
本文作者:王吉林
(十一)指数分布
指数函数的一个重要特征是无记忆性(Memoryless Property,又称遗失记忆性)。这表示如果一个随机变量呈指数分布,当s,t>0时有P(T>t+s|T>t)=P(T>s)。即,如果T是某一元件的寿命,已知元件使用了t小时,它总共使用至少s+t小时的条件概率,与从开始使用时算起它使用至少s小时的概率相等。密度函数为f(x) = λe^(-λx), 期望值:1/λ方差:1/。在R语言中有:
密度函数:dexp(x, rate = 1, log = FALSE)
分布函数:pexp(q, rate = 1, lower.tail = TRUE, log.p = FALSE)
求分位数:qexp(p, rate = 1, lower.tail = TRUE, log.p = FALSE)
生成随机数:rexp(n, rate = 1)
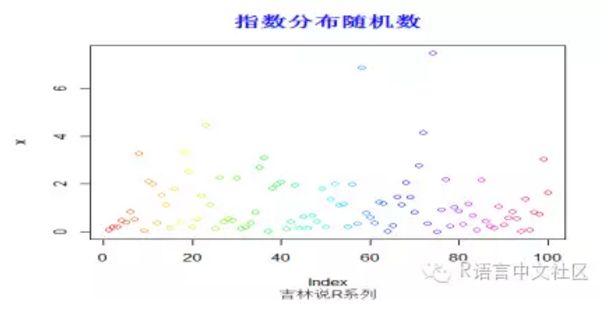
> #生成随机数
> set.seed(200)
> x=rexp(100,0.8)
> plot(x,col=rainbow(100))
> title("指数分布随机数",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
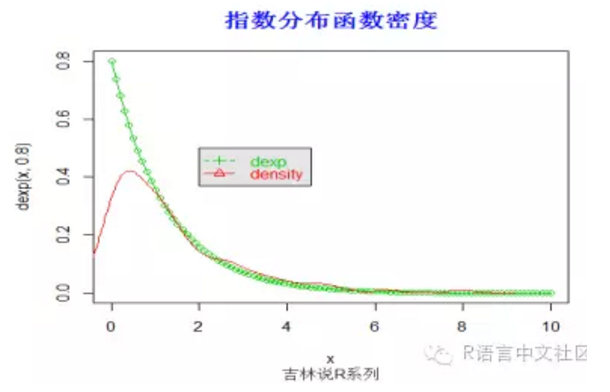
> #密度函数
> set.seed(20)
> x=seq(0,10,length=100)
> plot(x,dexp(x,0.8),type='o',col=3)
> y=rexp(100, 0.8)
> lines(density(y), col =2)
> legend(2,0.5,
+ c("dexp", "density"), col = c(3, 2),
+ text.col = c(3,2), lty = c(2, 1), pch = c(3, 2),
+ merge = TRUE, bg = "gray90")
> title("指数分布函数密度",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
 ‘
‘
’
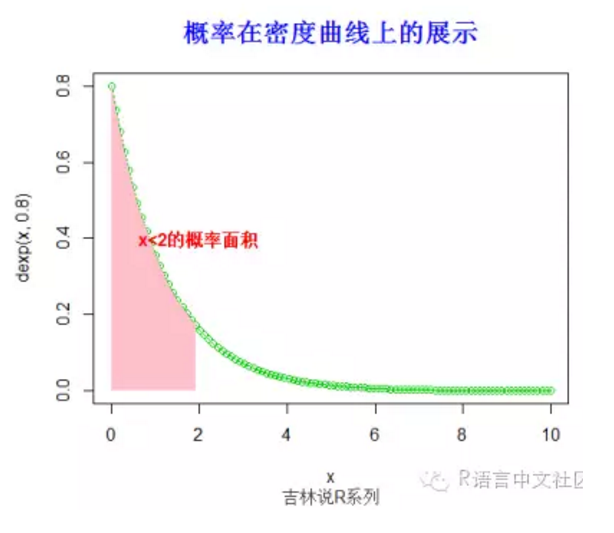
> #求概率(x< 2),并绘制相应的阴影。
> pexp(2,0.8)
[1] 0.7981035
> x=seq(0,10,length=100)
> plot(x,dexp(x,0.8),type='o',col=3)
> fill.y=dexp(x,0.8)
> fill.y=fill.y[x< 2]
> fill.x=x[x< 2]
> fill.x=c(fill.x[1],fill.x,tail(fill.x,1))
> fill.y=c(0,fill.y,0)
> polygon(fill.x, fill.y,col = "pink", density=-1,lty="blank")
> title("概率在密度曲线上的展示",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
> text(2,0.4,"x<2的概率面积",col="red",font=2)
#求分位数
> qexp(seq(0,1,length=10),0.8)
[1] 0.0000000 0.1472288 0.3141430 0.5068314 0.7347333 1.0136628 1.3732654 1.8800967 2.7465307 Inf
(十二)F分布
F分布是1924年英国统计学家R.A.Fisher提出,并以其姓氏的第一个字母命名的。F分布定义为:设X、Y为两个独立的随机变量,X服从自由度为n1的卡方分布,Y服从自由度为n2的卡方分布,这2 个独立的卡方分布被各自的自由度除以后的比率这一统计量的分布。其概率密度为:
f(x) = Γ((n1 + n2)/2) / (Γ(n1/2) Γ(n2/2)) (n1/n2)^(n1/2) x^(n1/2 - 1) (1 + (n1/n2) x)^-(n1 + n2)/2, x > 0。
期望为:E(X)=n2/(n2-2),n>2。
方差为:D(X)=[2n2^2*(n1+n2-2)]/[n1(n2-2)^2*(n2-4)], n2>4。在R语言中有:
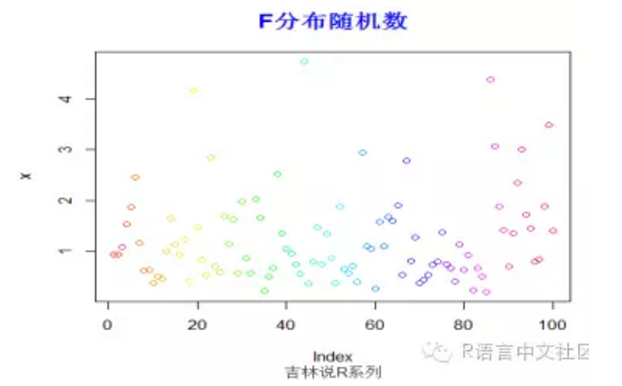
> #生成随机数
> set.seed(200)
> x=rf(100,10,10)
> plot(x,col=rainbow(100))
> title("F分布随机数",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
> #密度函数
> set.seed(20)
> x=seq(0,10,length=100)
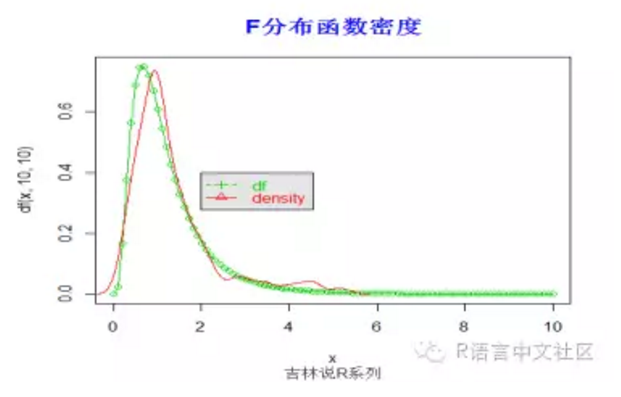
> plot(x,df(x,10,10),type='o',col=3)
> y=rf(100, 10,10)
> lines(density(y), col =2)
> legend(2,0.4,
+ c("df", "density"), col = c(3, 2),
+ text.col = c(3,2), lty = c(2, 1), pch = c(3, 2),
+ merge = TRUE, bg = "gray90")
> title("F分布函数密度",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
#概率在密度曲线上的展示
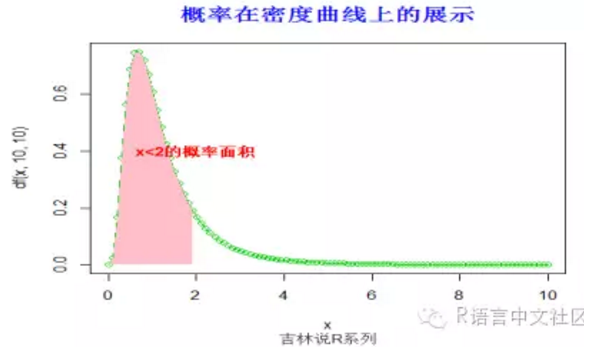
> pf(2,10,10)
[1] 0.8551542
> x=seq(0,10,length=100)
> plot(x,df(x,10,10),type='o',col=3)
> fill.y=df(x,10,10)
> fill.y=fill.y[x< 2]
> fill.x=x[x< 2]
> fill.x=c(fill.x[1],fill.x,tail(fill.x,1))
> fill.y=c(0,fill.y,0)
> polygon(fill.x, fill.y,col = "pink", density=-1,lty="blank")
> title("概率在密度曲线上的展示",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
> text(2,0.4,"x<2的概率面积",col="red",font=2)
#求分位数
> qf(seq(0,1,length=10),10,10)
[1] 0.0000000 0.4486100 0.6075356 0.7559781 0.9133750 1.0948406 1.3227896 1.6459942 2.2291075 Inf
(十三)t分布
设X1服从标准正态分布N(0,1),X2服从自由度为n的χ2分布,且X1、X2相互独立,则称变量T=X1/(X2/n)^(1/2),所服从的分布为自由度为n的t分布。期望 E(T)=0 ,方差 D(T)=n/(n-2),n>2。在R语言中有:
密度函数:dt(x, df, ncp, log = FALSE)
分布函数:pt(q, df, ncp, lower.tail = TRUE, log.p = FALSE)
求分位数:qt(p, df, ncp, lower.tail = TRUE, log.p = FALSE)
生成随机数:rt(n, df, ncp)
> #生成随机数
> set.seed(200)
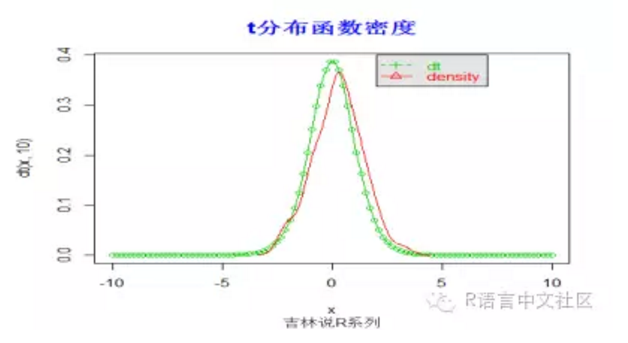
> x=rt(100,10)
> plot(x,col=rainbow(100))
> title("t分布随机数",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
> #求概率(x< 2),并绘制相应的阴影。
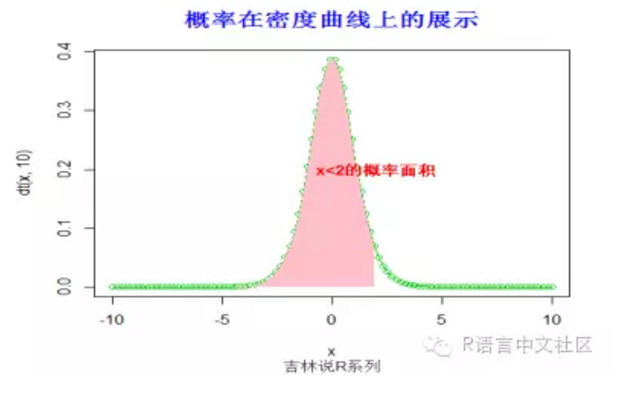
> pt(2,10)
[1] 0.963306
> x=seq(-10,10,length=100)
> plot(x,dt(x,10),type='o',col=3)
> fill.y=dt(x,10)
> fill.y=fill.y[x< 2]
> fill.x=x[x< 2]
> fill.x=c(fill.x[1],fill.x,tail(fill.x,1))
> fill.y=c(0,fill.y,0)
> polygon(fill.x, fill.y,col = "pink", density=-1,lty="blank")
> title("概率在密度曲线上的展示",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
> text(2,0.2,"x<2的概率面积",col="red",font=2)
#求分位数
> qt(seq(0,1,length=10),10)
[1] -Inf -1.3016504 -0.7961309 -0.4437559 -0.1433140 0.1433140 0.4437559 0.7961309 1.3016504 Inf
(十四)泊松分布
当一个随机事件,例如某电话交换台收到的呼叫(来到某公共汽车站的乘客、某放射性物质发射出的粒子、显微镜下某区域中的白血球等等),以固定的平均瞬时速率λ随机且独立地出现时,那么这个事件在单位时间内出现的次数或个数就近似地服从泊松分布P(λ)。因此,泊松分布在管理科学、运筹学以及自然科学的某些问题中都占有重要的地位。
其密度函数为:p(x) = λ^x exp(-λ)/x!,
期望和方差为:E(X) = Var(X) = λ。在R语言中有:
密度函数:dpois(x, lambda, log = FALSE)
分布函数:ppois(q, lambda, lower.tail = TRUE, log.p = FALSE)
求分位数:qpois(p, lambda, lower.tail = TRUE, log.p = FALSE)
生成随机数:rpois(n, lambda)
> #生成随机数
> set.seed(200)
> x=rt(100,10)
> plot(x,col=rainbow(100))
> title("泊松分布随机数",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
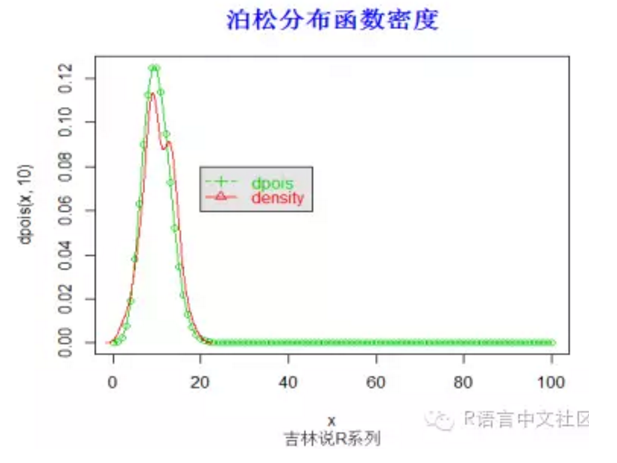
> #密度函数
> set.seed(20)
> x=seq(0,100,by=1)
> plot(x,dpois(x,10),type='o',col=3)
> y=rpois(100,10)
> lines(density(y), col =2)
> legend(20,0.08,
+ c("dpois", "density"), col = c(3, 2),
+ text.col = c(3,2), lty = c(2, 1), pch = c(3, 2),
+ merge = TRUE, bg = "gray90")
> title("泊松分布函数密度",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
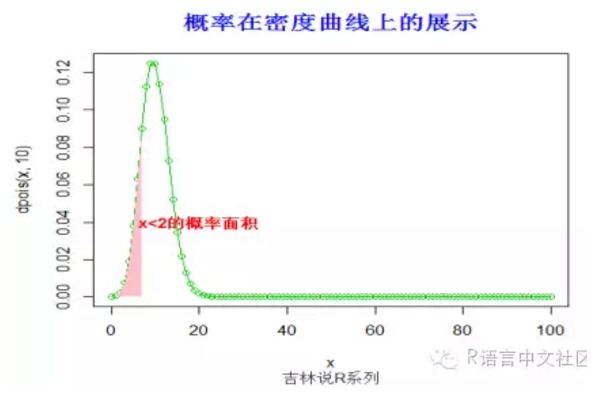
> ppois(7,10)
[1] 0.2202206
> x=seq(0,100,by=1)
> plot(x,dpois(x,10),type='o',col=3)
> fill.y=dpois(x,10)
> fill.y=fill.y[x< 8]
> fill.x=x[x< 8]
> fill.x=c(fill.x[1],fill.x,tail(fill.x,1))
> fill.y=c(0,fill.y,0)
> polygon(fill.x, fill.y,col = "pink", density=-1,lty="blank")
> title("概率在密度曲线上的展示",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
> text(20,0.04,"x<2的概率面积",col="red",font=2)
##求分位数
> qpois(seq(0,1,length=10),10)
[1] 0 6 8 9 9 10 11 12 14 Inf
(十五)均匀分布
连续型随机变量X的概率密度函数为,则称随机变量X服从[a,b]上的均匀分布,记为X~U(a,b)。其期望为(a+b)/2,方差为:(b-a)^2/12。在R语言中有:
密度函数:dunif(x, min = 0, max = 1, log = FALSE)
分布函数:punif(q, min = 0, max = 1, lower.tail = TRUE, log
p = FALSE)
求分位数:qunif(p, min = 0, max = 1, lower.tail = TRUE, log.p = FALSE)
生成随机数:runif(n, min = 0, max = 1)
#生成随机数
> set.seed(200)
> x=runif(100,1,5)
> plot(x,col=rainbow(100))
> title("均匀分布随机数",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
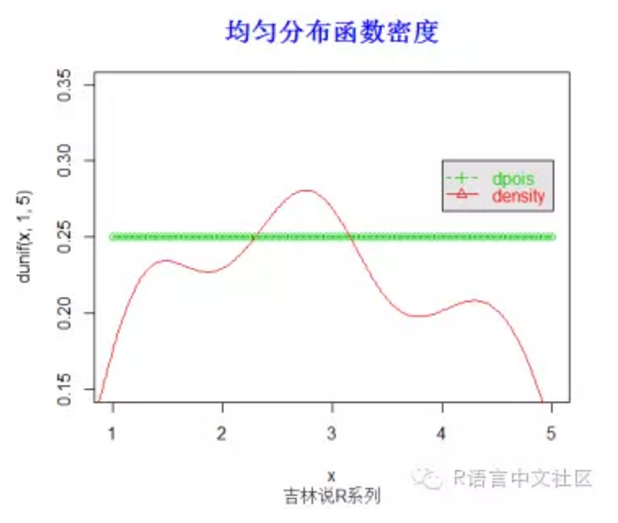
> #密度函数
> set.seed(20)
> x=seq(1,5,length=100)
> plot(x,dunif(x,1,5),type='o',col=3)
> y=runif(100,1,5)
> lines(density(y), col =2)
> legend(4,0.3,
+ c("dpois", "density"), col = c(3, 2),
+ text.col = c(3,2), lty = c(2, 1), pch = c(3, 2),
+ merge = TRUE, bg = "gray90")
> title("均匀分布函数密度",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
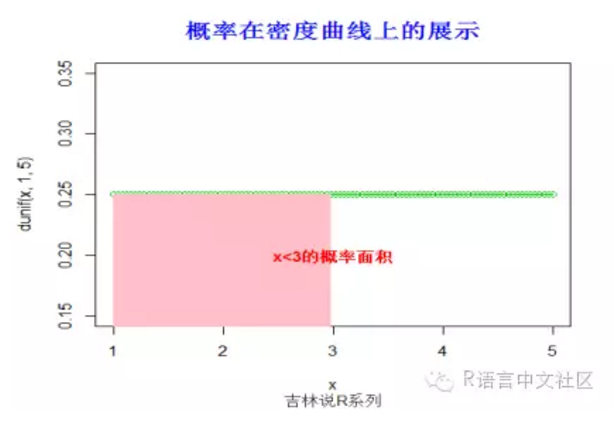
> #求概率(x< 3),并绘制相应的阴影。
> punif(3,1,5)
[1] 0.5
> x=seq(1,5,length=100)
> plot(x,dunif(x,1,5),type='o',col=3)
> fill.y=dunif(x,1,5)
> fill.y=fill.y[x< 3]
> fill.x=x[x< 3]
> fill.x=c(fill.x[1],fill.x,tail(fill.x,1))
> fill.y=c(0,fill.y,0)
> polygon(fill.x, fill.y,col = "pink", density=-1,lty="blank")
> title("概率在密度曲线上的展示",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
> text(3,0.2,"x<3的概率面积",col="red",font=2)
> #求分位数
> qunif(seq(0,1,length=10),1,5)
[1] 1.000000 1.444444 1.888889 2.333333 2.777778 3.222222 3.666667 4.111111 4.555556 5.000000
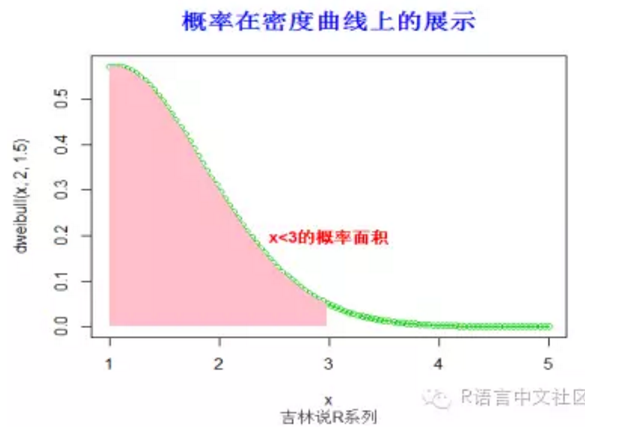
(十六)韦布尔分布
从概率论和统计学角度看,Weibull Distribution是连续性的概率分布,其概率密度为:f(x) = (a/b) (x/b)^(a-1) exp(- (x/b)^a),当b=1,它是指数分布。
期望为:E(X) = b Γ(1 + 1/a),
方差为:Var(X) = b^2 * (Γ(1 + 2/a) - (Γ(1 + 1/a))^2)。在R语言中有:
密度函数:dweibull(x, shape, scale = 1, log = FALSE)
分布函数:pweibull(q, shape, scale = 1, lower.tail = TRUE, log.p = FALSE)
求分位数:qweibull(p, shape, scale = 1, lower.tail = TRUE, log.p = FALSE)
生成随机数:rweibull(n, shape, scale = 1)
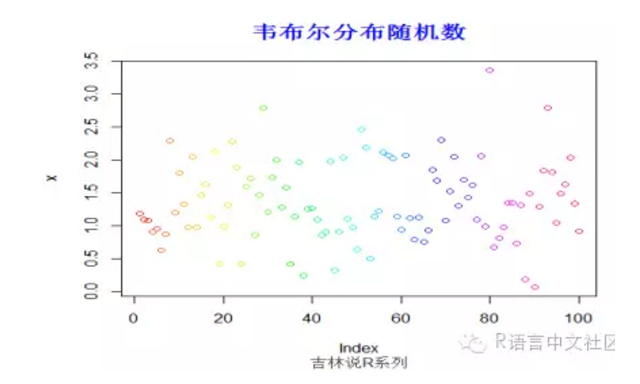
#生成随机数
> set.seed(200)
> x=rweibull(100,2,1.5)
> plot(x,col=rainbow(100))
> title("韦布尔分布随机数",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
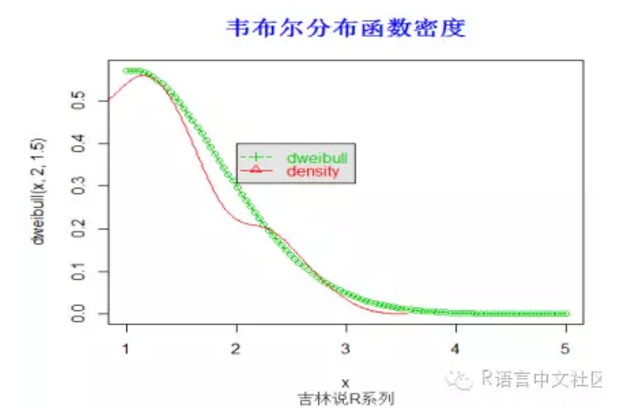
> #密度函数
> set.seed(112)
> x=seq(1,5,length=100)
> plot(x,dweibull(x,2,1.5),type='o',col=3)
> #plot(x,dexp(x,1),type='o',col=3)#当形状参数为1时是指数分布。
> y=rweibull(100,2,1.5)
> lines(density(y), col =2)
> legend(2,0.4,
+ c("dweibull", "density"), col = c(3, 2),
+ text.col = c(3,2), lty = c(2, 1), pch = c(3, 2),
+ merge = TRUE, bg = "gray90")
> title("韦布尔分布函数密度",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
> #求概率(x< 3),并绘制相应的阴影。
> pweibull(3,2,1.5)
[1] 0.9816844
> x=seq(1,5,length=100)
> plot(x,dweibull(x,2,1.5),type='o',col=3)
> fill.y=dweibull(x,2,1.5)
> fill.y=fill.y[x< 3]
> fill.x=x[x< 3]
> fill.x=c(fill.x[1],fill.x,tail(fill.x,1))
> fill.y=c(0,fill.y,0)
> polygon(fill.x, fill.y,col = "pink", density=-1,lty="blank")
> title("概率在密度曲线上的展示",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
> text(3,0.2,"x<3的概率面积",col="red",font=2)
二、数据处理
(一)数据类型
按照本人的理解(并不一定严格的科学),数据结构的呈现可以分为几种形式,向量、矩阵、数组、列表、数据框等。组成上述数据的元素可以是numeric(数值型)、logical(逻辑型)、character(字符型)、复数型(complex)。
(二)数据的运算
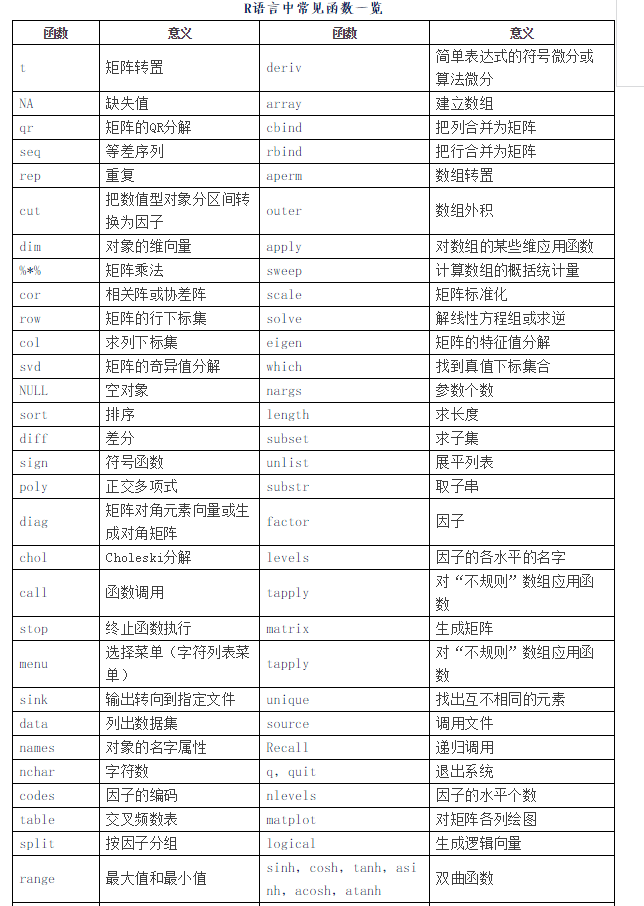
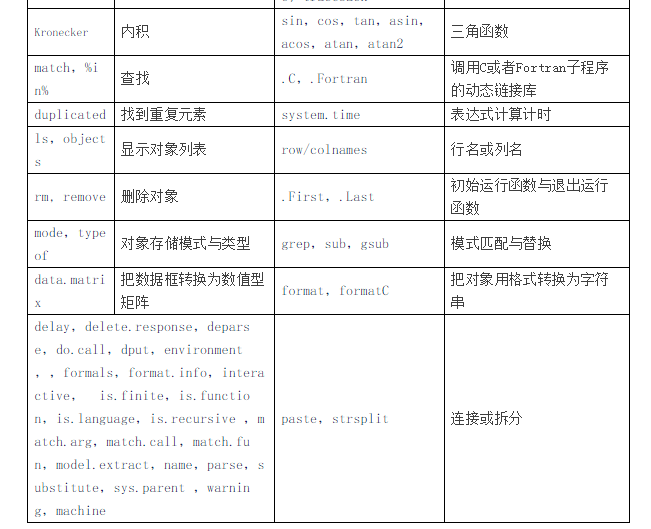
数据的运算主要有四则运算、下标运算、删除/添加元素、排序、子集等等。在数据的处理过程中,经常涉及的主要函数有:c(),list(),data.frame()等,本人根据自己的经验,搜集整理了一些常用的函数,如下表(具体怎么用,可以用“?函数名”形式获取帮助,查看示例或者百度、Google):

三、蒙特卡罗方法
蒙特卡罗(Monte Carlo)方法,又称随机抽样或统计试验方法,属于计算数学的一个分支,它是在上世纪四十年代中期为了适应当时原子能事业的发展而发展起来的。传统的经验方法由于不能逼近真实的物理过程,很难得到满意的结果,而蒙特卡罗方法由于能够真实地模拟实际物理过程,故解决问题与实际非常符合,可以得到很圆满的结果。蒙特卡罗的方法应用场景非常广泛,这是本文需要介绍给大家的一个重要原因。本文只是简单的举一个小例子,计算圆周率pi。
思路:构造一个1/4单位圆和一个单位正方形,向单位圆和正方形撒点,每一个点可能落在圆内,也可能落在圆外,落在圆内的点和落在正方形内的点的比应该为面积之比,即为pi/4,则可以容易求得pi,随着模拟次数的提升,精确到也会提升。
> #蒙特卡罗方法求pi
> k = 0
> n = 2^22
> start =proc.time()
> for (i in 1:darts){
+ x = runif(1);
+ y = runif(1)
+ if(sqrt(x^2+y^2)>1) next
+ k=k+1
+ }
> pi <- 4*k/n
> proc.time()-start
用户 系统 流逝
42.26 0.05 43.38
> print(paste0('pi is ',pi))
[1] "pi is 3.14185333251953"
最后,对于本文内容,如有疑问可以联系作者(微信:18566011370),欢迎批评指正、提出宝贵意见。
