作者:射命丸咲 Python 与 机器学习 爱好者
知乎专栏:https://zhuanlan.zhihu.com/carefree0910-pyml
个人网站:http://www.carefree0910.com
往期阅读:
从零开始学人工智能(10)--Python · 神经网络(三*)· 网络
从零开始学人工智能(11)--Python · 神经网络(四*)· 网络
决策树是听上去比较厉害且又相对简单的算法,但在实现它的过程中可能会对编程本身有更深的理解、尤其是对递归的利用
我个人的习惯是先说明最终能干什么、然后再来说怎么实现,这样也能避免一些不必要的信息筛选。所以,这一部分主要用于让已经知道一定的基础知识的童鞋知道最后能走多远,如果是想从头开始学的话可以无视这一章直接看第一章
ID3 和 C4.5(可以控制最大深度),CART 可能会在假期实现
可视化;比如在比较著名的蘑菇数据集上的最终结果为(随机 5000 个训练):
正确率 100%(大概挺正常的……)。其中,每个 Node 最后那个括号里面,箭头前面是特征取值,箭头后面或者是类别、或者是下一个选取的特征的维度

运用 cv2 的话可以画出比较传统的决策树的可视化图,效果大致如下:
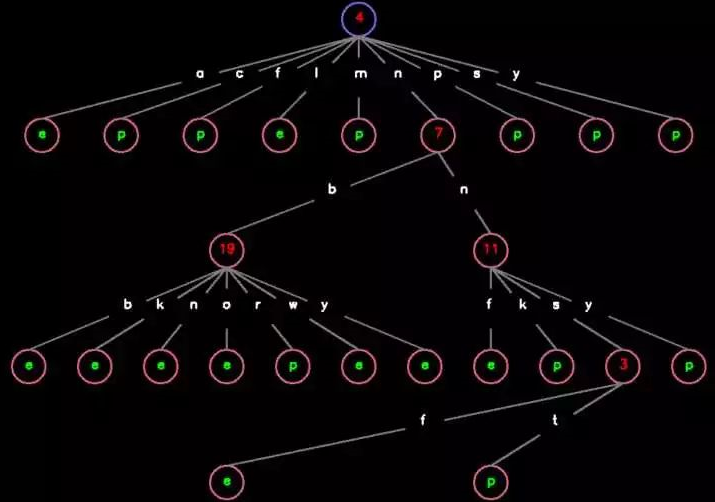
其中红色数字标注了该 Node 选择了数据的哪个维度,绿色字母表示该 Node 所属的类别,白色字母代表着对应数据维度特征的取值
比如说如果样本的第 4 维(从 0 开始计数)是 a、l 的话就判为类别 e,是 c、f、m、p、s、y 的话就判为类别 p,是 n 的话就再看样本的第 7 维、以此类推
虽说我这个决策树暂时不支持连续型特征,但相对应的它有一个好处:你不用把离散型数据处理成数值形式、而可以直接把它输入模型来训练。据我所知,scikit-learn 的 DecisionTreeClassifier 还不支持这一点(自豪脸)(然而人家比你快 1~2 倍)
公众号后台回复关键词学习
回复 人工智能 揭开人工智能的神秘面纱
回复 贝叶斯算法 贝叶斯算法与新闻分类
回复 机器学习 R&Python机器学习
回复 阿里数据 阿里数据系列课程
回复 Python Python机器学习案例实战
回复 Spark 征服Spark第一季
回复 kaggle 机器学习kaggle案例
回复 大数据 大数据系列视频
回复 数据分析 数据分析人员的转型
回复 数据挖掘 数据挖掘与人工智能
回复 机器学习 R&Python机器学习
回复 阿里数据 阿里数据系列课程
回复 R R&Python机器学习入门

