的是有值位置的索引。例如,
对一个5维非序列的稀疏01向量
[0, 1, 1, 0, 0],类型是sparse_binary_vector,返回的是[1, 2]。(因为只有第1位和第2位有值)对一个5维非序列的稀疏浮点向量
[0, 0.5, 0.7, 0, 0],类型是sparse_float_vector,返回的是[(1, 0.5), (2, 0.7)]。(因为只有第一位和第二位有值,分别是0.5和0.7)
PaddlePaddle的数据读取方式
我们了解了上文的四种基本数据格式和三种序列模式后,在处理自己的数据时可以根据需求选择,但是处理完数据后如何把数据放到模型里去训练呢?我们知道,基本的方法一般有两种:
一次性加载到内存:模型训练时直接从内存中取数据,不需要大量的IO消耗,速度快,适合少量数据。
加载到磁盘/HDFS/共享存储等:这样不用占用内存空间,在处理大量数据时一般采取这种方式,但是缺点是每次数据加载进来也是一次IO的开销,非常影响速度。
在PaddlePaddle中我们可以有三种模式来读取数据:分别是reader、reader creator和reader decorator,这三者有什么区别呢?
reader:从本地、网络、分布式文件系统HDFS等读取数据,也可随机生成数据,并返回一个或多个数据项。
reader creator:一个返回reader的函数。
reader decorator:装饰器,可组合一个或多个reader。
reader
我们先以reader为例,为房价数据(斯坦福吴恩达的公开课第一课举例的数据)创建一个reader:
创建一个reader,实质上是一个迭代器,每次返回一条数据(此处以房价数据为例)
reader = paddle.dataset.uci_housing.train()
2. 创建一个shuffle_reader,把上一步的reader放进去,配置buf_size就可以读取buf_size大小的数据自动做shuffle,让数据打乱,随机化
shuffle_reader = paddle.reader.shuffle(reader,buf_size= 100)
3.创建一个batch_reader,把上一步混洗好的shuffle_reader放进去,给定batch_size,即可创建。
batch_reader = paddle.batch(shuffle_reader,batch_size = 2)
这三种方式也可以组合起来放一块:
reader = paddle.batch(
paddle.reader.shuffle(
uci_housing.train(),
buf_size = 100),
batch_size=2)
可以以一个直观的图来表示:
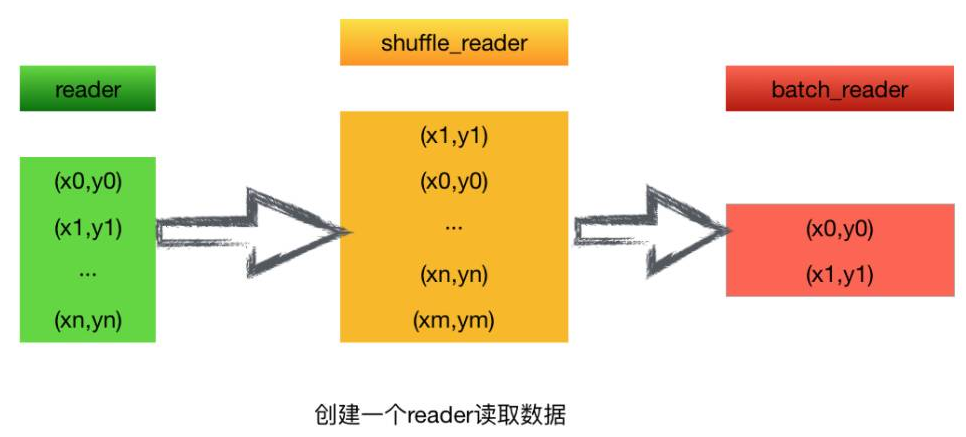
从图中可以看到,我们可以直接从原始数据集里拿去数据,用reader读取,一条条灌倒shuffle_reader里,在本地随机化,把数据打乱,做shuffle,然后把shuffle后的数据,一个batch一个batch的形式,批量的放到训练器里去进行每一步的迭代和训练。 流程简单,而且只需要使用一行代码即可实现整个过程。
reader creator
如果想要生成一个简单的随机数据,以reader creator为例:
def reader_creator(): def reader(): while True: yield numpy.random.uniform(-1,1,size=784) return reader
源码见creator.py, 支持四种格式:np_array,text_file,RecordIO和cloud_reader
__all__ = ['np_array', 'text_file', "cloud_reader"]
def np_array(x):
"""
Creates a reader that yields elements of x, if it is a
numpy vector. Or rows of x, if it is a numpy matrix.
Or any sub-hyperplane indexed by the highest dimension.
:param x: the numpy array to create reader from.
:returns: data reader created from x.
"""
def reader():
if x.ndim < 1:
yield x
for e in x:
yield e
return reader
def text_file(path):
"""
Creates a data reader that outputs text line by line from given text file.
Trailing new line ('\\\\n') of each line will be removed.
:path: path of the text file.
:returns: data reader of text file
"""
def reader():
f = open(path, "r")
for l in f:
yield l.rstrip('\n')
f.close()
return reader
def recordio(paths, buf_size=100):
"""
Creates a data reader from given RecordIO file paths separated by ",",
glob pattern is supported.
:path: path of recordio files, can be a string or a string list.
:returns: data reader of recordio files.
"""
import recordio as rec
import paddle.v2.reader.decorator as dec
import cPickle as pickle
def reader():
if isinstance(paths, basestring):
path = paths
else:
path = ",".join(paths)
f = rec.reader(path)
while True:
r = f.read()
if r is None:
break
yield pickle.loads(r)
f.close()
return dec.buffered(reader, buf_size)
pass_num = 0
def cloud_reader(paths, etcd_endpoints, timeout_sec=5, buf_size=64):
"""
Create a data reader that yield a record one by one from
the paths:
:paths: path of recordio files, can be a string or a string list.
:etcd_endpoints: the endpoints for etcd cluster
:returns: data reader of recordio files.
.. code-block:: python
from paddle.v2.reader.creator import cloud_reader
etcd_endpoints = "http://127.0.0.1:2379"
trainer.train.(
reader=cloud_reader(["/work/dataset/uci_housing/uci_housing*"], etcd_endpoints),
)
"""
import os
import cPickle as pickle
import paddle.v2.master as master
c = master.client(etcd_endpoints, timeout_sec, buf_size)
if isinstance(paths, basestring):
path = [paths]
else:
path = paths
c.set_dataset(path)
def reader():
global pass_num
c.paddle_start_get_records(pass_num)
pass_num += 1
while True:
r, e = c.next_record()
if not r:
if e != -2:
print "get record error: ", e
break
yield pickle.loads(r)
return reader
reader decorator
如果想要读取同时读取两部分的数据,那么可以定义两个reader,合并后对其进行shuffle。如我想读取所有用户对比车系的数据和浏览车系的数据,可以定义两个reader,分别为contrast()和view(),然后通过预定义的reader decorator缓存并组合这些数据,在对合并后的数据进行乱序操作。源码见decorator.py
data = paddle.reader.shuffle(
paddle.reader.compose(
paddle.reader(contradt(contrast_path),buf_size = 100),
paddle.reader(view(view_path),buf_size = 200), 500)
这样有一个很大的好处,就是组合特征来训练变得更容易了!传统的跑模型的方法是,确定label和feature,尽可能多的找合适的feature扔到模型里去训练,这样我们就需要做一张大表,训练完后我们可以分析某些特征的重要性然后重新增加或减少一些feature来进行训练,这样我们有需要对原来的label-feature表进行修改,如果数据量小没啥影响,就是麻烦点,但是数据量大的话需要每一次增加feature,和主键、label来join的操作都会很耗时,如果采取这种方式的话,我们可以对某些同一类的特征做成一张表,数据存放的地址存为一个变量名,每次跑模型的时候想选取几类特征,就创建几个reader,用reader decorator 组合起来,最后再shuffle灌倒模型里去训练。这!样!是!不!是!很!方!便!
如果没理解,我举一个实例,假设我们要预测用户是否会买车,label是买车 or 不买车,feature有浏览车系、对比车系、关注车系的功能偏好等等20个,传统的思维是做成这样一张表:
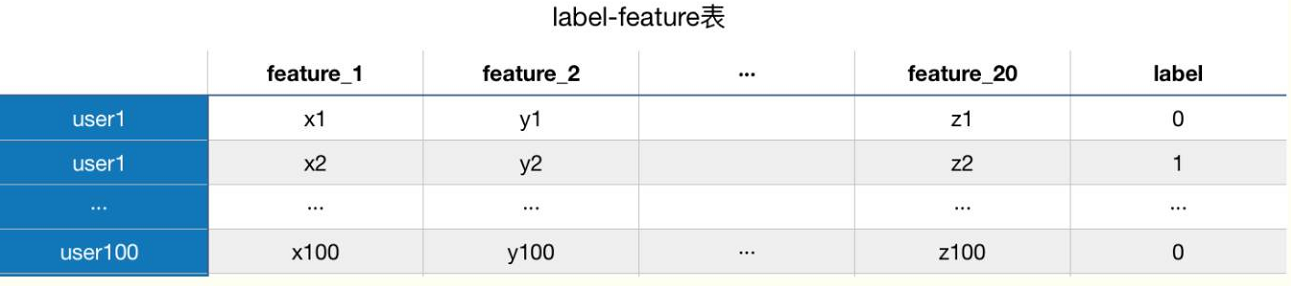
如果想要减少feature_2,看看feature_2对模型的准确率影响是否很大,那么我们需要在这张表里去掉这一列,想要增加一个feature的话,也需要在feature里增加一列,如果用reador decorator的话,我们可以这样做数据集:
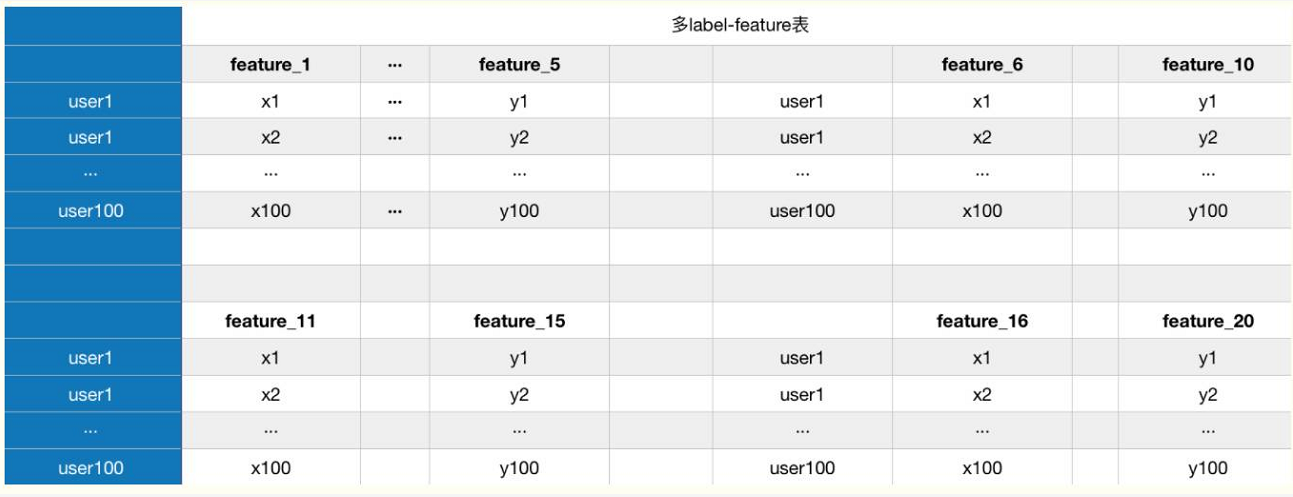
把相同类型的feature放在一起,不用频繁的join减少时间,一共做四个表,创建4个reador:
data = paddle.reader.shuffle(
paddle.reader.compose(
paddle.reader(table1(table1_path),buf_size = 100),
paddle.reader(table2(table2_path),buf_size = 100),
paddle.reader(table3(table3_path),buf_size = 100),
paddle.reader(table4(table4_path),buf_size = 100),
500)
如果新发现了一个特征,想尝试这个特征对模型提高准确率有没有用,可以再单独把这个特征数据提取出来,再增加一个reader,用reader decorator组合起来,shuffle后放入模型里跑就行了。
PaddlePaddle的数据预处理实例
还是以手写数字为例,对数据进行处理后并划分train和test,只需要4步即可:
1.指定数据地址
import paddle.v2.dataset.common
import subprocess
import numpy
import platform
__all__ = ['train', 'test', 'convert']
URL_PREFIX = 'http://yann.lecun.com/exdb/mnist/'
TEST_IMAGE_URL = URL_PREFIX + 't10k-images-idx3-ubyte.gz'
TEST_IMAGE_MD5 = '9fb629c4189551a2d022fa330f9573f3'
TEST_LABEL_URL = URL_PREFIX + 't10k-labels-idx1-ubyte.gz'
TEST_LABEL_MD5 = 'ec29112dd5afa0611ce80d1b7f02629c'
TRAIN_IMAGE_URL = URL_PREFIX + 'train-images-idx3-ubyte.gz'
TRAIN_IMAGE_MD5 = 'f68b3c2dcbeaaa9fbdd348bbdeb94873'
TRAIN_LABEL_URL = URL_PREFIX + 'train-labels-idx1-ubyte.gz'
TRAIN_LABEL_MD5 = 'd53e105ee54ea40749a09fcbcd1e9432'
2.创建reader creator
def reader_creator(image_filename, label_filename, buffer_size):
# 创建一个reader
def reader():
if platform.system() == 'Darwin':
zcat_cmd = 'gzcat'
elif platform.system() == 'Linux':
zcat_cmd = 'zcat'
else:
raise NotImplementedError()
m = subprocess.Popen([zcat_cmd, image_filename], stdout=subprocess.PIPE)
m.stdout.read(16)
l = subprocess.Popen([zcat_cmd, label_filename], stdout=subprocess.PIPE)
l.stdout.read(8)
try: # reader could be break.
while True:
labels = numpy.fromfile(
l.stdout, 'ubyte', count=buffer_size).astype("int")
if labels.size != buffer_size:
break # numpy.fromfile returns empty slice after EOF.
images = numpy.fromfile(
m.stdout, 'ubyte', count=buffer_size * 28 * 28).reshape(
(buffer_size, 28 * 28)).astype('float32')
images = images / 255.0 * 2.0 - 1.0
for i in xrange(buffer_size):
yield images[i, :], int(labels[i])
finally:
m.terminate()
l.terminate()
return reader
3.创建训练集和测试集
def train():
"""
创建mnsit的训练集 reader creator
返回一个reador creator,每个reader里的样本都是图片的像素值,在区间[0,1]内,label为0~9
返回:training reader creator
"""
return reader_creator(
paddle.v2.dataset.common.download(TRAIN_IMAGE_URL, 'mnist',
TRAIN_IMAGE_MD5),
paddle.v2.dataset.common.download(TRAIN_LABEL_URL, 'mnist',
TRAIN_LABEL_MD5), 100)
def test():
"""
创建mnsit的测试集 reader creator
返回一个reador creator,每个reader里的样本都是图片的像素值,在区间[0,1]内,label为0~9
返回:testreader creator
"""
return reader_creator(
paddle.v2.dataset.common.download(TEST_IMAGE_URL, 'mnist',
TEST_IMAGE_MD5),
paddle.v2.dataset.common.download(TEST_LABEL_URL, 'mnist',
TEST_LABEL_MD5), 100)
4.下载数据并转换成相应格式
def fetch():
paddle.v2.dataset.common.download(TRAIN_IMAGE_URL, 'mnist', TRAIN_IMAGE_MD5)
paddle.v2.dataset.common.download(TRAIN_LABEL_URL, 'mnist', TRAIN_LABEL_MD5)
paddle.v2.dataset.common.download(TEST_IMAGE_URL, 'mnist', TEST_IMAGE_MD5)
paddle.v2.dataset.common.download(TEST_LABEL_URL, 'mnist', TRAIN_LABEL_MD5)
def convert(path):
"""
将数据格式转换为 recordio format
"""
paddle.v2.dataset.common.convert(path, train(), 1000, "minist_train")
paddle.v2.dataset.common.convert(path, test(), 1000, "minist_test")
如果想换成自己的训练数据,只需要按照步骤改成自己的数据地址,创建相应的reader creator(或者reader decorator)即可。
这是图像的例子,如果我们想训练一个文本模型,做一个情感分析,这个时候如何处理数据呢?步骤也很简单。
假设我们有一堆数据,每一行为一条样本,以 \t 分隔,第一列是类别标签,第二列是输入文本的内容,文本内容中的词语以空格分隔。以下是两条示例数据:
positive 今天终于试了自己理想的车 外观太骚气了 而且中控也很棒
negative 这台车好贵 而且还费油 性价比太低了现在开始做数据预处理
1.创建reader
def train_reader(data_dir, word_dict, label_dict):
def reader():
UNK_ID = word_dict["<UNK>"]
word_col = 0
lbl_col = 1
for file_name in os.listdir(data_dir):
with open(os.path.join(data_dir, file_name), "r") as f:
for line in f:
line_split = line.strip().split("\t")
word_ids = [
word_dict.get(w, UNK_ID)
for w in line_split[word_col].split()
]
yield word_ids, label_dict[line_split[lbl_col]]
return reader
返回类型为: paddle.data_type.integer_value_sequence(词语在字典的序号)和 paddle.data_type.integer_value(类别标签)
2.组合读取方式
train_reader = paddle.batch(
paddle.reader.shuffle(
reader.train_reader(train_data_dir, word_dict, lbl_dict),
buf_size=1000),
batch_size=batch_size)
完整的代码如下(加上了划分train和test部分):
import os
def train_reader(data_dir, word_dict, label_dict):
"""
创建训练数据reader
:param data_dir: 数据地址.
:type data_dir: str
:param word_dict: 词典地址,
词典里必须有 "UNK" .
:type word_dict:python dict
:param label_dict: label 字典的地址
:type label_dict: Python dict
"""
def reader():
UNK_ID = word_dict["<UNK>"]
word_col = 1
lbl_col = 0
for file_name in os.listdir(data_dir):
with open(os.path.join(data_dir, file_name), "r") as f:
for line in f:
line_split = line.strip().split("\t")
word_ids = [
word_dict.get(w, UNK_ID)
for w in line_split[word_col].split()
]
yield word_ids, label_dict[line_split[lbl_col]]
return reader
def test_reader(data_dir, word_dict):
"""
创建测试数据reader
:param data_dir: 数据地址.
:type data_dir: str
:param word_dict: 词典地址,
词典里必须有 "UNK" .
:type word_dict:python dict
"""
def reader():
UNK_ID = word_dict["<UNK>"]
word_col = 1
for file_name in os.listdir(data_dir):
with open(os.path.join(data_dir, file_name), "r") as f:
for line in f:
line_split = line.strip().split("\t")
if len(line_split) < word_col: continue
word_ids = [
word_dict.get(w, UNK_ID)
for w in line_split[word_col].split()
]
yield word_ids, line_split[word_col]
return reader
总结
这篇文章主要讲了在paddlepaddle里如何加载自己的数据集,转换成相应的格式,并划分train和test。我们在使用一个框架的时候通常会先去跑几个简单的demo,但是如果不用常见的demo的数据,自己做一个实际的项目,完整的跑通一个模型,这才代表我们掌握了这个框架的基本应用知识。跑一个模型第一步就是数据预处理,在paddlepaddle里,提供的方式非常简单,但是有很多优点:
shuffle数据非常方便
可以将数据组合成batch训练
可以利用reader decorator来组合多个reader,提高组合特征运行模型的效率
可以多线程读取数据
而我之前使用过mxnet来训练车牌识别的模型,50w的图片数据想要一次训练是非常慢的,这样的话就有两个解决方法:一是批量训练,这一点大多数的框架都会有, 二是转换成mxnet特有的rec格式,提高读取效率,可以通过im2rec.py将图片转换,比较麻烦,如果是tesnorflow,也有相对应的特定格式tfrecord,这几种方式各有优劣,从易用性上,paddlepaddle是比较简单的。
这篇文章没有与上篇衔接起来,因为看到有好几封邮件都有问怎么自己加载数据训练,所以就决定插入一节先把这个写了。下篇文章我们接着讲CNN的进阶知识。下周见^_^!
参考文章:
1.官网说明:http://doc.paddlepaddle.org/develop/doc_cn/getstarted/concepts/use_concepts_cn.html
公众号后台回复关键词学习
回复 人工智能 揭开人工智能的神秘面纱
回复 贝叶斯算法 贝叶斯算法与新闻分类
回复 机器学习 R&Python机器学习
回复 阿里数据 阿里数据系列课程
回复 Python Python机器学习案例实战
回复 Spark 征服Spark第一季
回复 kaggle 机器学习kaggle案例
回复 大数据 大数据系列视频
回复 数据分析 数据分析人员的转型
回复 数据挖掘 数据挖掘与人工智能
回复 机器学习 R&Python机器学习
回复 阿里数据 阿里数据系列课程
回复 R R&Python机器学习入门

