本人一直向往那种指点江山的人的霸气,却只能望其项背,从未能够达到。最近R语言大会开的如火如荼,一场又一场不停歇,可惜我都没有去参加,那都是牛人、大咖的海天盛宴啊。每每看到大咖在群里说bootstrap、随机森林、决策树、支持向量机之类的,都感觉无比的崇拜。如果有一天能够和他们坐在一起聊人生应该是件非常不错的事情,如果能够成为小伙伴,那就再好不过了,当然这些都是奢望了。周六拒绝了一切的邀约,在图书馆泡了一天,下定决心去研究一下这方面的问题,给自己一个交代。
一、问题的起源
人们常常需要基于一组变量预测一个分类结果,如在银行风险控制当中,经常会根据个人信息和交易流水预测其是否会还贷,然而更常见的情况可能就是你想在搜索引擎里搜一下你感兴趣的话题,浏览器却告诉你,根据法律法规相关规定…,这些都是今天所要讨论的分类问题。分类的目的是通过某种方法实现对新出现单元的准确分类。分类的方法有很多,比如逻辑回归、决策树、随机森林、支持向量机等。
二、各种方法初尝
本文所使用的数据可以从以下这个网址下载:http://archive.ics.uci.edu/ml/machine-learning-databases/,将数据读到R中,查看数据,数据的变量没有命名,根据数据的说明进行命名,并删除第一列的ID。

将class转换为因子,并赋予“良性(benign)”,“恶性(malignant)”标签。数据的70%作为训练集,剩余的30%作为验证集。设置随机种子,以便结果再现。
> set.seed(1234)
> train <- sample(nrow(df), 0.7*nrow(df))
> df.train <- df[train,]
> df.validate <- df[-train,]
(一)逻辑回归
建立逻辑回归模型,并查看模型拟合结果可以看到并非所有的变量都显著。这时可以采用逐步回归方法,更新模型,并利用模型对验证集进行预测。概率大于0.5的为恶性肿瘤,概率小于0.5的为良性肿瘤。可以看到,良性被误判为恶性的有2例,恶性被误判为良性的有3例,,正确分类的模型(即准确率,accuracy)为0.975。
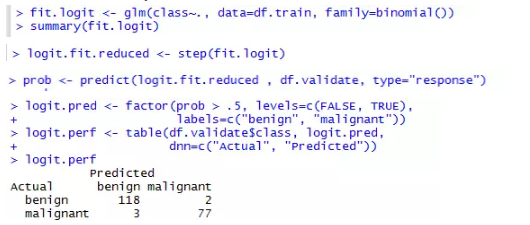
> sum(diag(logit.perf))/sum(logit.perf)
[1] 0.975
(二)决策树
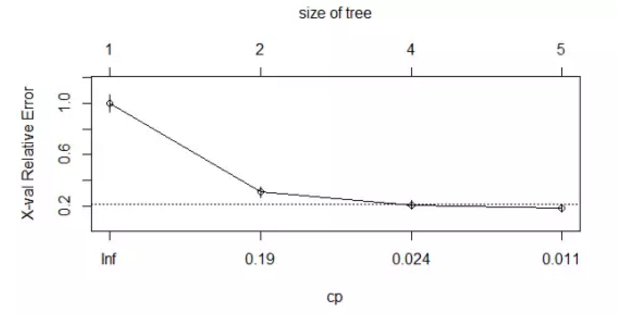
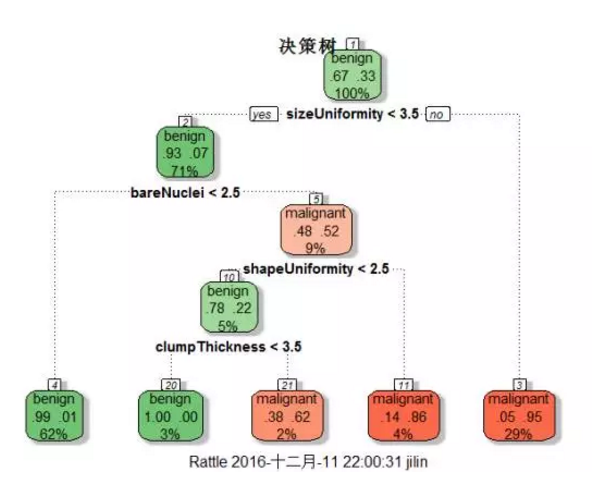
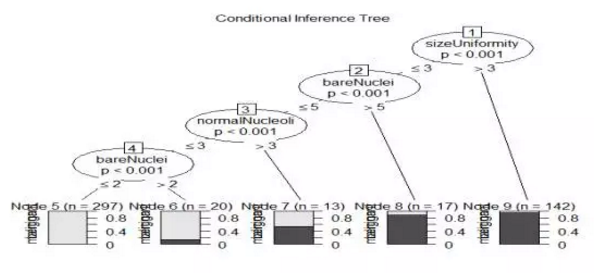
决策树是数据挖掘领域中的常用模型。其基本思想是对预测变量进行二元分离,从而构造一棵可用于预测新样本单元所属类别的树。R中的rpart包支持rpart()函数构造决策树,prune()函数对决策树进行剪枝。生成决策树,查看复杂度参数的值,选择树的大小,然后对树进行剪枝,并画出剪枝后的决策树,最后利用predict函数对验证集进行预测,验证集中的准确率达到了96%。也可以利用party包生成条件推断树。
> dtree <- rpart(class ~ ., data=df.train, method="class",
+ parms=list(split="information"))
dtree$cptable
CP nsplit rel error xerror xstd
1 0.800000 0 1.00000 1.00000 0.06484605
2 0.046875 1 0.20000 0.30625 0.04150018
3 0.012500 3 0.10625 0.20625 0.03467089
4 0.010000 4 0.09375 0.18125 0.03264401
> plotcp(dtree)
> dtree.pred <- predict(dtree.pruned, df.validate, type="class")
> dtree.perf <- table(df.validate$class, dtree.pred,
+ dnn=c("Actual", "Predicted"))
> dtree.perf
Predicted
Actual benign malignant
benign 122 7
malignant 2 79
> sum(diag(dtree.perf))/sum(dtree.perf)
[1] 0.9571429
(三)随机森林
随机森林(random forest)是一种组成式的有监督学习方法。在随机森林中,我们同时生成多个预测模型,并将模型的结果汇总以提升分类准确率。最近统计之都上刊发了对Leo Breiman有一个专访,有兴趣可以去看一下。 用randomForest()生成随机森林,每个节点选择3个变量,共500棵树。用importance函数输出每个变量的重要性,可以看到sizeUniformity 是最重要的变量,与前面画的决策树图形是吻合的。最后利用predict函数做预测,准确率达
98%.
> set.seed(1234)
> fit.forest <- randomForest(class~., data=df.train,
+ na.action=na.roughfix,
+ importance=TRUE)
> importance(fit.forest, type=2)
MeanDecreaseGini
clumpThickness 12.504484
sizeUniformity 54.770143
shapeUniformity 48.662325
maginalAdhesion 5.969580
singleEpithelialCellSize 14.297239
bareNuclei 34.017599
blandChromatin 16.243253
normalNucleoli 26.337646
mitosis 1.814502
> forest.pred <- predict(fit.forest, df.validate)
> forest.perf <- table(df.validate$class, forest.pred,
+ dnn=c("Actual", "Predicted"))
> forest.perf
Predicted
Actual benign malignant
benign 117 3
malignant 1 79
> sum(diag(forest.perf))/sum(forest.perf)
[1] 0.98
(四)支持向量机
支持向量机(SVM)是一类可用于分类和回归的有监督机器学习模型。其流行归功于两个方面:一方面,他们可输出较准确的预测结果;另一方面,模型基于较优雅的数学理论。SVM旨在在多维空间中找到一个能将全部样本单元分成两类的最优平面,这一平面应使两类中距离最近的点的间距(margin)尽可能大,在间距边界上的点被称为支持向量(support vector,它们决定间距),分割的超平面位于间距的中间。支持向量机用e1071包中的svm()函数实现,预测准确率达96.5%。
> library(e1071)
> set.seed(1234)
> fit.svm <- svm(class~., data=df.train)
> svm.pred <- predict(fit.svm, na.omit(df.validate))
> svm.perf <- table(na.omit(df.validate)$class,
+ svm.pred, dnn=c("Actual", "Predicted"))
> svm.perf
Predicted
Actual benign malignant
benign 116 4
malignant 3 77
> sum(diag(svm.perf))/sum(svm.perf)
[1] 0.965
至此,基本的分类方法都已经介绍完毕。随机森林的分类准确率通常更高。
另外,随机森林算法可处理大规模问题(即多样本单元、多变量),可处理训练集中有大量缺失值的数据,也可应对变量远多于样本单元的数据。可计算袋外预测误差、度量变量重要性也是随机森林的两个明显优势。随机森林的一个明显缺点是分类方法(此例中相当于500棵决策树)较难理解和表达。另外,我们需要存储整个随机森林以对新样本单元分类。与随机森林算法不同的是,SVM在预测新样本单元时不允许有缺失值出现。
三、rattle数据挖掘
最后,介绍一个可视化的数据挖掘工具——rattle。加载rattle包,调用rattle()函数,调出数据挖掘界面,点击相应的菜单即可进行相应的数据挖掘,对于重复,傻瓜式操作比较简单。值得一提的时,在日志中会自动生成相应的代码,可以参考执行过程,也可以进行相应的可视化,这里不再赘述。
> library(rattle)
> rattle()
本文作者:王吉林 如有疑问可以扫一扫作者二维码,沟通交流。



