野菜团子,R语言中文社区专栏作者
博客专栏:https://ask.hellobi.com/blog/esperanca
tidyverse是一个汇总包,一包更比6包强,用于数据清洗、转换、可视化等。tidyverse_packages() #列示tidyverse中所有的包其核心包有ggplot、readr、tibble、purrr、 tidyr 、dplyr、ggplot、forcats 和stringr8个,本篇主要讲dplyr这一个。
dplyr包用于数据处理。整体而言,功能和data.table包的重合部分很多,也都有运算很快的优点,data.table包过几天写,根据个人偏好选取吧。速度快,底层运行是C++代码,通过Rcpp运行;而且适用范围广,无论数据存储在data.frame、data.table还是database,都可以处理。作为tidyverse包中一员,其函数可以结合rlang包进行引用或注明结束引用,在编程中提供了很大便利。rlang包以后写。下面简单介绍dplyr包主要操作函数。要了解更多深入的用法,可以参考:browseVignettes(package = "dplyr")
mutate()函数用于生成新的变量,返回一个全新的包含了指定生成的变量的数据,而不是在原有数据上更改。transmute()函数用法相似,但是只返回生成的新变量。mutate(.data, ...)transmute(.data, ...)…表示一系列的变量生成表达式,用“,”隔开,定义为NULL则表示删除变量。mtcars %>% as_tibble() %>% mutate( cyl2 = cyl * 2, cyl4 = cyl2 * 2, mpg = NULL)管道函数%>%表示传递值给下一个函数的第一个参数。也可以用于分组后的变量生成。mtcars %>%group_by(cyl) %>%mutate(rank = min_rank(desc(mpg)))新生成的rank是在按照cyl分组后的排序值。另外还有mutate_all(),mutate_if() 和mutate_at()三个函数可以划定函数和变量范围来生成新变量。iris %>% as_tibble() %>% mutate_if(is.factor, as.character) 第一个参数判定作用变量范围,第二个参数声明应用函数。表示如果是因子变量,就生成对应的字符变量。如果要应用多个函数,则使用funs()来声明。kk4 <- iris %>% mutate_at(vars(matches("Sepal")), funs(l = log, cm = . / 2.54))vars()函数声明作用的对象,上命令表示如果变量名中有"Sepal",就对该变量进行取对和除以2.54的运算,生成的变量名后缀分别为l和cm。“.”指代传入的数据。
arrange()函数用于对变量进行排序。by_cyl <- mtcars %>% group_by(cyl) #按照cyl分组by_cyl %>% arrange(desc(wt)) #无视之前的分组by_cyl %>% arrange(desc(wt), .by_group = TRUE) #在之前的分组内再排序
filter()函数用于筛选行子集。filter(starwars, hair_color == "none", eye_color == "black")filter(starwars, hair_color == "none" & eye_color == "black")filter(starwars, hair_color == "none" | eye_color == "black")前两行筛选出同样的子集,表示要同时满足第2和第3个参数的要求,最后一行表示表示满足其一即可。
select()用于筛选列子集,即变量。select(iris, contains("etal", ignore.case = TRUE))select(iris, matches(".t."))matches()函数可以用正则表达式匹配变量名,而contains()只能匹配字符串,ignore.case选项表示忽略大小写。
slice()函数通过行数来选取子集,前加“-”表示除去该行不选。支持组内操作。slice(mtcars, 1L)slice(mtcars, n())slice(mtcars, 5:n())by_cyl <- group_by(mtcars, cyl)slice(by_cyl, 1:2)以上操作和下列代码完全等效,但是速度上有欠缺:filter(mtcars, row_number() == 1L)filter(mtcars, row_number() == n())filter(mtcars, between(row_number(), 5, n()))filter(by_cyl, between(row_number(), 1, 2))
顾名思义,summarise()函数用于概述数据的统计特征等,结合group_by函数风味更佳。mtcars %>% group_by(cyl) %>% summarise(disp = mean(disp))mtcars %>% group_by(cyl) %>% summarise(sd = sd(disp))
结果就如下图:

之前觉得要一个一个的求均值和方差会很麻烦,想要把它们写在一起,毕竟mutate()函数就可以一次生成多个变量,比如这样:
mtcars %>% group_by(cyl) %>% summarise(disp = mean(disp), sd = sd(disp))
结果就是这样:
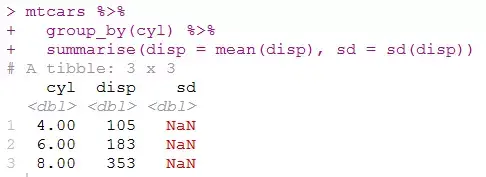
这是因为summarize()函数一旦运行就会重写覆盖变量。
但是想要一次求多个值还是有办法的。
前文提到tidyverse包很适合编程,是因为它适用引用函数quo()函数,即只引用而不计算表达式,它和base包中的quote()用法相似,但是多附带环境信息。这里就用quo()函数来求多值。
var <- list(quo(mean(disp)), quo(sd(disp)))mtcars %>% group_by(cyl) %>% summarise(!!! var)
结果如图:

这样就成功地算出多值了。其中“!!!”是引用终值并解析操作符,使用对象为元素为引用的列表或向量,它将引用的表达式解析并计算,每个列表元素都释放为summarize()函数的参数。另有“!!”操作符针对非列表对象,作用相同。
