作者:射命丸咲 Python 与 机器学习 爱好者
知乎专栏:https://zhuanlan.zhihu.com/carefree0910-pyml
个人网站:http://www.carefree0910.com
最终成品的 GitHub 地址:
https://github.com/carefree0910/MachineLearning/tree/master/NN
本章用到的 GitHub 地址:
https://github.com/carefree0910/MachineLearning/blob/master/Zhihu/NN/one/Network.py
从这一章开始就要讲第二个核心结构 神经网络(NN)的实现了。这一部分是个有点大的坑,我会尽我所能地一一说明。在这一章里面,我们会说明如何把整个神经网络的结构搭建起来
援引之前用过的一张图:
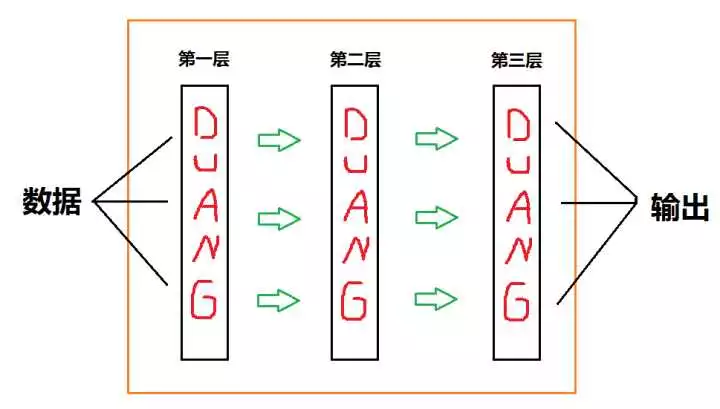 可以看到,如果不去管接口怎么写的话,因为我们已经处理好了 Layer,所以我们还需要处理的东西其实有一个:
可以看到,如果不去管接口怎么写的话,因为我们已经处理好了 Layer,所以我们还需要处理的东西其实有一个:
在我们现在准备实现的朴素结构里面,绿箭头的部分只有两个东西:权重 和 偏置量
所以我们就来实现它们~
在贴出代码前,需要先说明一下接下来代码里面的 shape 是个什么东西。事实上,它记录了上一层神经元个数与该层神经元个数。具体而言,有:
shape[0] 是上一层神经元个数
shape[1] 是该层神经元个数
从而 shape 这个变量起到了承上启下的重要作用,请观众老爷们把它的定义牢记于心 ( σ'ω')σ
接下来是具体实现(这里用到了一些 tensorflow 的函数,可以暂时先用着)(喂):
根据 shape 获得初始权重
def _get_w(self, shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial, name="w")
根据 shape 获得初始偏置量
def _get_b(self, shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial, name="b")
我们再来想一想,在搭建一个网络时,操作顺序是什么?
还是上面那张图,可以看到搭建顺序应该是:加入一个 Layer → 加入绿箭头 → 加入一个 Layer → 加入绿箭头 → ……
所以我们接下来要做的只有两个:加入 Layer 和 加入绿箭头(这个人废话怎么这么多)
先讲怎么加入绿箭头、因为加入 Layer 的过程中会用到这一步。相信观众老爷们已经或多或少有些感觉了,这里就直接贴出代码:
def _add_weight(self, shape):
w_shape = shape
b_shape = shape[1],
self._tf_weights.append(self._get_w(w_shape))
self._tf_bias.append(self._get_b(b_shape))
因为很重要所以再提一下(这人好啰嗦):shape[0] 是上一层神经元个数而 shape[1] 是该层神经元个数。这也是为什么偏置量的形状是 shape[1]
可能观众老爷们注意到了,代码中出现了没见过的 self._tf_weights 和 self._tf_bias。相信大家也都猜到了:这两个列表就是存着所有权重和偏置量的列表,可谓是整个结构的核心之一
再讲怎么加入 Layer。不考虑接口的话,加入 Layer 是一个平凡的过程:
def add(self, layer):
if not self._layers:
self._layers, self._current_dimension = [layer], layer.shape[1]
self._add_weight(layer.shape)
else:
_next = layer.shape[0]
self._layers.append(layer)
self._add_weight((self._current_dimension, _next))
self._current_dimension = _next
解释一下代码的逻辑:
如果是第一次加入 Layer 的话,创建一个含有该 Layer 的列表(self._layers),同时用一个变量(self._current_dimension)把 Layer 的 shape[1] 记录下来(当我们第一次加入 Layer 时,shape[0] 代表着输入数据的维度,shape[1] 代表着第一层神经元的个数)
如果不是第一次加入的话,由于没有考虑接口设计,我们需要作这样的约定:
在该约定下,上面代码的逻辑就比较清晰了;为简洁,我就不再赘述(其实还是懒)(喂
从第二次加入 Layer 开始,Layer 的 shape 变量都是长度为 1 的元组,其唯一的元素记录的就是该 Layer 中神经元的个数
比如说,如果我想设计一个含有一层隐藏层、24 个神经元的结构,我就要这样做:
nn.add(ReLU((x.shape[1], 24)))nn.add(CrossEntorpy((y.shape[1], )))
这里面出现的 CrossEntropy 是损失函数层(CostLayer),目前暂时没有讲到、不过它也继承了 Layer,目前来说可以简单地把它看成一个普通的 Layer
那么稍微总结一下:
朴素的网络结构只需要重复做两件事:加入 Layer 和加入绿箭头。其中,绿箭头的本质是层与层之间的关联,它根据 shape 生成相应的权重和偏置量
一般来说,shape 记录的是上一层的神经元个数和这一层神经元个数(否则它记录的会是这一层神经元的个数),它起到了重要的承上启下的作用
希望观众老爷们能够喜欢~
公众号后台回复关键词学习
回复 人工智能 揭开人工智能的神秘面纱
回复 贝叶斯算法 贝叶斯算法与新闻分类
回复 机器学习 R&Python机器学习
回复 阿里数据 阿里数据系列课程
回复 Python Python机器学习案例实战
回复 Spark 征服Spark第一季
回复 kaggle 机器学习kaggle案例
回复 大数据 大数据系列视频
回复 数据分析 数据分析人员的转型
回复 数据挖掘 数据挖掘与人工智能
回复 机器学习 R&Python机器学习
回复 阿里数据 阿里数据系列课程
回复 R R&Python机器学习入门

