
引言
最近常看papi酱的周一放送,觉得很喜欢,她每次都可以从不同的角度,用欢乐的、幽默的、讽刺的语言搭配搞笑的、发人深省的动作揭示生活中各种现实问题,将事情的本质及人们在社会生活中的各种状态以简单、容易接受的方式表达出来。乍一看,你可能会觉得她有点怪怪的,但是细细体味,她说的不是很有道理吗?也许很少人能够像她那样敢说真话,敢自由的表达。规矩和体制有时候能够让一个团队朝着一个目标战斗到底,然而也能够让一个个个体失去鲜明的特色,扼杀了多少创新的念头,也浇灭了多样性的火种。为什么要说这个呢,因为有些人学习R,走的是很正规的路子,一本本书,一行行代码去仔细研读,规规矩矩固然是好事,但是有时候我觉得时光有限,知识那么多,更新那么快,很难有那么多精力来慢慢啃,等你学完了一本书,或许这个理论方法已经过时了。所以我主张最好进行案例学习,这种方法对于成年人,特别是工作以后的同学更加合适。学会迁移和模仿,在现代社会非常重要,事必躬亲只能像驴拉磨一样找不到方向,最后累死在小磨盘旁。
下面进入今天的主题,今天主要讲三部分内容,一是数据的各种分布的简单介绍,二是各种数据的处理方式及常见函数,三是蒙特卡罗模拟。
一、常见十六种统计分布
在R语言每一种分布有四个函数:d――(密度函数),p――分布函数,q――分位数函数,r――随机数函数。
(一)正态分布
正态分布(Normal distribution)又名高斯分布(Gaussian distribution),记为:X∼N(μ,σ2),其概率密度函数,期望值μ决定了其位置,标准差σ决定了分布的幅度。因其曲线呈钟形,因此人们又经常称之为钟形曲线,标准正态分布是μ = 0,σ = 1的正态分布。在R语言中有:
密度函数:dnorm(x, mean=0, sd=l, log=FALSE)
分布函数:pnorm(q, mean=0, sd=l, lower.tail=TRUE, log.p=FALSE)
求分位数:qnorm(p, mean=0, sd=l, lower.tail=TRUE, log.p=FALSE)
生成随机数:rnorm(n,mean=0,sd=l)
其中,x,q是数值型变量构成的向量。p是由概率构成的向量,n是产生随机数的个数。mean为均值,缺失时为0,sd为正态分布的标准差,缺失时为1。log,log.p是逻辑变量,当为TRUE时,函数返回值不再是正态分布而是对数分布。lower.tail是逻辑变量,当为true时,分布函数计算公式为F(X)=P{X<=x};当为FAUSE时,F(X)=P{X>x}。这里要注意的是,可以调整参数sd的值(后面的各种分布累死,有形状参数,比例参数),画出各种密度函数对比形状的不同,加深记忆,因为本文涉及的分布太多,只画了单一的密度曲线,读者可以自行在程序中添加。
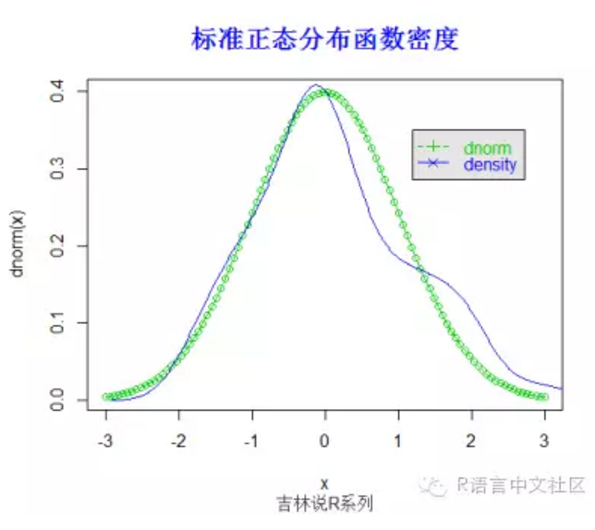
#密度函数模拟
> x=seq(-3,3,length=100)
> plot(x,dnorm(x),type='o',col=3)
> y=rnorm(100)
> lines(density(y), col =4)
> legend(1.2,0.35,
+ c("dnorm", "density"), col = c(3, 4),
+ text.col = c(3,4), lty = c(2, 1), pch = c(3, 4),
+ merge = TRUE, bg = "gray90")
> title("标准正态分布函数密度",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
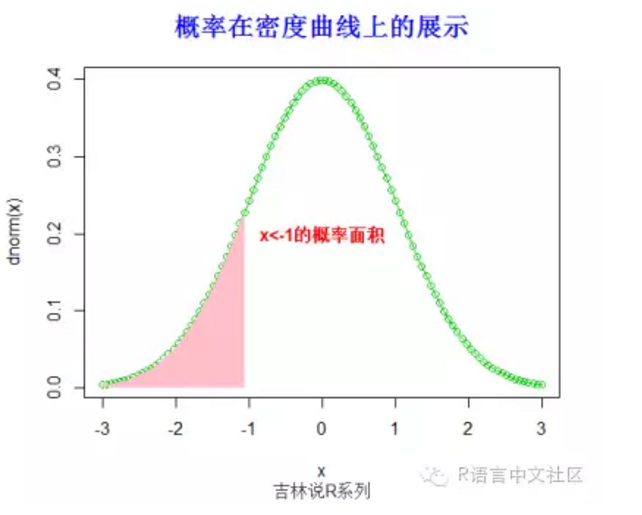
#求概率(x< -1),并绘制相应的阴影。
> pnorm(-1)
[1] 0.1586553
> plot(x,dnorm(x),type='o',col=3)
> fill.y=dnorm(x)
> fill.y=fill.y[x< -1]
> fill.x=x[x< -1]
> fill.x=c(fill.x[1],fill.x,tail(fill.x,1))
> fill.y=c(0,fill.y,0)
> polygon(fill.x, fill.y,col = "pink", density=-1,lty="blank")
> title("概率在密度曲线上的展示",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
> text(0,0.2,"x<-1的概率面积",col="red",font=2)
#求分位数
> qnorm(seq(0,1,length=10))
[1] -Inf -1.2206403 -0.7647097 -0.4307273 -0.1397103 0.1397103 0.4307273 0.7647097 1.2206403 Inf
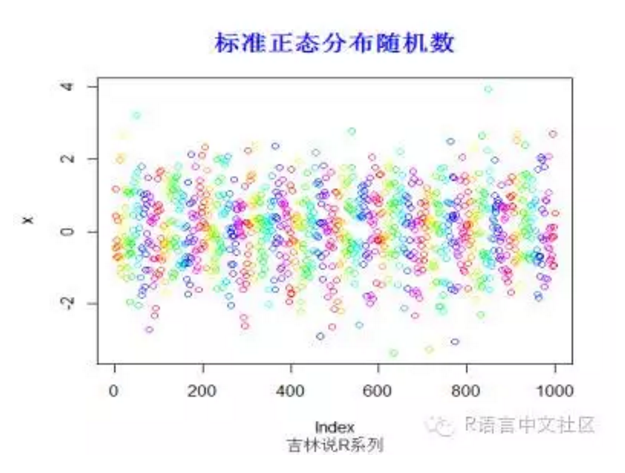
#生成随机数
> x=rnorm(1000, mean = 0, sd = 1)
> plot(x,col=rainbow(100))
> title("标准正态分布随机数",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
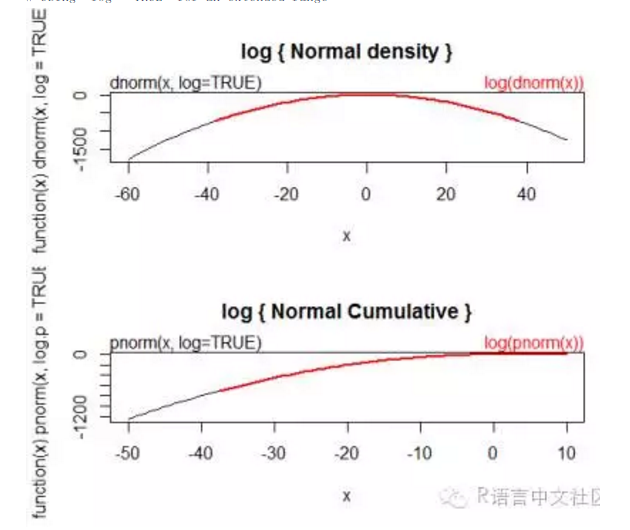
需要注意的是log = TRUE和log(dnorm)区别,如下图所示(后面有些分布也有同样的区别,请自行修改程序,画图比较)。
# Using "log = TRUE" for an extended range
(二)对数正太分布
对数正态分布是对数为正态分布的任意随机变量的概率分布。如果X是服从正态分布的随机变量,则exp(X)服从对数正态分布;同样,如果Y服从对数正态分布,则ln(Y)服从正态分布。 如果一个变量可以看作是许多很小独立因子的乘积,则这个变量可以看作是对数正态分布。一个典型的例子是股票投资的长期收益率,它可以看作是每天收益率的乘积。设x服从对数正态分布,其密度函数为:,数学期望和方差分别为:,。在R语言中有:
密度函数:dlnorm(x, meanlog = 0, sdlog = 1, log = FALSE)
分布函数:plnorm(q, meanlog = 0, sdlog = 1, lower.tail = TRUE, log.p = FALSE)
求分位数:qlnorm(p, meanlog = 0, sdlog = 1, lower.tail = TRUE, log.p = FALSE)
生成随机数:rlnorm(n, meanlog = 0, sdlog = 1)
#密度函数
> set.seed(100)
> x=seq(0,15,length=1000)
> plot(x,dlnorm(x),type='o',col=3)
> y=rlnorm(1000)
> lines(density(y), col =4)
> legend(1.2,0.35,
+ c("dlnorm", "density"), col = c(3, 4),
+ text.col = c(3,4), lty = c(2, 1), pch = c(3, 4),
+ merge = TRUE, bg = "gray90")
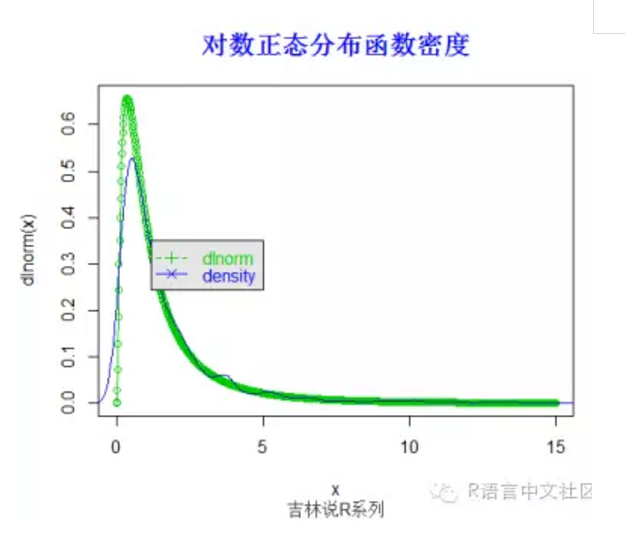
> title("标准正态分布函数密度",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
#求概率(x< -1),并绘制相应的阴影。
> x=seq(0,10,length=4020)
> plot(x,dlnorm(x),type='o',col=3)
> fill.y=dlnorm(x)
> fill.y=fill.y[x< 4]
> fill.x=x[x< 4]
> fill.x=c(fill.x[1],fill.x,tail(fill.x,1))
> fill.y=c(0,fill.y,0)
> polygon(fill.x, fill.y,col = "pink", density=-1,lty="blank")
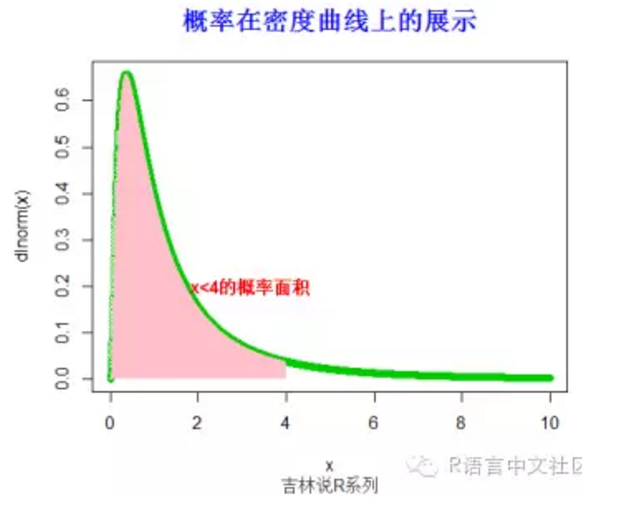
> title("概率在密度曲线上的展示",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
> text(3.2,0.2,"x<4的概率面积",col="red",font=2)
#求分位数
> qlnorm(seq(0,1,length=10))
[1] 0.0000000 0.2950412 0.4654690 0.6500362 0.8696101 1.1499406 1.5383760 2.1483706 3.3893574 Inf
#生成随机数
> x=rlnorm(1000, mean = 0, sd = 1)
> plot(x,col=rainbow(100))
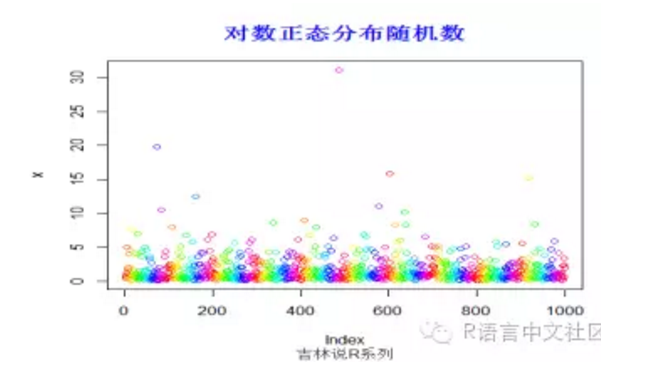
> title("对数正态分布随机数",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
(三)二项分布
二项分布是n个独立的是/非试验中成功的次数的离散概率分布,其中每次试验的成功概率为p。它的数学期望为np,方差为 np(1-p),当n =1时,二项分布就是伯努利分布。在R语言中有:
密度函数:dbinom(x, size, prob, log = FALSE)
分布函数:pbinom(q, size, prob, lower.tail = TRUE, log.p = FALSE)
求分位数:qbinom(p, size, prob, lower.tail = TRUE, log.p = FALSE)
生成随机数:rbinom(n, size, prob)
#密度函数
> set.seed(100)
> n <- 2000
> k <- seq(0, n, by = 50)
> plot(k,dbinom(k,n,0.5),type='o',col=3)
> y=rbinom(k,n,0.5)
> lines(density(y), col =2)
> legend(1100,0.01,
+ c("dbinom", "density"), col = c(3, 2),
+ text.col = c(3,2), lty = c(2, 1), pch = c(3, 2),
+ merge = TRUE, bg = "gray90")
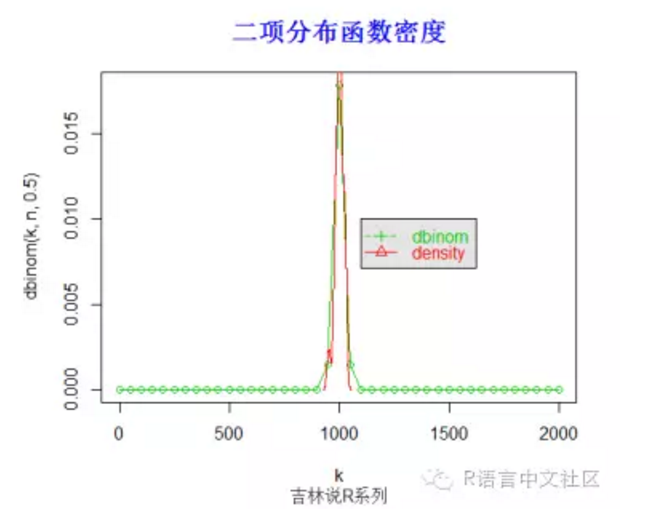
> title("二项分布函数密度",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
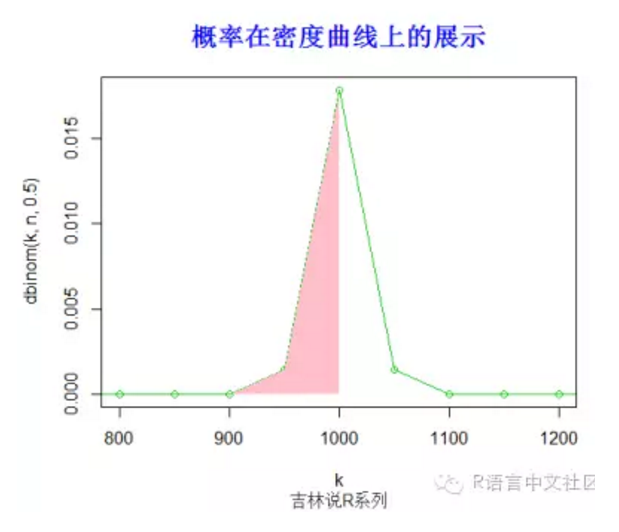
#求概率(x< 1001),并绘制相应的阴影。
> pbinom(1001,n,0.5)
[1] 0.5267407
> plot(k,dbinom(k,n,0.5),type='o',col=3,xlim=c(800,1200))
> fill.y=dbinom(k,n,0.5)
> fill.y=fill.y[k< 1001]
> fill.x=k[k< 1001]
> fill.x=c(fill.x[1],fill.x,tail(fill.x,1))
> fill.y=c(0,fill.y,0)
> polygon(fill.x, fill.y,col = "pink", density=-1,lty="blank")
> title("概率在密度曲线上的展示",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
> text(3.2,0.2,"x<1001的概率面积",col="red",font=2)
#求分位数
> qbinom(seq(0,1,length=10),100,0.5)
[1] 0 44 46 48 49 51 52 54 56 100
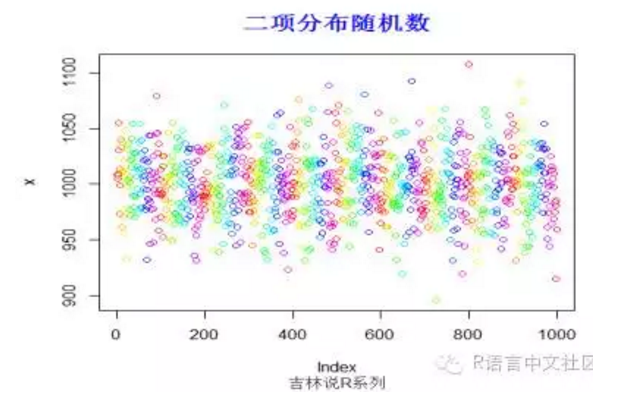
#生成随机数
> set.seed(200)
> x=rbinom(1000,10000,0.1)
> plot(x,col=rainbow(100))
> title("二项分布随机数",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
(四)负二项分布
负二项分布是统计学上一种离散概率分布。满足以下条件的称为负二项分布:实验包含一系列独立的实验, 每个实验都有成功、失败两种结果,成功的概率是恒定的,实验持续到r次成功,r为正整数。其概率密度函数为:,期望为:,方差为:。在R语言中:
密度函数:dnbinom(x, size, prob, mu, log = FALSE)
分布函数:pnbinom(q, size, prob, mu, lower.tail = TRUE, log.p = FALSE)
求分位数:qnbinom(p, size, prob, mu, lower.tail = TRUE, log.p = FALSE)
生成随机数:rnbinom(n, size, prob, mu)
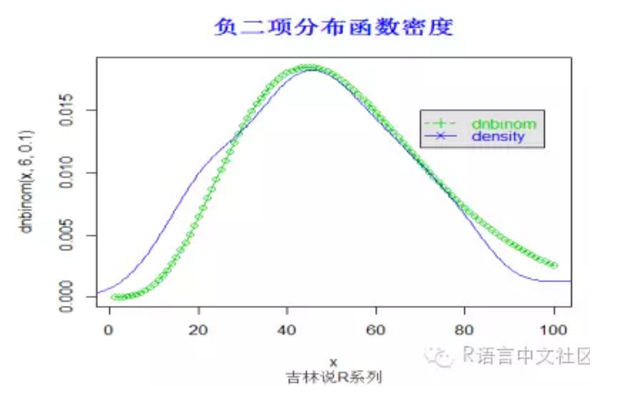
#密度函数
> set.seed(1000)
> x=seq(1,100,by=1)
> plot(x,dnbinom(x,6,0.1),type='o',col=3)
> y=rnbinom(100,6,0.1)
> lines(density(y), col =4)
> legend(70,0.015,
+ c("dnbinom", "density"), col = c(3, 4),
+ text.col = c(3,4), lty = c(2, 1), pch = c(3, 4),
+ merge = TRUE, bg = "gray90")
> title("负二项分布函数密度",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
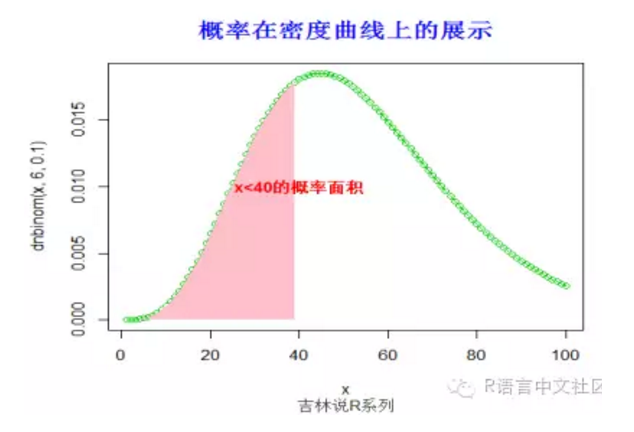
#求概率(x< 40),并绘制相应的阴影。
> pnbinom(4,6,0.1)
[1] 0.0001469026
> x=seq(1,100,by=1)
> plot(x,dnbinom(x,6,0.1),type='o',col=3)
> fill.y=dnbinom(x,6,0.1)
> fill.y=fill.y[x< 40]
> fill.x=x[x< 40]
> fill.x=c(fill.x[1],fill.x,tail(fill.x,1))
> fill.y=c(0,fill.y,0)
> polygon(fill.x, fill.y,col = "pink", density=-1,lty="blank")
> title("概率在密度曲线上的展示",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
> text(40,0.01,"x<40的概率面积",col="red",font=2)
#求分位数
> qnbinom(seq(0,1,length=10),6,0.1)
[1] 0 28 35 42 48 54 61 70 83 Inf
#生成随机数
> set.seed(200)
> x=rnbinom(1000,1,0.1)
> plot(x,col=rainbow(100))
> title("负二项分布随机数",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
(五)伽马分布
伽玛分布是统计学中的一种连续概率函数,包含两个参数α和β,其中α称为形状参数,β称为尺度参数。其密度函数为:,伽玛分布期望是,方差是。在R语言中:
密度函数:dgamma(x, shape, rate = 1, scale = 1/rate, log = FALSE)
分布函数:pgamma(q, shape, rate = 1, scale = 1/rate, lower.tail = TRUE,log.p = FALSE)
求分位数:qgamma(p, shape, rate = 1, scale = 1/rate, lower.tail = TRUE,log.p = FALSE)
生成随机数:rgamma(n, shape, rate = 1, scale = 1/rate)
#密度函数
> set.seed(1000)
> x=seq(1,1000,by=1)
> plot(x,dgamma(x,10,0.1),type='o',col=3)
> y=rgamma(1000,10,0.1)
> lines(density(y), col =2)
> legend(200,0.008,
+ c("dnbinom", "density"), col = c(3, 2),
+ text.col = c(3,2), lty = c(2, 1), pch = c(3, 2),
+ merge = TRUE, bg = "gray90")
> title("伽马分布函数密度",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
#求概率(x< 100),并绘制相应的阴影。
> pnbinom(100,10,0.1)
[1] 0.6710144
> x=seq(1,1000,by=1)
> plot(x,dgamma(x,10,0.1),type='o',col=3)
> fill.y=dgamma(x,10,0.1)
> fill.y=fill.y[x< 100]
> fill.x=x[x< 100]
> fill.x=c(fill.x[1],fill.x,tail(fill.x,1))
> fill.y=c(0,fill.y,0)
> polygon(fill.x, fill.y,col = "pink", density=-1,lty="blank")
> title("概率在密度曲线上的展示",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
> text(200,0.01,"x<100的概率面积",col="red",font=2)
#生成随机数
> set.seed(200)
> x=rgamma(1000,1,1)
> plot(x,col=rainbow(100))
> title("伽马分布随机数",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
#求分位数
> qgamma(seq(0,1,length=10),1,0.1)
[1] 0.000000 1.177830 2.513144 4.054651 5.877867 8.109302 10.986123 15.040774 21.972246 Inf
(六)贝塔分布
贝塔分布的概率密度分布函数数学形式为:,其中
,其期望为:,方差为:。在R语言中有:
密度函数:dbeta(x, shape1, shape2, ncp = 0, log = FALSE)
分布函数:pbeta(q, shape1, shape2, ncp = 0, lower.tail = TRUE, log.p = FALSE)
求分位数:qbeta(p, shape1, shape2, ncp = 0, lower.tail = TRUE, log.p = FALSE)
生成随机数:rbeta(n, shape1, shape2, ncp = 0)
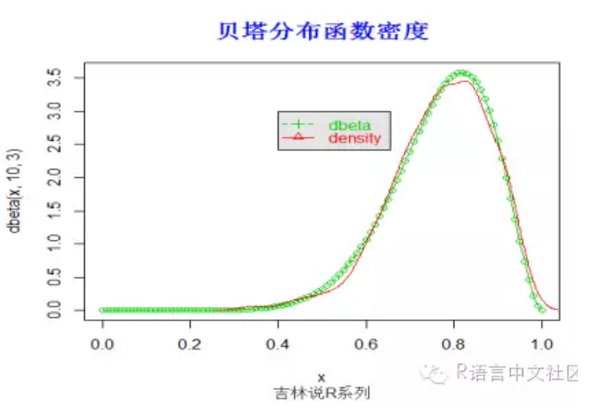
#密度函数
> set.seed(1000)
> x=seq(0,1,by=0.01)
> plot(x,dbeta(x,10,3),type='o',col=3)
> y=rbeta(1000,10,3)
> lines(density(y), col =2)
> legend(0.4,3.0,
+ c("dbeta", "density"), col = c(3, 2),
+ text.col = c(3,2), lty = c(2, 1), pch = c(3, 2),
+ merge = TRUE, bg = "gray90")
> title("贝塔分布函数密度",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
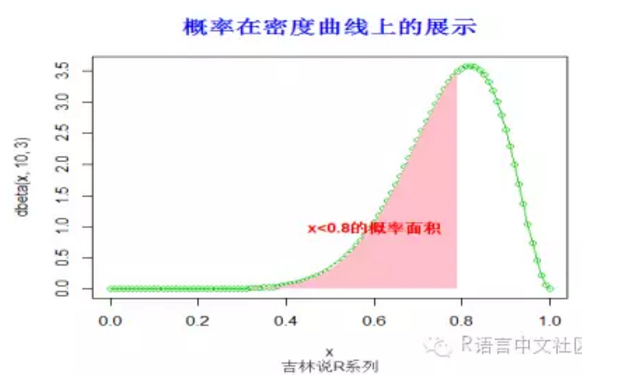
#求概率(x< 0.8),并绘制相应的阴影。
> pbeta(0.8,10,3)
[1] 0.5583457
> x=seq(0,1,by=0.01)
> plot(x,dbeta(x,10,3),type='o',col=3)
> fill.y=dbeta(x,10,3)
> fill.y=fill.y[x< 0.8]
> fill.x=x[x< 0.8]
> fill.x=c(fill.x[1],fill.x,tail(fill.x,1))
> fill.y=c(0,fill.y,0)
> polygon(fill.x, fill.y,col = "pink", density=-1,lty="blank")
> title("概率在密度曲线上的展示",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
> text(0.6,1.0,"x<0.8的概率面积",col="red",font=2)
#求分位数
> qbeta(seq(0,1,length=10),10,3)
[1] 0.0000000 0.6231832 0.6866883 0.7307076 0.7668223 0.7992122 0.8303102 0.8624422 0.8999057 1.0000000
#生成随机数
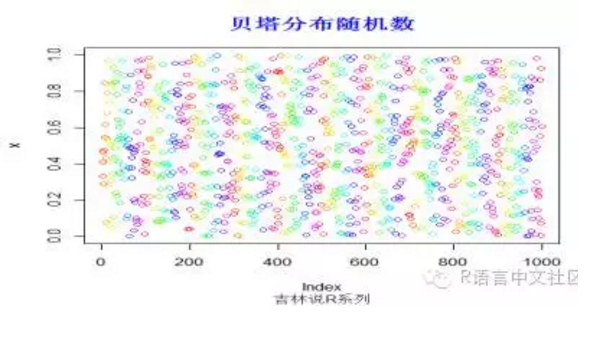
> set.seed(200)
> x=rbeta(1000,1,1)
> plot(x,col=rainbow(100))
> title("贝塔分布随机数",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
(七)几何分布
几何分布(Geometric distribution)是离散型概率分布。在n次伯努利试验中,试验k次才得到第一次成功的机率。概率密度函数为,期望为,方差为。在R语言中有:
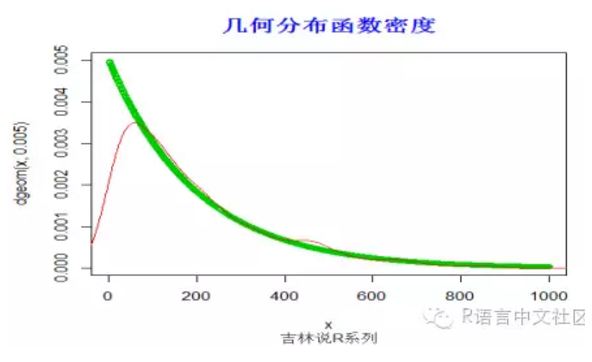
#密度函数
> set.seed(1000)
> x=seq(1,1000,by=1)
> plot(x,dgeom(x,0.005),type='o',col=3)
> y=rgeom(1000,0.005)
> lines(density(y), col =2)
> legend(0.4,3.0,
+ c("dgeom", "density"), col = c(3, 2),
+ text.col = c(3,2), lty = c(2, 1), pch = c(3, 2),
+ merge = TRUE, bg = "gray90")
> title("几何分布函数密度",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
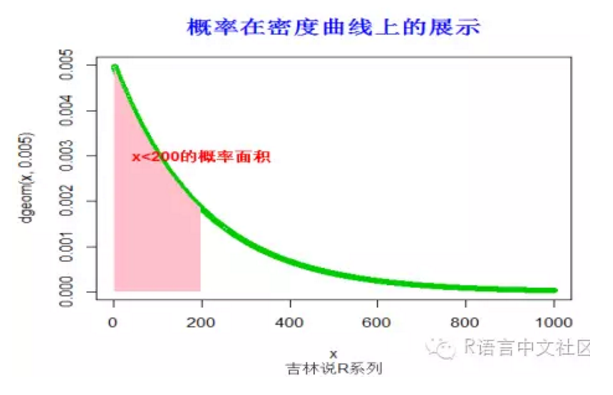
#求概率(x< 200),并绘制相应的阴影。
> pgeom(200,0.005)
[1] 0.634877
> x=seq(1,1000,by=1)
> plot(x,dgeom(x,0.005),type='o',col=3)
> fill.y=dgeom(x,0.005)
> fill.y=fill.y[x< 200]
> fill.x=x[x< 200]
> fill.x=c(fill.x[1],fill.x,tail(fill.x,1))
> fill.y=c(0,fill.y,0)
> polygon(fill.x, fill.y,col = "pink", density=-1,lty="blank")
> title("概率在密度曲线上的展示",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
> text(200,0.003,"x<200的概率面积",col="red",font=2)
#求分位数
> qgeom(seq(0,1,length=10),0.05)
[1] 0 2 4 7 11 15 21 29 42 Inf
#生成随机数
> set.seed(200)
> x=rgeom(1000,0.1)
> plot(x,col=rainbow(100))
> title("几何分布布随机数",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")

(八)超几何分布
假定在N件产品中有M件不合格品,抽出n个物件,成功抽出指定种类的物件的次数(不归还)。称为超几何分布,是因为其形式与“超几何函数”的级数展式的系数有关。其密度函数为:
,其期望为:,方差为:。在R语言中有:
密度函数:dhyper(x, m, n, k, log = FALSE)
分布函数:phyper(q, m, n, k, lower.tail = TRUE, log.p = FALSE)
求分位数:qhyper(p, m, n, k, lower.tail = TRUE, log.p = FALSE)
生成随机数:rhyper(nn, m, n, k)
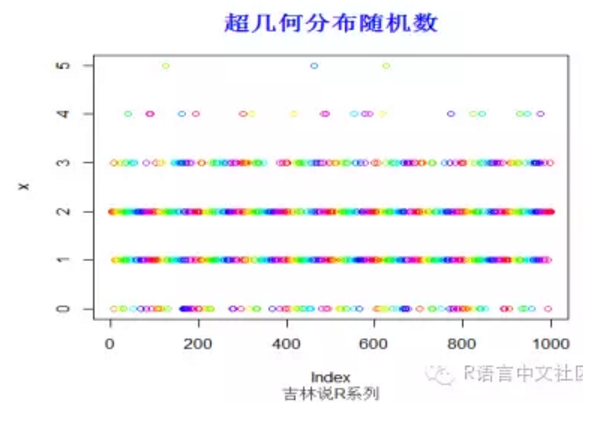
> #生成随机数
> set.seed(200)
> x=rhyper(1000,10,20,5)
> plot(x,col=rainbow(100))
> title("超几何分布随机数",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
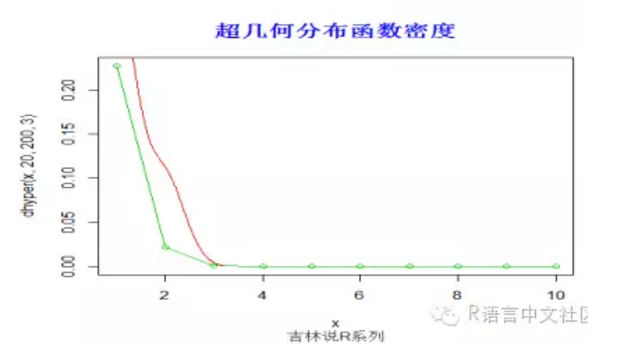
#密度函数
> set.seed(20)
> x=seq(1,10,by=1)
> plot(x,dhyper(x,20,200,3),type='o',col=3)
> y=rhyper(10,20,200,3)
> lines(density(y), col =2)
> legend(0.4,3.0,
+ c("dhyper", "density"), col = c(3, 2),
+ text.col = c(3,2), lty = c(2, 1), pch = c(3, 2),
+ merge = TRUE, bg = "gray90")
> title("超几何分布函数密度",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
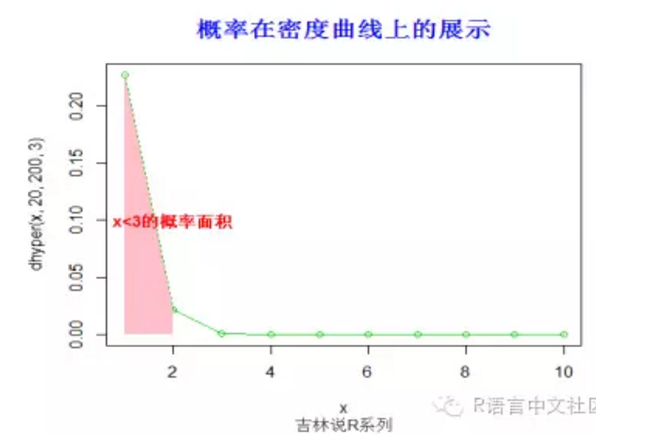
#求概率(x< 3),并绘制相应的阴影。
> phyper(2,20,200,3)
[1] 0.9993488
> x=seq(1,10,by=1)
> plot(x,dhyper(x,20,200,3),type='o',col=3)
> fill.y=dhyper(x,20,200,3)
> fill.y=fill.y[x< 3]
> fill.x=x[x< 3]
> fill.x=c(fill.x[1],fill.x,tail(fill.x,1))
> fill.y=c(0,fill.y,0)
> polygon(fill.x, fill.y,col = "pink", density=-1,lty="blank")
> title("概率在密度曲线上的展示",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
> text(2,0.1,"x<3的概率面积",col="red",font=2)
(九)柯西分布
柯西分布是一个数学期望不存在的连续型分布函数,它同样具有自己的分布密度,满足:
分布函数:F(X)=1/2+1/π*arctanx,-∞<x<+∞,
概率密度函数:f(x)=1/[π(1+x^2)],-∞<x<+∞。在R语言中有:
密度函数:dcauchy(x, location = 0, scale = 1, log = FALSE)
分布函数:pcauchy(q, location = 0, scale = 1, lower.tail = TRUE, log.p = FALSE)
求分位数:qcauchy(p, location = 0, scale = 1, lower.tail = TRUE, log.p = FALSE)
生成随机数:rcauchy(n, location = 0, scale = 1)
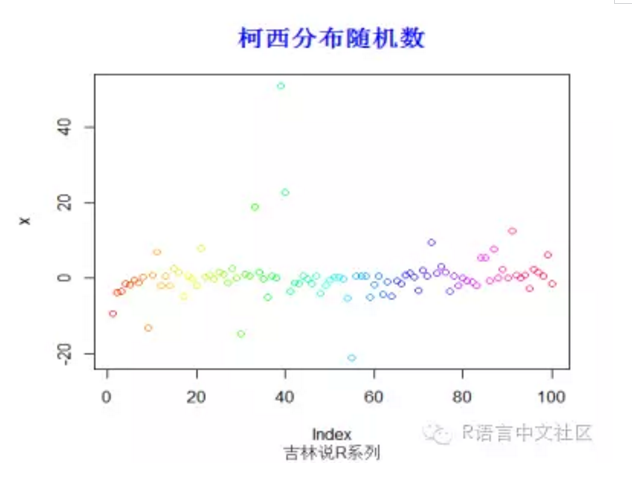
#生成随机数
> set.seed(200)
> x=rcauchy(100)
> plot(x,col=rainbow(100))
> title("柯西分布随机数",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
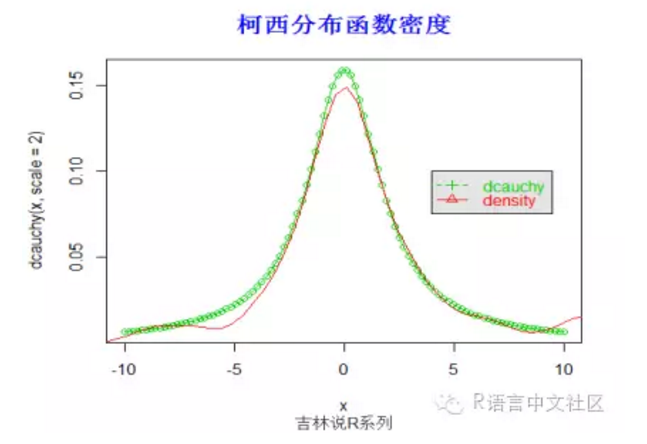
> #密度函数
> set.seed(20)
> x=seq(-10,10,length=100)
> plot(x,dcauchy(x,scale = 2),type='o',col=3)
> y=rcauchy(100, scale = 2)
> lines(density(y), col =2)
> legend(4,0.1,
+ c("dcauchy", "density"), col = c(3, 2),
+ text.col = c(3,2), lty = c(2, 1), pch = c(3, 2),
+ merge = TRUE, bg = "gray90")
> title("柯西分布函数密度",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
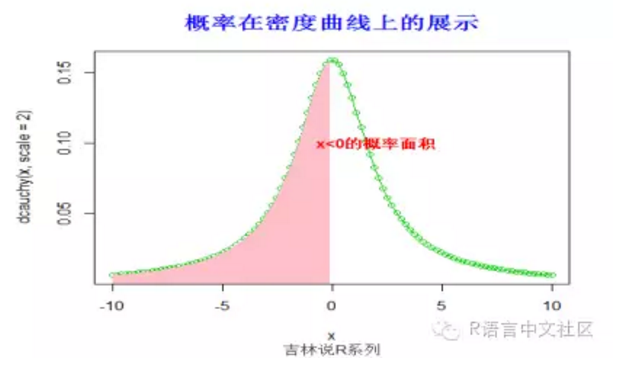
> #求概率(x< 0),并绘制相应的阴影。
> pcauchy(0,scale = 2)
[1] 0.5
> x=seq(-10,10,length=100)
> plot(x,dcauchy(x,scale = 2),type='o',col=3)
> fill.y=dcauchy(x,scale = 2)
> fill.y=fill.y[x< 0]
> fill.x=x[x< 0]
> fill.x=c(fill.x[1],fill.x,tail(fill.x,1))
> fill.y=c(0,fill.y,0)
> polygon(fill.x, fill.y,col = "pink", density=-1,lty="blank")
> title("概率在密度曲线上的展示",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
> text(2,0.1,"x<0的概率面积",col="red",font=2)
#求分位数
> qcauchy(seq(0,1,length=10),scale = 2)
[1] -Inf -5.494955 -2.383507 -1.154701 -0.352654 0.352654 1.154701 2.383507 5.494955 Inf
(十)卡方分布
若n个相互独立的随机变量ξ₁、ξ₂、……、ξn ,均服从标准正态分布(也称独立同分布于标准正态分布),则这n个服从标准正态分布的随机变量的平方和构成一新的随机变量,其分布规律称为卡方分布(chi-square distribution)。其密度函数为:f_n(x) = 1 / (2^(n/2) Γ(n/2)) x^(n/2-1) e^(-x/2),期望为:E(X) = n,方差为:Var(X) = 2n。在R语言中有:
dchisq(x, df, ncp = 0, log = FALSE)
pchisq(q, df, ncp = 0, lower.tail = TRUE, log.p = FALSE)
qchisq(p, df, ncp = 0, lower.tail = TRUE, log.p = FALSE)
rchisq(n, df, ncp = 0)
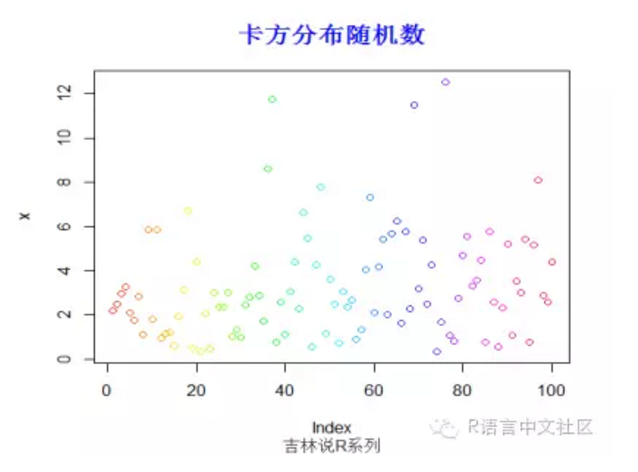
#生成随机数
> set.seed(200)
> x=rchisq(100,3)
> plot(x,col=rainbow(100))
> title("卡方分布随机数",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
#密度函数
set.seed(20)
x=seq(0,20,length=100)
plot(x,dchisq(x,3),type='o',col=3)
y=rchisq(100, 3)
lines(density(y), col =2)
legend(4,0.15,
c("dchisq", "density"), col = c(3, 2),
text.col = c(3,2), lty = c(2, 1), pch = c(3, 2),
merge = TRUE, bg = "gray90")
title("卡方分布函数密度",font.main=2, col.main='blue',
cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
> #求概率(x< 5),并绘制相应的阴影。
> pcauchy(0,scale = 2)
[1] 0.5
> x=seq(0,20,length=100)
> plot(x,dchisq(x,3),type='o',col=3)
> fill.y=dchisq(x,3)
> fill.y=fill.y[x< 5]
> fill.x=x[x< 5]
> fill.x=c(fill.x[1],fill.x,tail(fill.x,1))
> fill.y=c(0,fill.y,0)
> polygon(fill.x, fill.y,col = "pink", density=-1,lty="blank")
> title("概率在密度曲线上的展示",font.main=2, col.main='blue',
+ cex.main=1.5,sub="吉林说R系列",col.sub = "gray20")
> text(5,0.1,"x<5的概率面积",col="red",font=2)
#求分位数
> qchisq(seq(0,1,length=10),3)
[1] 0.0000000 0.6327797 1.0970852 1.5680022 2.0820359 2.6752807 3.4047062 4.3909906 6.0102808 Inf
未完待续,请继续阅读下篇文章~~


