前些日子,一位贾姓朋友加我微信,问R语言中数据管理的问题,其实多多少少在前面的几篇文当中都有涉及了,今天索性来个系统的介绍,以抛砖引玉,还请各位大神不吝赐教。今天要讲的内容主要分成两个部分,基本数据管理和高级数据管理。
一、基本数据管理
我们都知道数据分析的前提就是把数据处理好。数据的读写之前已经说过,这里不再赘述。今天我们只谈将数据读入到R中以后,怎么对数据进行各种处理。基本的数据管理主要介绍以下几个方面:日期和缺失值的处理,数据类型的转换、变量的创建和重编码、数据的排序、数据的合并与取子集、变量筛选与删除。
(一)缺失值和日期的处理
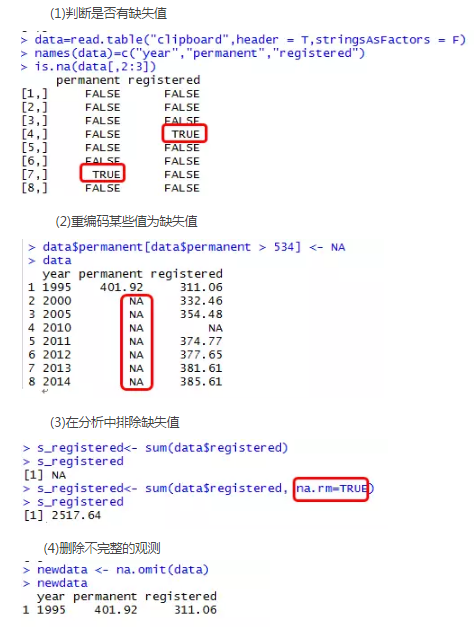
1、缺失值的处理
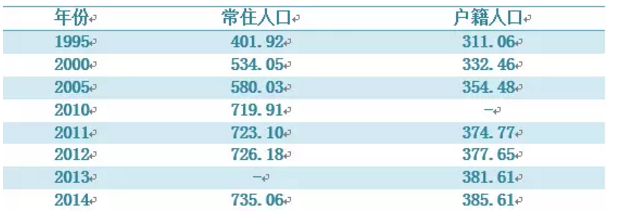
在现实生活中,任何数据集的采集都可能由于未回答、设备故障或漏登记的缘故而不完整,出现缺失值。在R中,缺失值以符号NA(Not Available,不可用)表示。R提供了一些函数,用于识别包含缺失值的观测,比如is.na(),当然在一些函数中,也会有处理缺失值的参数,例如mean(x, trim = 0, na.rm = FALSE, ...)。假设我们有以下数据集(人口及其构成),可以看到,数据中含有缺失值。
人口及其构成(万人)
2、日期的处理
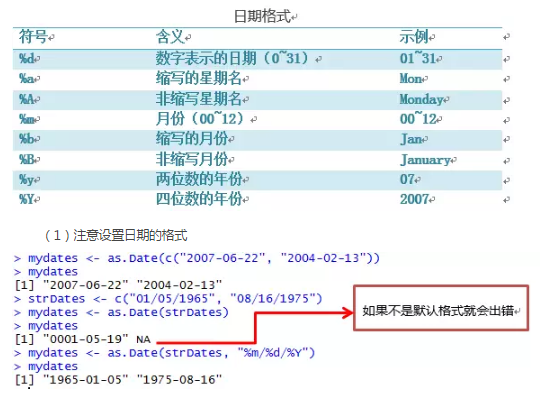
日期值通常以字符串的形式输入到R中,然后转化为以数值形式存储的日期变量。函数as.Date()用于执行这种转化。日期值的默认输入格式为yyyy-mm-dd。日期的常用格式详见(日期格式表)。
(2)两个实用函数
有两个函数对于处理时间戳数据特别实用。Sys.Date()可以返回当天的日期, date()则返回当前的日期和时间。可以看到,我写这篇的文章已经是晚上9点多了,好苦逼有没有,但是我乐于分享的精神鼓励着我继续前进。
(3)指定输出格式
你可以使用函数format(x, format="output_format")来输出指定格式的日期值,并且可以提取日期值中的某些部分。

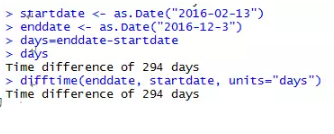
(4)计算日期差
计算两个日期之间的时间间隔,可以直接相减,也可以使用函数difftime()来计算时间间隔,并以星期、天、时、分、秒来表示。详情请查看函数帮助
(二)数据类型的转换
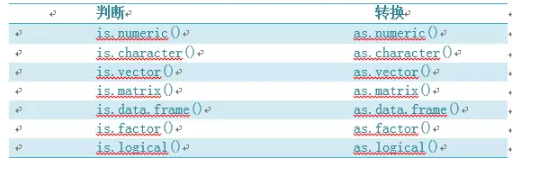
R与其他统计编程语言有着类似的数据类型转换方式。举例来说,向一个数值型向量中添加一个字符串会将此向量中的所有元素转换为字符型。

(三)变量的创建和重编码
如果我们需要根据城市的常住人口数进行城市等级的划分,将常住人口超过700万(含)的命名为大型城市,大于等于300万小于700万的为中等城市,以此类推,这就需要重编码数据,可以使用R中的一个或多个逻辑运算符来处理。这里要注意within函数的用法,与with类似,不同的是它允许你修改数据。

前的人口数据按照人口进行排序。

(五)数据的合并与取子集
如果数据分散在多个地方,你就需要在分析之前将其合并。在多数情况下,两个数据框是通过一个或多个共有变量进行联结的。要横向合并两个数据框,用merge()函数。另外用cbind()进行横向合并,用rbind()实现纵向合并两个数据框。例如

取数据的子集可以用列标,行标来限制,比如data[,1:3]即为取数据data的1-3列数据。同样也可以用subset()函数来取数据的子集。比如之前的人口数据。

对数据进行抽样用sample(),sample函数能够让你从数据集中(有放回或无放回地)抽取大小为n的一个随机样本。例如(请随手设置随机种子,以实现结果再现)

(六)变量筛选与删除。
变量的删除很简单,可以用列标来操作,比如data[,-1]即删除第一列,当然你也可以用sql语句进行筛选,例如

二、高级数据管理
前面介绍了一些数据操作的基本方法,如果对数据进行更高级的管理,则需要用到一些系统自带函数,包括统计函数、数学函数、字符串函数、概率分布函数等等(前面有篇文章已经列出了各种类型的函数的作用,有需要的可以回头翻看),当然你也可以通过自定义函数对数据进行处理。transform(),quantile(),scale()、substr(),grep(),sub(),strsplit(),paste(),pretty(),cat(),apply(),lapply()和sapply(),这些函数在数据处理,特别是字符的处理中非常有用,在网络爬虫中也经常用到,具体用法请查看函数帮助。
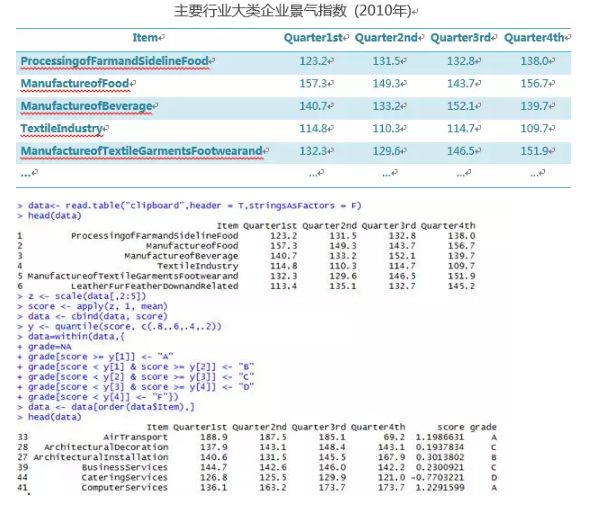
下面举一个例子。假设我们有主要行业的大类企业景气指数,我们希望确定一个综合的指标进行等级设定,并且按照行业的字母顺序进行排序,如何操作呢?
再举一个网络爬虫的例子。比如我们想看看顺德拉手网上电影的基本情况。我们抓取了网页的数据后,可以用head函数查看数据的情况。

然后利用前面介绍的函数,将电影院的名字,电影院的地址,销售量等数据取出来,这里需要用到正则表达式的内容(如果不懂正则表达式,网上都有很多参考书的啦,后期情况允许,我也会举例来详细介绍)。

可以看到,如果电影都按原价销售,估计我们都看不起电影了,哈哈,这世界充满了噱头。

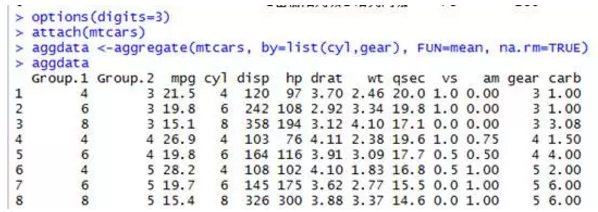
最后介绍一下reshape2包。以前整合数据常用aggregate(x,by, FUN),其中x是待折叠的数据对象,by是一个变量名组成的列表,这些变量将被去掉以形成新的观测,而FUN则是用来计算描述性统计量的标量函数,它将被用来计算新观测中的值。例如根据汽缸数和挡位数整合mtcars数据,并返回各个数值型变量的均值
有了reshape2包之后,可以更加灵活对数据进行重构。在reshape2包中有两个概念,一个是融合,一个是重铸。例如有以下数据,对数据进行融合。
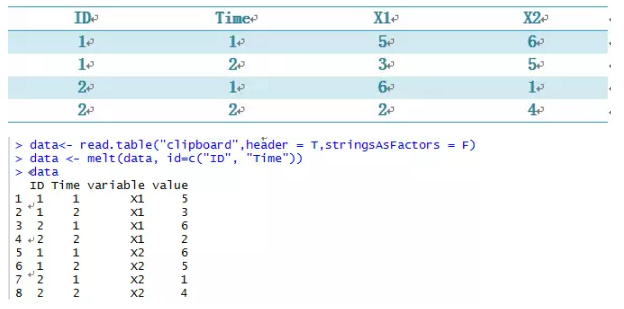
对融合后的数据进行重构。

最后的最后,回答一下黄帮主的问题,怎么画简单的网络图,除了igraph包外,还有一个包networkD3比较有意思。当然这两个包是绘制的图形是可以交互的,当然下面的左图是用simpleNetwork()画的,更复杂的网络图(如右图),请参考这个包说明文档。