作者:射命丸咲 Python 与 机器学习 爱好者
知乎专栏:https://zhuanlan.zhihu.com/carefree0910-pyml
个人网站:http://www.carefree0910.com
往期阅读:
从零开始学人工智能(4)--Python · 神经网络(三)· 网络
从零开始学人工智能(5)--Python · 神经网络(四)· 网络
最终成品的 GitHub 地址:
https://github.com/carefree0910/MachineLearning/tree/master/NN
本章用到 CostLayer 和 Optimizers 的 GitHub 地址:
https://github.com/carefree0910/MachineLearning/blob/master/Zhihu/NN/Optimizers.py
&https://github.com/carefree0910/MachineLearning/blob/master/Zhihu/NN/Layers.py
对于许多机器学习算法来说,最终要解决的问题往往是最小化一个函数,我们通常称这个函数叫损失函数(https://zhuanlan.zhihu.com/p/24693332?refer=carefree0910-pyml)。在神经网络里面同样如此,损失函数层(CostLayer)和 Optimizers 因而应运而生(……),其中:
CostLayer 用于得到损失
Optimizers 用于最小化这个损失
需要一提的是,在神经网络里面,可以这样来理解损失:它是输入 x 经过前传算法后得到的输出和真实标签y 之间的差距。如何定义这个差距以及如何缩小这个差距会牵扯到相当多的数学知识,我们这里就只讲实现,数学层面的内容(有时间的话)(也就是说基本没可能)(喂)会在数学系列里面说明。感谢万能的 tensorflow,它贴心地帮我们定义好了损失函数和 Optimizers,所以我们只要封装它们就好了
以上,CostLayer 和 Optimizers 的定义、功能和实现就说得差不多了;再加上前几章,一个完整的、较朴素的神经网络就完全做好了,它支持如下功能:
自定义激活函数
任意堆叠 Layer
通过循环来堆叠重复的结构
通过准确率来评估模型的好坏

这不算是一个很好的模型、但已经具有了基本的雏形,走到这一步可以算是告一段落。接下来如果要拓展的话,大致流程会如下:
在训练过程中记录下当前训练的结果、从而画出类似这样的曲线:
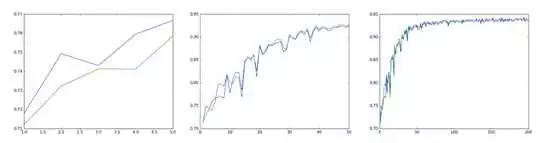
让模型支持比较大规模数据的训练,它包括几个需要改进的地方:
我们目前没有把数据分割成一个个小 batch 来训练我们的模型;但当数据量大起来的时候、这种处理是不可或缺的
我们目前做预测时是将整个数据扔给模型让它做前传算法的。数据量比较大时,这样做会引发内存不足的问题,为此我们需要分批前传并在最后做一个整合
我们目前没有进行交叉验证,这使我们的模型比较容易过拟合。虽然其实让用户自己去划分数据也可以,但留一个接口是好的习惯
最后也是最重要的,当然就是把我们的模型扩展成一个支持 CNN 模型了。这是一个巨坑、且容我慢慢来填……
看到这里的观众老爷们可能或多或少会有这样的感觉:这货不就是把 tensorflow 的那些东西封装了一下吗,如果我想了解算法细节该怎么办?没关系,正如我在第零章提到过的,我在带星号的章节中会说明我实现的纯 Numpy 算法,保证尽我所能地让所有观众老爷满意 ( σ'ω')σ
希望观众老爷们能够喜欢~
公众号后台回复关键词学习
回复 人工智能 揭开人工智能的神秘面纱
回复 贝叶斯算法 贝叶斯算法与新闻分类
回复 机器学习 R&Python机器学习
回复 阿里数据 阿里数据系列课程
回复 Python Python机器学习案例实战
回复 Spark 征服Spark第一季
回复 kaggle 机器学习kaggle案例
回复 大数据 大数据系列视频
回复 数据分析 数据分析人员的转型
回复 数据挖掘 数据挖掘与人工智能
回复 机器学习 R&Python机器学习
回复 阿里数据 阿里数据系列课程
回复 R R&Python机器学习入门



