
作者:herain R语言中文社区专栏作者
知乎ID:https://www.zhihu.com/people/herain-14
前言
从数据需求的角度选择恰当的图表,更好的以图的形式彰显数据的潜在性,规律性,价值性,数据的描述性分析包括用图表展示数据和用统计量描述数据等内容。避免使用图表上的误区,区分扇形图与饼图(很多人都把饼图当作扇形图),不要用时间年份做横轴的条形图(真的很傻),本文将常有的图表根据恰当的用途归位五大类,同时提供R绘图方法。
五大类
展示【类别频数】的图表:简单的条形图, 帕累托图,复式条形图和脊形图,马赛克图,饼图,扇形图,洛伦茨曲线
展示【数据分布】的图表:直方图,茎叶图,箱线图,小提琴图,点图,核密度图
展示【数据关系】的图表:散点图,矩阵散点图,气泡图
展示【数据相似性】的图表:轮廓图,雷达图,星图,脸谱图
时间之上【看趋势】的图表: 时间序列图
1.展示类别频数的图表
# 单变量频度表
> data1<-read.csv('/Users/MLS/desktop/rs/stt/example/ch2/22_1.csv')
> summary(data1)
社区性别 态度
A社区:27 男:36 反对:31
B社区:17 女:44 赞成:49
C社区:21
D社区:15
> count1 <- table(data1$社区)
> prop.table(count1)*100
#二联列表
> count1 <- table(data1$社区, data1$性别)
> addmargins(count1)
#多维列联表
> count1<-ftable(data1)
> count1
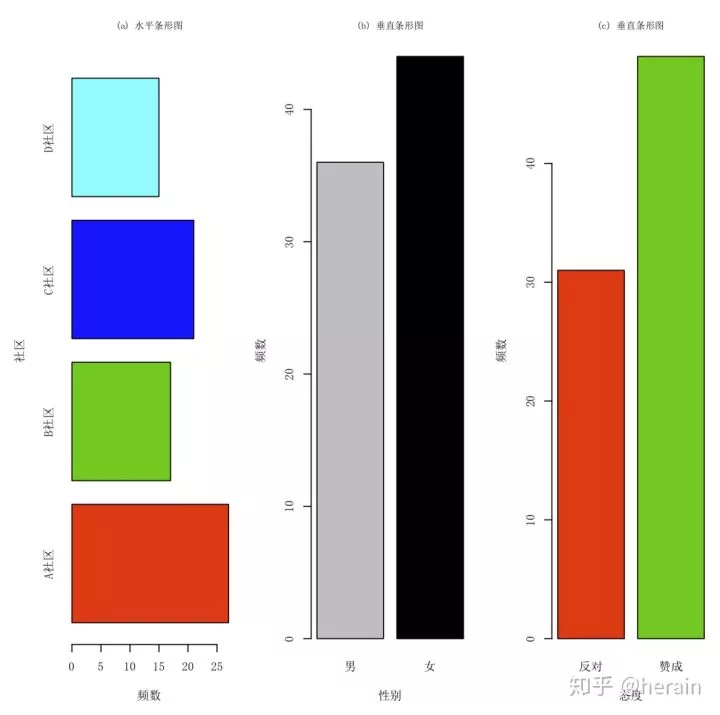
1.1 简单的条形图
> par(mfrow=c(1,3), mai=c(0.7,0.7,0.6,0.1),cex=0.7,cex.main=0.8)
> barplot(count1, xlab="频数", ylab="社区",horiz=TRUE, main = "(a) 水平条形图", col=2:5, family='SimSun')
> barplot(count2, xlab="性别", ylab="频数",col=8:9, main = "(b) 垂直条形图", family='SimSun')
> barplot(count3, xlab="态度", ylab="频数",col=2:3, main = "(c) 垂直条形图", family='SimSun')
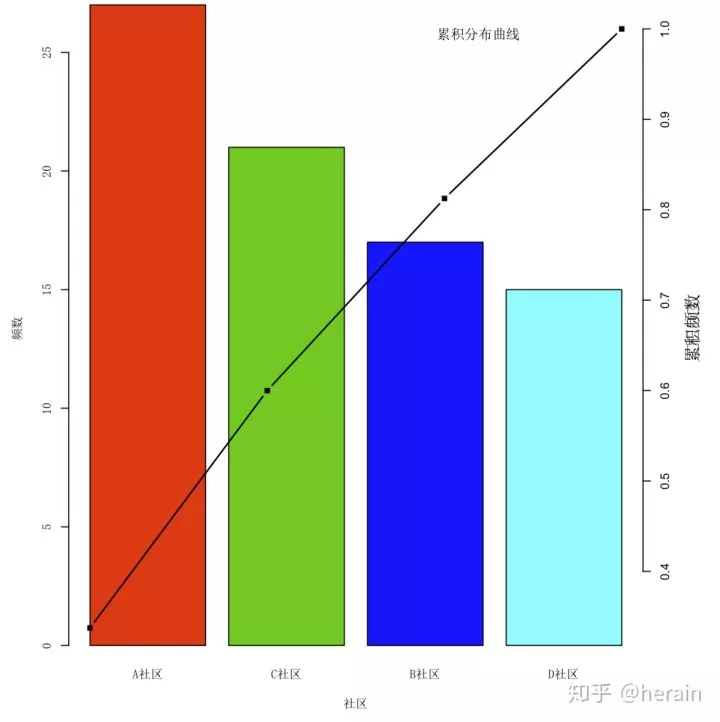
1.2 帕累托图:
> par(mai=c(0.7,0.7,0.1,0.8),cex=0.7,cex.main=0.8)
> barplot(x, xlab="社区", ylab="频数", col=2:5, family="SimSun")
> y<-cumsum(x)/sum(x)
> par(new=T)
> plot(y, type="b", lwd=1.5, pch=15, axes=F, xlab=' ', ylab=' ', main=' ')
> axis(4)
> par(las=0)
> mtext("累积频数", side=4, line=3)
> mtext("累积频数", side=4, line=3, family='SimSun')
> mtext("累积分布曲线", line=-2.5, cex=0.8, adj=0.75,family='SimSun')
1.3:复式条形图和脊形图
par(mfcol=c(1,2), cex=0.6)
barplot(mytable, xlab="社区", ylab="频数", ylim=c(0,16),col=c("red", "blue"),legent=rownames(mytable), args.legend=list(x=12), beside=TRUE, main=“(a)社区条形图”,family=‘SimSun’)
barplot(mytable, xlab="社区", ylab="频数", ylim=c(0,30),col=c("green", "blue"),legend=rownames(mytable), args.legend=list(x=4.8), main=“(b)社区 堆叠条形图”,family='SimSun')

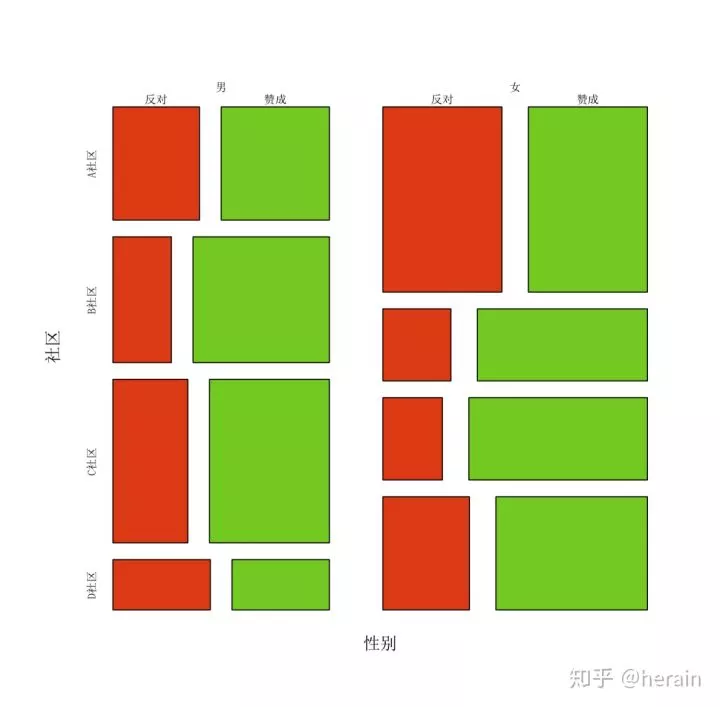
1.4:马赛克图
mosaicplot(~性别+社区+态度, data=data1, color=2:3, main="")
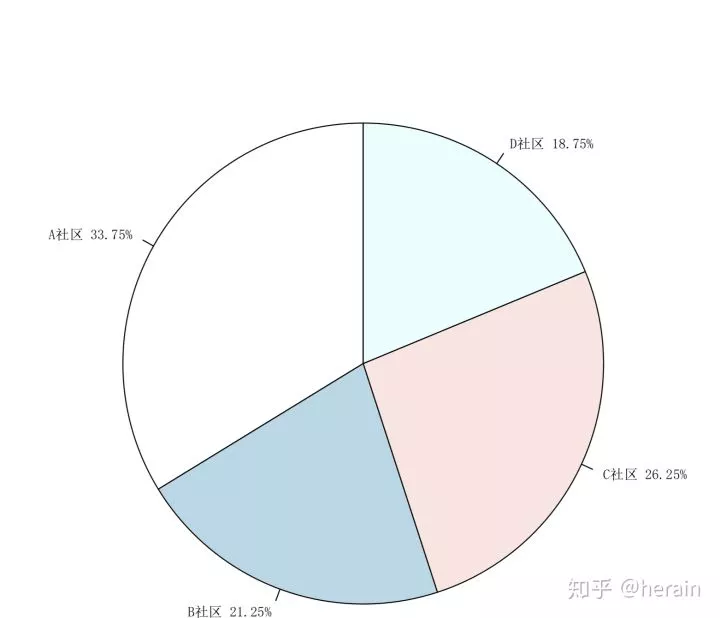
 1.5:饼图
1.5:饼图
data1<-read.csv('/Users/MLS/desktop/rs/stt/example/ch2/22_1.csv')
> count1<-table(data1$社区)
> count1
A社区 B社区 C社区 D社区
27172115
> name<-names(count1)
> name
[1] "A社区" "B社区" "C社区" "D社区"
> precent<-prop.table(count1)*100
> label<-paste(name, " ", precent, "%", sep="")
> par(pin=c(3,3),mai=c(0.1,0.4,0.1,0.4), cex=0.8)
> pie(count1,labels=label,init.angle=90)
> pie(count1,labels=label,init.angle=90,family="SimSun")
pie3D(count1,labels=label,explode=0.1,labelcex=0.7,family="SimSun")
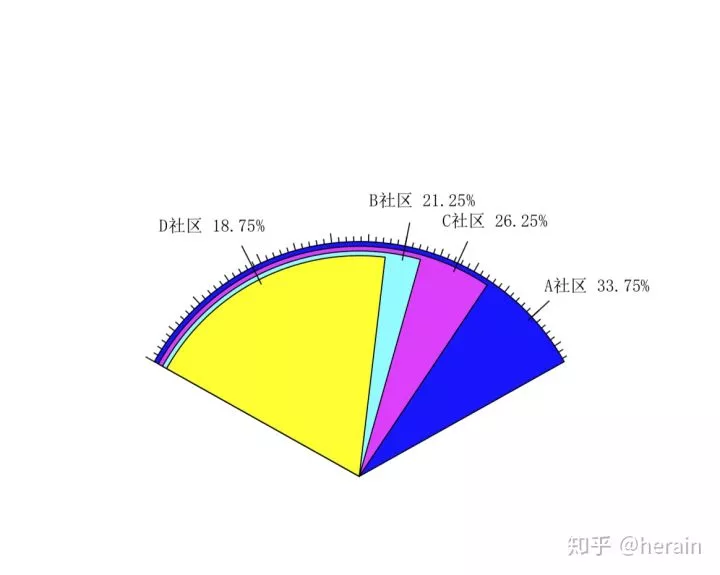
1.6: 扇形图
fan.plot(count1, labels=label, ticks=200, col=c(4:9))
 1.7: 洛伦茨曲线
1.7: 洛伦茨曲线
example2_10<-read.csv('/Users/MLS/desktop/rs/stt/example/ch2/22_10.csv')
library(DescTools)
plot(Lc(example2_10$组中值, example2_10$人数), xlab="人数比例", ylab="收入比例",col=4,panel.first=grid(10,10,col="gray70"))
2.展示数据分布的图表
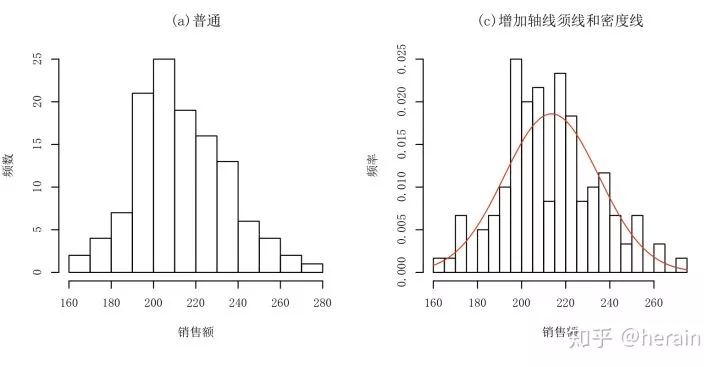
2.1 :直方图
example2_2 <-read.csv('/Users/MLS/desktop/rs/stt/example/ch2/22_2.csv')
> par(mfcol=c(2,2), cex=0.7, family='SimSun')
> hist(example2_2$销售额,xlab="销售额", ylab="频数", main="(a)普通")
> hist(example2_2$销售额,freq=FALSE, breaks=20, xlab="销售额", ylab="频率", main="(c)增加轴线须线和密度线")
> curve(dnorm(x,mean(example2_2$销售额), sd(example2_2$销售额)), add=T, col="red")
>rug(example2_2$销售额)
2.2:茎叶图
> stem(example2_2$销售额)
The decimal point is 1 digit(s) to the right of the |
16 | 17
17 | 1222
18 | 1136788
19 | 11234566667889999
20 | 000012333334455566677778899
21 | 00224556666777788889
22 | 0222344445556689
23 | 0334455678889
24 | 0133368
25 | 2234
26 | 15
27 | 2
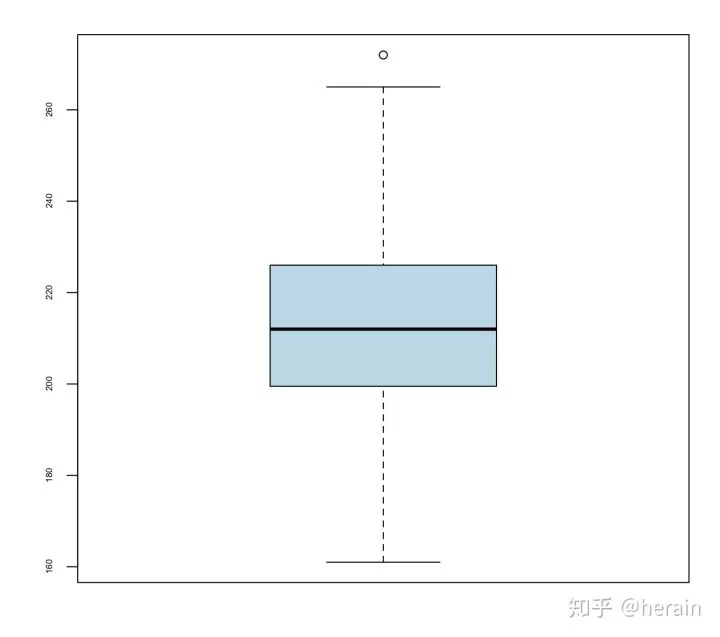
2.3:箱线图
boxplot(example2_2$销售额, col="lightblue", cex.axis=0.5)
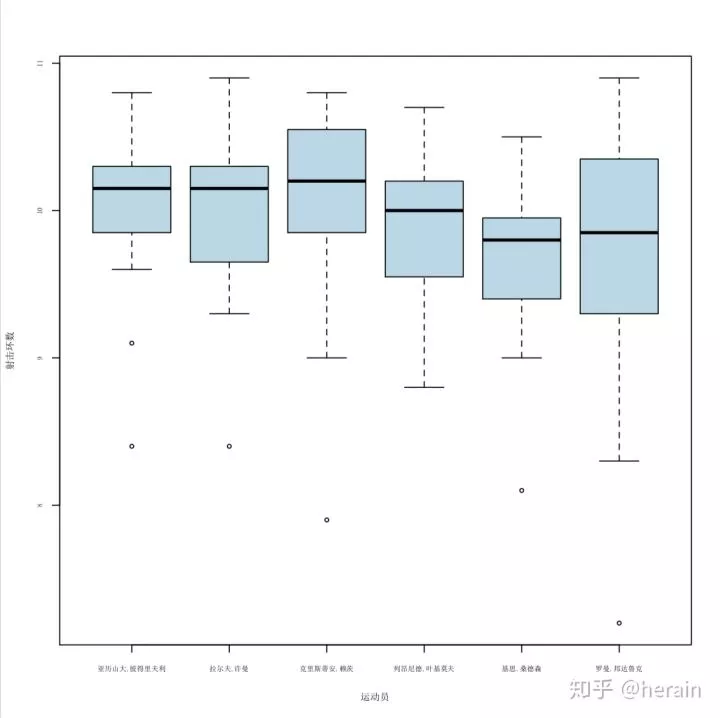
> example2_3 <-read.csv('/Users/MLS/desktop/rs/stt/example/ch2/22_3.csv')
> par(mfcol=c(1,1), cex=0.7, family='SimSun')
> boxplot(example2_3, col="lightblue",xlab="运动员", ylab="射击环数", cex.lab=0.8, cex.axis=0.6, family="SumSin")
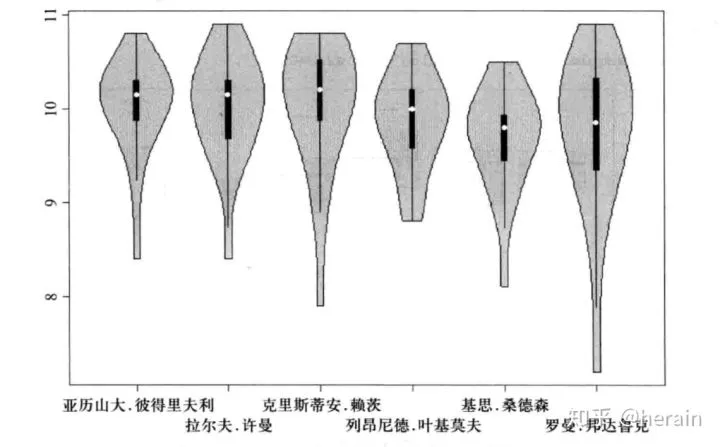
2.4:小提琴
library(vioplot)
par(cex=0.5)
x1<-example2_3$亚历山大.彼得里夫利
x2<-example2_3$拉尔夫.许曼
x3<-example2_3$克里斯蒂安.赖茨
x4<-example2_3$列昂尼德.叶基莫夫
x5<-example2_3$基思.桑德森
x6<-example2_3$罗曼.邦达鲁克
vioplot(x1,x2,x3,x4,x5,x6, col="lightblue", names=c('亚历山大.彼得里夫利','拉尔夫.许曼',
'克里斯蒂安.赖茨','列昂尼德.叶基莫夫','基思.桑德森','罗曼.邦达鲁克'))
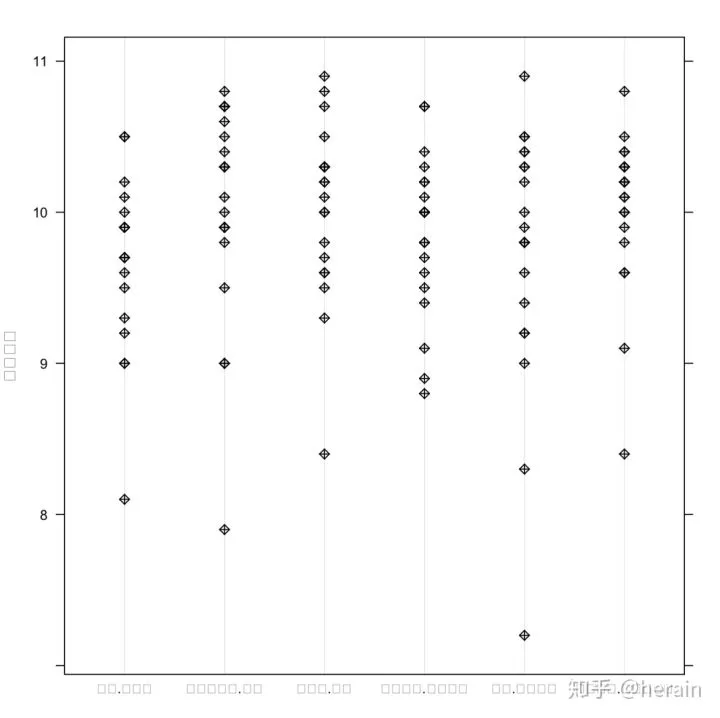
2.5:点图
> example2_3_1 <- read.csv('/Users/MLS/desktop/rs/stt/example/ch2/231.csv'
> par(mfcol=c(1,1), cex=0.7, family='SimSun')
> dotchart(example2_3_1$射击环数, groups=example2_3_1$运动员, xlab="射击环数", pch=20)

> par(mfcol=c(1,1), cex=0.7, family='SimSun')
> dotplot(射击环数~运动员, data=example2_3_1, col="black", pch=9, family='SimSun')
2.6:核密度图
> par(cex=0.7, family='SimSun')
> densityplot(~射击环数|运动员, data=example2_3_1,col="blue",cex=0.5, family='SimSun')

3.展示数据关系的图表
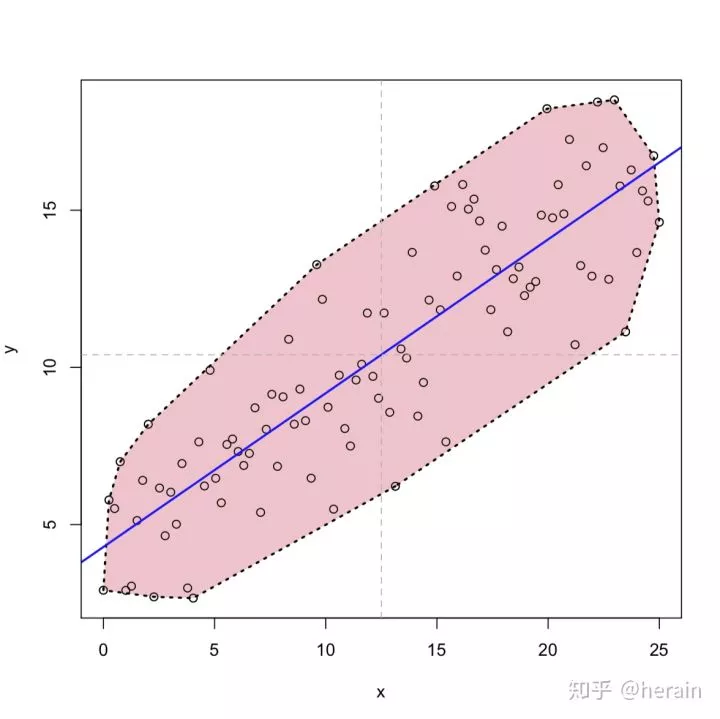
3.1:散点图
> x<-seq(0,25,length=100)
> y<-4+0.5*x+rnorm(100,0,2)
> d<-data.frame(x,y)
> plot(d)
> polygon(d[chull(d),], col='pink', lty=3,lwd=2)
> points(d)
> abline(lm(y~x),lwd=2,col=4)
> abline(v=mean(x),h=mean(y),lty=2,col="gray70")
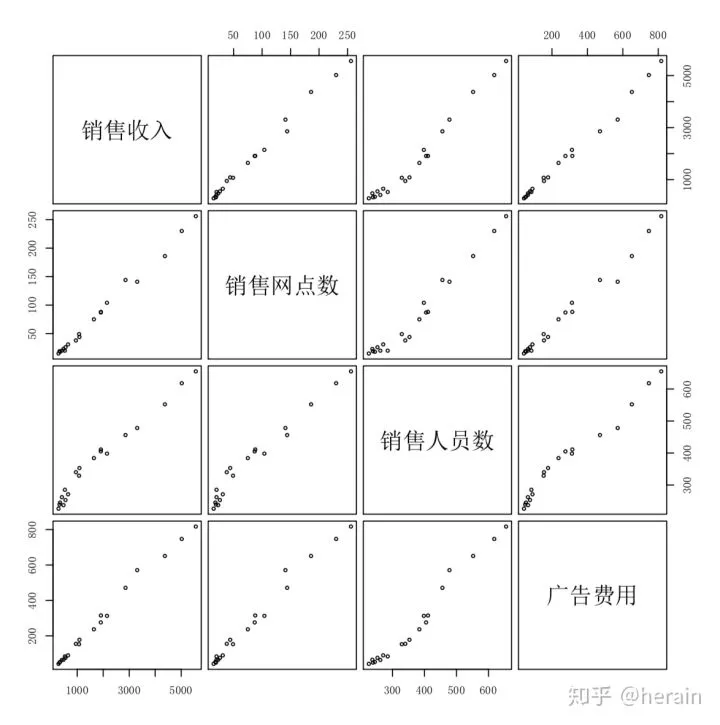
3.2:矩阵散点图
example2_4<-read.csv('/Users/MLS/desktop/rs/stt/example/ch2/22_4.csv')
> par(cex=0.7, family='SimSun')
> plot(example2_4, cex=0.6, gap=0.5, family="SimSun")
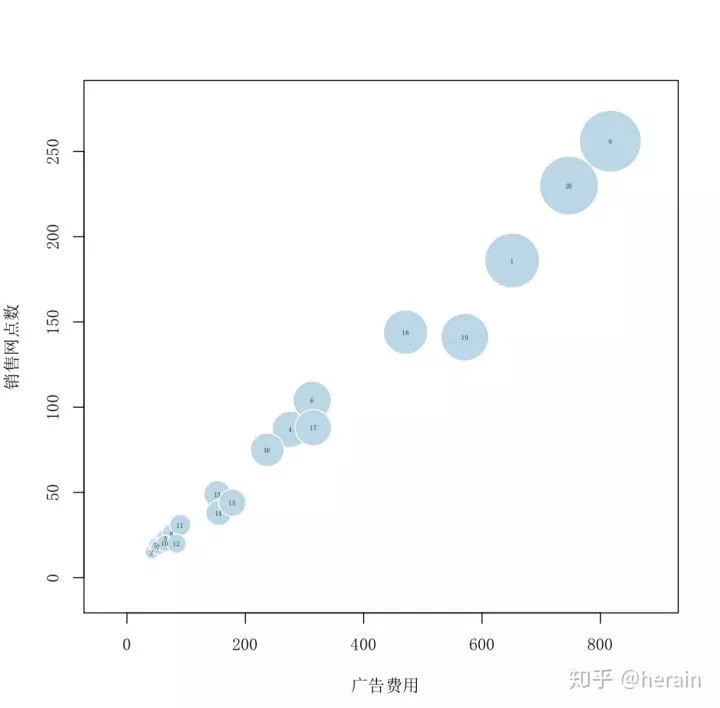
3.3:气泡图
> attach(example2_4)
> r<-sqrt(销售收入/pi)
> symbols(广告费用,销售网点数,circle=r, inches=0.3, fg="white", bg="lightblue",ylab="销售网点数", xlab=" 广告费用")
> text(广告费用,销售网点数, rownames(example2_4),cex=0.4)
4.展示数据相似性的图表
4.1:轮廓图
> example2_5<-read.csv('/Users/MLS/desktop/rs/stt/example/ch2/22_5.csv')
> par(mai=c(0.7,0.7,0.1,0.1),cex=0.8, family="SimSun")
> matplot(t(example2_5[2:9]),type='b',lty=1:7,col=1:7,xlab="消费项目",ylab="支出金额",pch=1,xaxt='n')
> axis(side=1, at=1:8, labels=c("食品","衣着","居住","家电设备用品及服务","医疗保健", "交通和通信", "教育文化娱乐服务","其他商品和服务"),cex.axis=0.6)
"高收入户", "最高收入户"))
> legend(x="topright", legend=c("最低收入户", "低收入户","中等偏下户", "中等收入户", "中等偏上户", "高收入户", "最高收入户"), lty=1:7, col=1:7, text.width=1, cex=0.7)

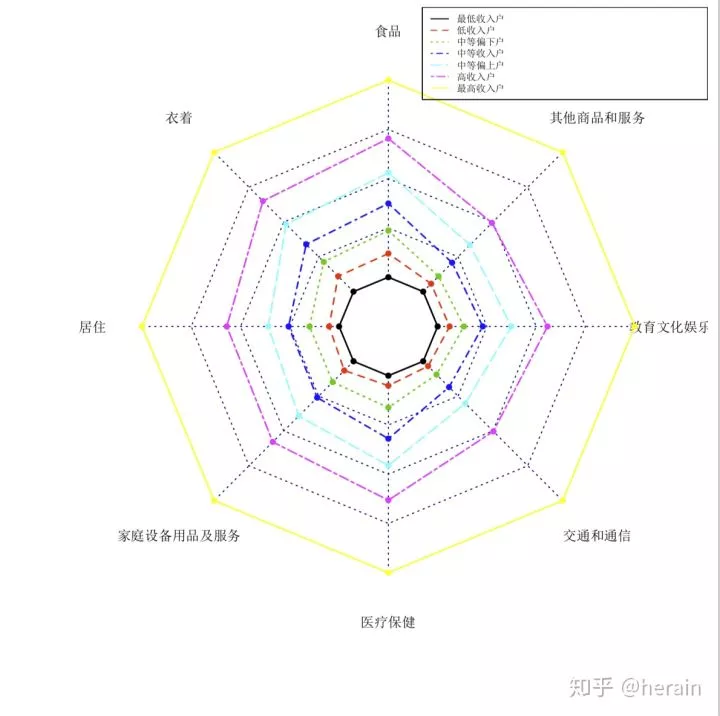
4.2:雷达图
> library(fmsb)
> radarchart(example2_5[,2:9], axistype=0, seg=4, maxmin=F, vlabels=names(example2_5[,2:9]), pcol=1:7, plwd=1.5)
> legend(x="topright", legend=c("最低收入户", "低收入户","中等偏下户", "中等收入户", "中等偏上户", "高收入户", "最高收入户"), lty=1:7, col=1:7, text.width=1, cex=0.7)
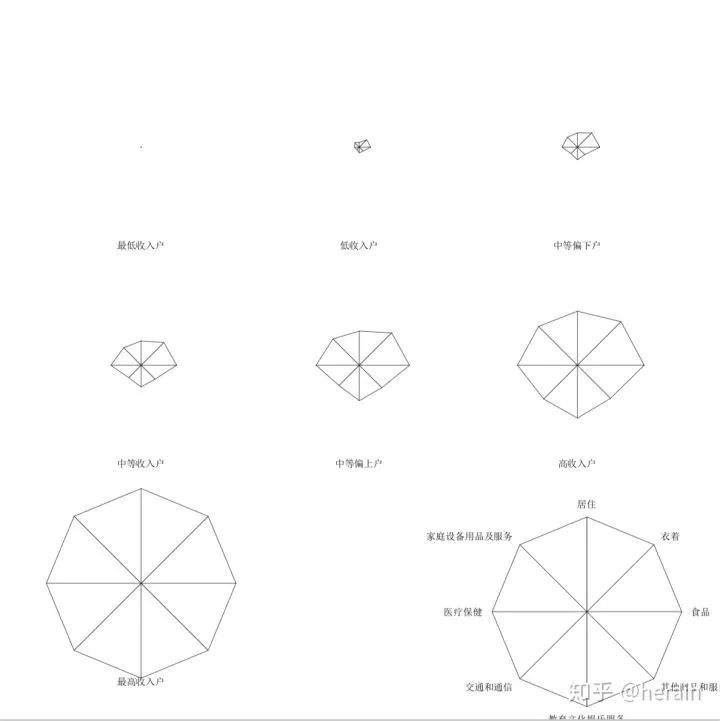
4.3:星图
> mat25 <- as.matrix(example2_5[,2:9])
> rownames(mat25)<-example2_5[,1]
> par(cex=0.7, family='SimSun')
> stars(mat25, key.loc=c(7,2,5),cex=0.8)
5.展示数据随时间变化的图表
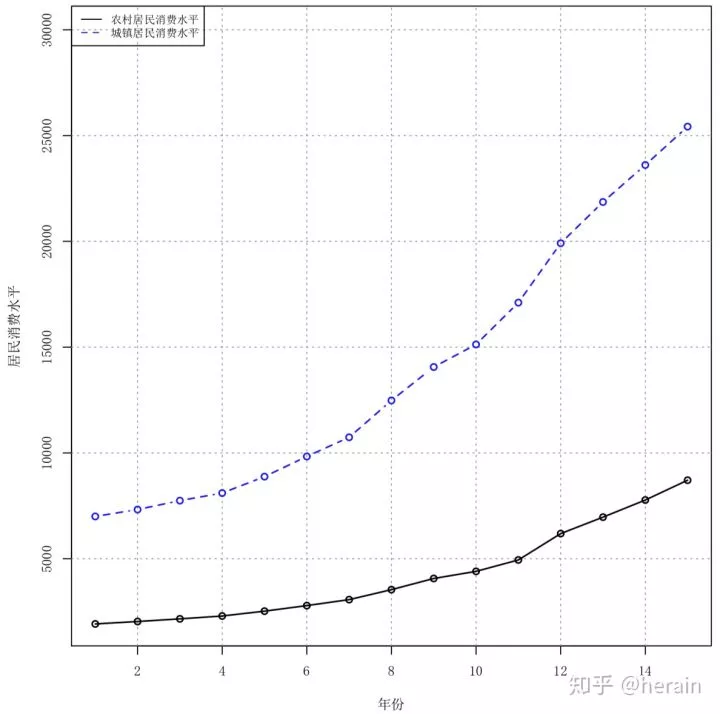
example2_9<-read.csv('/Users/MLS/desktop/rs/stt/example/ch2/22_9.csv')
> par(mai=c(0.7,0.7,0.1,0.1), cex=0.8, family="SimSun")
> plot(example2_9[,2], lwd=1.5, ylim=c(2000,30000), xlab="年份", ylab="居民消费水平",type="n")
> grid(col="gray60")
> points(example2_9[,2], type="o", lwd=1.5, xlab="年份", ylab="居民消费水平")
> lines(example2_9[,3], type="b", lty=2, lwd=1.5, xlab="年份", col="blue")
> legend(x="topleft",legend=c("农村居民消费水平","城镇居民消费水平"), lty=1:2, col=c(1,4), cex=0.8)

往期精彩:

公众号后台回复关键字即可学习
回复 爬虫 爬虫三大案例实战
回复 Python 1小时破冰入门
回复 数据挖掘 R语言入门及数据挖掘
回复 人工智能 三个月入门人工智能
回复 数据分析师 数据分析师成长之路
回复 机器学习 机器学习的商业应用
回复 数据科学 数据科学实战
回复 常用算法 常用数据挖掘算法

