
作者:horo R语言中文社区专栏作者
知乎ID:
https://www.zhihu.com/people/lin-jia-chuan
前言
最近在Kaggle看到一个数据集,非常有趣,所以有个想法想介绍给大家,但由于比较忙,所以一直鸽到现在(就算是比较忙也偷偷看了EVA,EVA最高)
好了,废话不多说。直接开始吧。
决策树最早源于人工智能的机器学习技术,因其具有的出色的数据分析能力和直观易懂的结果展示等特点,被纳入数据挖掘之中,在处理分类问题中,它可以用于识别是否属于垃圾邮件,也可以用来识别目标客户,预测预测顾客未来的消费,当然还有神奇宝贝(污)
一、建立分类回归树的方法
分类回归树的建立,是基于逻辑的,即采用IF···THEN···的形式,通过输入变量取值的比较,来预测输出变量的取值,如下图,事先做好的。
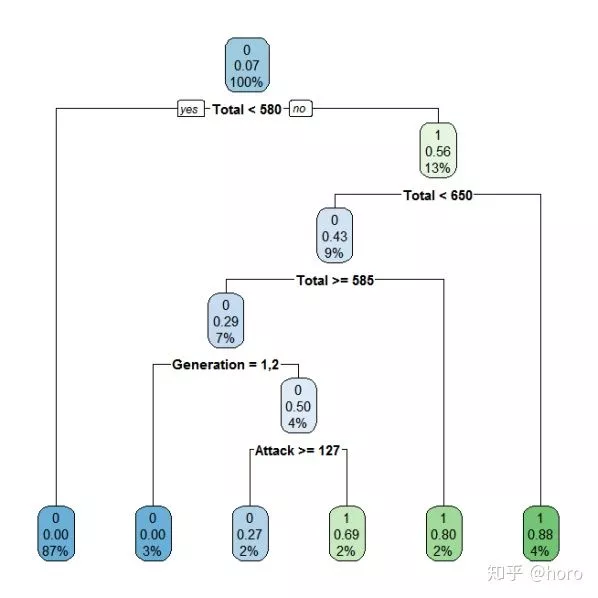
出现6个叶节点
比如说我们想预测某一只神奇宝贝是不是传说级的,按照按决策树的思路可以为,判定其Total(总体强度)是否小于650,如果不是,就可能成为传说级别的神奇宝贝,如果是,便继续往下,判断其Generation(为第几代神奇宝贝),判断其攻击力,如此往下推,直到分类完毕。
二、建立分类回归树的核心问题
2.1
决策树的生长
由于分类回归树的思路可以知道,决策树的生长过程是对样本的不断分组过程,知道各个样本都被分配完毕则结束。这里面有个两个问题是,如何才能从众多的输入变量中选出一个或几个出众的分组变量,第二,如何从众多变量它们各自的取值之中,找到一个最佳的分割点,来判定分组。
2.2
决策树的修剪
决策树充分生长后会形成一颗茂盛的大树,这样就面临过拟合的问题,过拟合是一种在训练样本表现良好但在测试样本表现不是很好的现象。举个例子来说,假如我们知道一只神奇宝贝的面板值,类型,攻击力,防御力,偏好,出现在第几代之中,根据这些,我们可以轻易的知道它是皮卡丘(假定),但也就这条规则仅适用于皮卡丘,但不能用来预测其他神奇宝贝,这就使回归树的使用失去了普遍性,所以我们要找到一种方法,解决过拟合的问题。
三、分类回归树问题的解决
3.1
决策树的生长问题的解决
最佳分组变量和最佳分割点的选择应该是使输出变量异质性下降最快的变量和分割点,对于分类树的生长而言,测度指标常见有Gini系数,和信息增益。研究表明,分类树种Gini系数与信息熵在测试异质性上并没有显著差异,而且最佳分组变量和最佳分割点应该是使输出变量的Gini系数变化最大的变量和分割点。以Gini系数为例
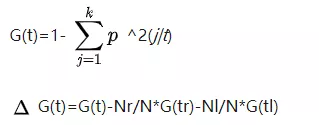
其中,t为节点数,k为输出变量的类别数,p ^2(j|t)为节点t输出变量为j的概率的平方。G(tl)和G(tr)为分组后左右子树的Gini系数,Nl,Nr为左右子树的样本量。所以我们要找到的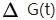 最大的值。
最大的值。
3.2
决策树修剪问题的解决
分类回归树采用预修剪和后修剪相结合的方式剪枝,预修剪即事先指定参数,比如决策树的深度,比如树节点的个数,当达到一定程度就停止剪枝。后修剪是采用一种最小代价复杂度剪枝法的策略。通过这个策略可以达到决策树的目标恰当。
定义代价复杂度:
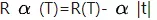
R(T)表示T(可简单理解为树的各个规则)在测试样本集上的预测误差。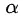 为复杂度参数(又名为CP),当其为0时,表示不考虑复杂度对于代价复杂度的影响。关键在与复杂度参数。
为复杂度参数(又名为CP),当其为0时,表示不考虑复杂度对于代价复杂度的影响。关键在与复杂度参数。
好吧,不知道诸位看懂了多少,不过不用当心,这些都有数学公式有现成的包可以帮助我们直接运算,至于我们需要考率的,CP(复杂度参数的值),最大树深度,指定节点的最小样本量等等,可以通过rpart.control函数去慢慢调。
让我们来直接做一个项目来看分类回归树是怎么做的吧。这样更可能更容易理解一些。
四、数据测试
4.1
数据选取
本文选取Kaggle中的Pokemo数据集,Pokemo数据集是一个有趣的数据集,并且可以用来做分类算法,这个数据集的变量包括:
1. ID,每只神奇宝贝的ID
2. Name,每只神奇宝贝的名字
3. Type1:每只神奇宝贝的类型,比如说水系,比如说火系
4. Type2:由于有特殊的神奇宝贝拥有复数以上的属性。
5. Total:指每只神奇宝贝的强度,一般越高越强
6. HP:指每只神奇宝贝的生命值
7. Attack:指每只神奇宝贝的攻击力
8. Defense:指每只神奇宝贝的防御力
9. SP Attack:指每只神奇宝贝面对相克属性神奇宝贝时的攻击力,通常会比普通攻击力高
10. SP Defense:指每只神奇宝贝面对相克属性神奇宝贝时的防御力,通常会比普通防御力高。
11. Speed:指每只神奇宝贝的速度
12. Generation:指每一只神奇宝贝属于哪一部神奇宝贝的,目前分为五部。
13. Legendary:指每一只神奇宝贝是不是属于传说级别的神奇宝贝,比如麒麟,超梦,梦幻之类的。
4.2
变量选取
通过观测,以及常识,可以认为神奇宝贝的强度,生命力,攻击力,防御力等指标对影响一只神奇宝贝是否属于传说级别的有重要影响,所以,我选取了Total,HP,Attack,Defense,SP Attack,SP Defense,Speed。同时,可以认为不同神奇宝贝开拍部数,出现传说级的神奇宝贝可能会有不同影响,故引入Legendary。通过这些变量,可以利用分类回归数和随机森林算法,拟合出模型,并对每只神奇宝贝是否属于传说级别进行预测。
4.3
特征工程
为了使拟合出来的模型更有适应性,可以把数据集分为3:1,3份为训练集,1份为数据集。首先我们来看一下原始数据集。
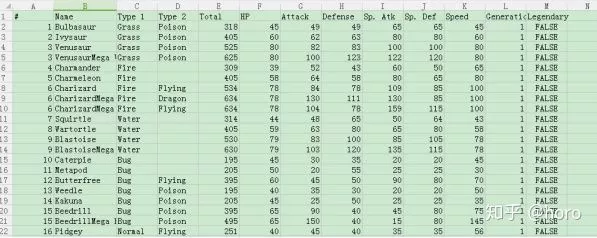
通过观测,我们可以知道,有部分数据集是缺失的,同时Legendary用的是布尔值形式保存,虽然说R语言会默认的把布尔值转换为0,1,但有不规范的风险,所以需要进行转换。
我们输入下列R程序:
1install.packages("rpart")
2install.packages("rpart.plot")
3library(rpart)
4library(rpart.plot)
5pokemon <- read.csv("Pokemon.csv",header = T)#读入数据集
6sampleid <- sample(1:800,size = 200)#进行数据集的切割
7train1 <- pokemon[-sampleid,]
8test1 <- pokemon[sampleid,]
9test1 <- pokemon[sampleid,-1:-4]#剔除掉不用的变量
10train1 <- pokemon[-sampleid,-1:-4]
11train1$Legendary<-ifelse(train1$Legendary=="True",1,0)#将布尔值转为0,1
12train1$Legendary <-as.factor(train1$Legendary)#变因子
13test1$Legendary <- as.factor(test1$Legendary)
然后就可以得到下列数据集
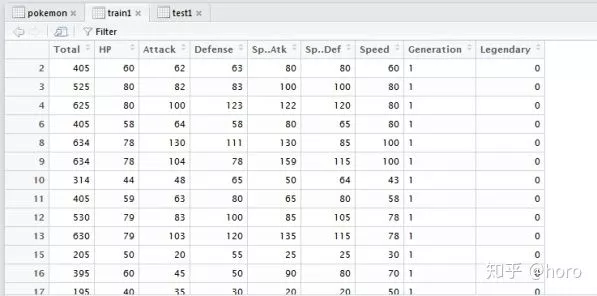
4.4
模型的拟合
(1)分类树算法
rpart包里有专门的函数可以进行分类树,格式如下
1rpart(输出变量~输入变量,data=数据框名,method=方法名,parms=list(split=异质性测度指标),control=参数对象名)
control用于设定预修剪与后修剪等参数,其默认参数保存在rpart.control函数中,基本书写格式为
1rpart.control(minsplit=20,maxcompete=4,xval=10,maxdepth=30,cp=0.01)
我们可以根据需要直接调用修改,比如
1ct <- rpart.control(minsplit=10,maxcompete=5,xval=10,maxdepth=30,cp=0.05)
然后附回去
1rpart(输出变量~输入变量,data=数据框名,method=方法名,parms=list(split=异质性测度指标),control=ct)
当然我们这里直接使用默认参数就可以了,输入下列R程序,可以得到
1treefit <- rpart(Legendary~.,data = train1,method = "class",parms = list(split="gini"))
2printcp(treefit)
得到

决策树的拟合效果比较好,错误率只有0.075,接着看各个变量的重要程度:输入
1treefit$variable.importance
由此可以知道,对于传说级的神奇宝贝而言,他们的总体强度影响力都很大,其次是攻击力与特殊攻击力。
但对于测试集来说,这个模型是否一样好呢,还需进一步检验,输入
1pred <- predict(treefit,test1)#
此时会返回概率值,通常我们认为大于50%,就有把握认为其是传说级神奇宝贝
1pred <- cbind(ifelse(pred[,2]>0.5,1,0))
2confm <- table(test1$Legendary,pred[,1])#建立混淆矩阵,可以得到下列结果

通过计算错误率,我们可以评价模型的好坏,输入
1error <- (sum(confm)-sum(diag(confm)))/sum(confm)
得到0.04的误差率,即有96%的预测准确度,说明模型的效果还是比较不错的。
画个图看下细节
1rpart.plot(treefit)
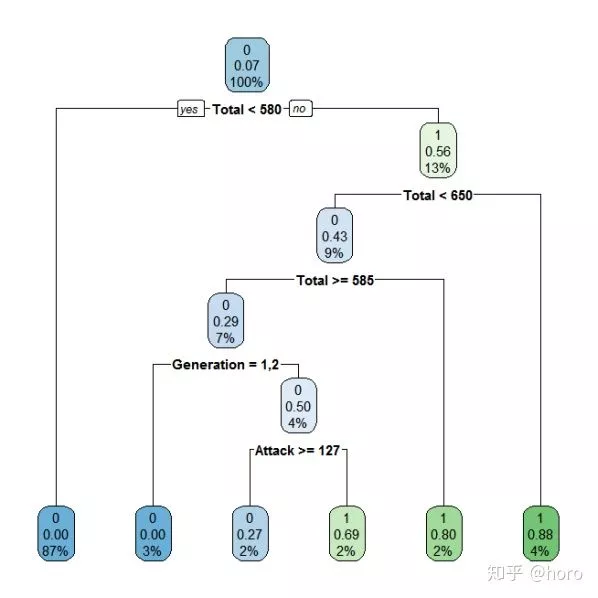
由此可知,最终决策树有6个叶节点,对应6条推理规则:Total小于或等于580时,判断为非传说级,且置信度接近100%,当且Total大于或等于580小于585时,且Generation为1代2代时,判断为非传说级,且置信度接近100%;当且Total大于或等于580小于585时,且Generation为1代2代时,且攻击力小于126.5时,判断为非传说级,且置信度73%。当且Total大于或等于580小于585时,且Generation为1代2代时,且攻击力大于126.5时,判断为传说级,且置信度31%。当且Total大于650时,判断为传说级,置信度为0.12。
总
结
通过比较,我们可以发现分类回归树在拟合模型的效果都比较好,同时我们也可以发现,对于传说级的神奇宝贝来说,强度值与攻击力值的重要程度比较大。具体其他变量还需结合官方设定与实际进行进一步研究

往期精彩:

公众号后台回复关键字即可学习
回复 爬虫 爬虫三大案例实战
回复 Python 1小时破冰入门
回复 数据挖掘 R语言入门及数据挖掘
回复 人工智能 三个月入门人工智能
回复 数据分析师 数据分析师成长之路
回复 机器学习 机器学习的商业应用
回复 数据科学 数据科学实战
回复 常用算法 常用数据挖掘算法
