作者:射命丸咲 Python 与 机器学习 爱好者
知乎专栏:https://zhuanlan.zhihu.com/carefree0910-pyml
个人网站:http://www.carefree0910.com
往期阅读:
从零开始学人工智能(12)--Python · 决策树(零)· 简介
从零开始学人工智能(13)--Python · 决策树(一)· 准则
从零开始学人工智能(14)--Python · 决策树(二)· 节点
从零开始学人工智能(15)--Python · 决策树(三)· 节点
本章用到的 GitHub 地址:https://github.com/carefree0910/MachineLearning/blob/master/Zhihu/CvDTree/one/CvDTree.py
本章用到的数学相关知识:https://zhuanlan.zhihu.com/p/24498143?refer=carefree0910-pyml
这一章就是朴素实现的最后一章了,我们会在这一部分搭建一个比较完整的决策树框架
上一章我们也提过,我们主要还需要做的只有一个:剪枝
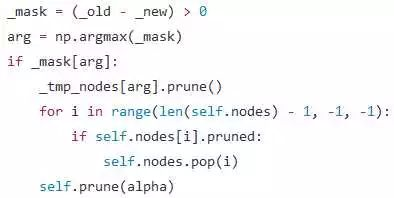
同样的,为了简洁(懒),我们采用普通的剪枝算法:
这些就是剪枝算法的全部了,不知是否比你想象中的要简洁一些?当然了、这是通过牺牲效率来换取的简洁,好的做法应该是:
找到决策树“从下往上”的次序
依次判断每个 Node 是否应该剪枝
这样做的话算法复杂度会降低不少、但实现起来也会稍微复杂一点。如果有时间的话(啧)会在后序章节中进行补充
最后放一下在数据集上运行的结果。在 Python · 决策树(零)· 简介 这一章中,我用到了这么两张图:

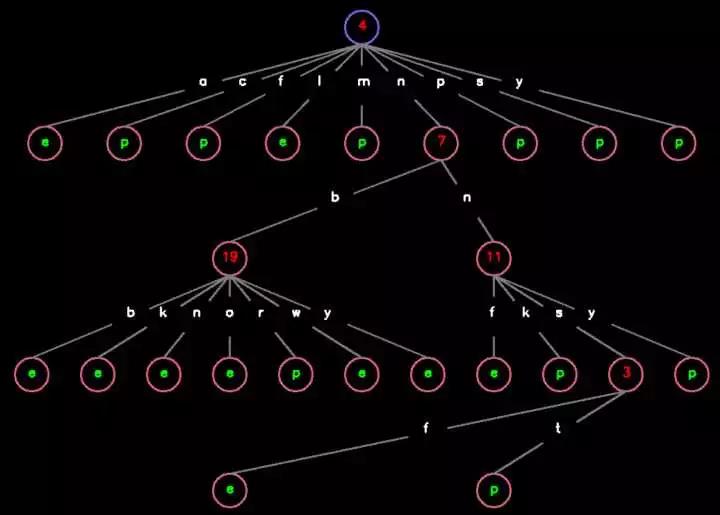
它们其实都是在另一种剪枝算法下的最终结果。如果按这一章的算法(令惩罚因子 alpha = 1)来做,最终结果是这样的:

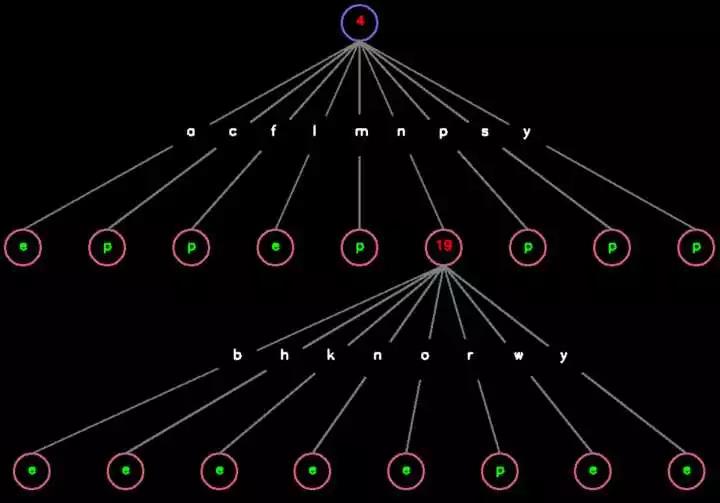
此时的正确率大约是 99.4878 %,可以看到这一章的剪枝算法(在惩罚因子 alpha = 1 时)把原先对应第 19 维数据的第二层 Node 中取值为 w 的子树给剪掉了。
以上及之前的各章节加总即是一个比较朴素的决策树的所有实现,它有如下功能:
这不算是一个很完善的决策树、但基本的雏形已经有了,而且由于抽象做得比较好、它的可拓展性会比较强。接下来(如果有时间的话)我们会继续做如下事情:
利用 np.bincount 来加速我们的算法
让我们的决策树支持输入样本权重和支持连续型特征
将 C4.5 算法整合到这个框架中
(争取)把 CART 算法也整合到这个框架中
希望观众老爷们能够喜欢~


公众号后台回复关键词学习
回复 人工智能 揭开人工智能的神秘面纱
回复 贝叶斯算法 贝叶斯算法与新闻分类
回复 机器学习 R&Python机器学习
回复 阿里数据 阿里数据系列课程
回复 Python Python机器学习案例实战
回复 Spark 征服Spark第一季
回复 kaggle 机器学习kaggle案例
回复 大数据 大数据系列视频
回复 数据分析 数据分析人员的转型
回复 数据挖掘 数据挖掘与人工智能
回复 机器学习 R&Python机器学习
回复 阿里数据 阿里数据系列课程
回复 R R&Python机器学习入门