作业题目及要求
数据源:PimaIndiansDiabetes2.csv
数据介绍:印第安人糖尿病数据库,包括以下信息:
pregnant Number of times pregnant glucose Plasma glucose concentration (glucose tolerance test) pressure Diastolic blood pressure (mm Hg) triceps Triceps skin fold thickness (mm) insulin 2-Hour serum insulin (mu U/ml) mass Body mass index (weight in kg/(height in m)\^2) pedigree Diabetes pedigree function age Age (years) diabetes Class variable (test for diabetes)
作业需求:我们需要利用"pregnant","glucose", "pressure", "triceps","insulin", "mass",
"pedigree","age"等变量来预测"diabetes"的值。因为数据有缺失值,需要对数据先进行探索,完成缺失值的插补后,再利用分类算法建立预测模型,识别糖尿病患者。
项目要求:
1、 数据探索:利用课上讲到的列表显示缺失值和图形探究缺失数据两种方式对缺失值模式进行探究。
2、 数据完善:要求不能直接删除缺失数据,至少需要利用两种方式对缺失值进行插补。
3、 数据分区:需要按照变量diabetes来进行等比例抽样,其中80%作为训练集train数据,20%作为测试集test数据。
4、 建立模型及评估:利用分类算法对train数据集建立分类预测模型,并对test数据集进行预测,利用混淆矩阵查看模型评估效果。
作业完成情况
1.数据探索
(1)查看各个变量的缺失率占比
dat0<-read.csv('PimaIndiansDiabetes2.csv') #读取数据
na_rat<-function(x)
{
rat<-sum(is.na(x)|is.null(x)|x=='')/length(x)
return(rat)
}
che_na_all<-cbind(apply(dat0,2,na_rat))
结果:

(2)列表显示缺失值:使用mice包中的md.pattern()函数
library(mice)
dat_nancheck<-md.pattern(dat0)
结果:

(3)图形显示缺失
library(VIM)
aggr(dat0,prop=FALSE,numbers=TRUE) #参数改变图形显示的内容
结果如下:

2.数据完善
(1)随机森林填补
library(missForest) #用随机森林迭代弥补缺失值
z <- missForest(dat0)
dat0_1 <- z$ximp #填补后的新数据
md.pattern(dat0_1) # 列表验证
aggr(dat0_1,prop=FALSE,numbers=TRUE) # 图形验证
结果如下:

(2)k紧邻填补
library(DMwR)
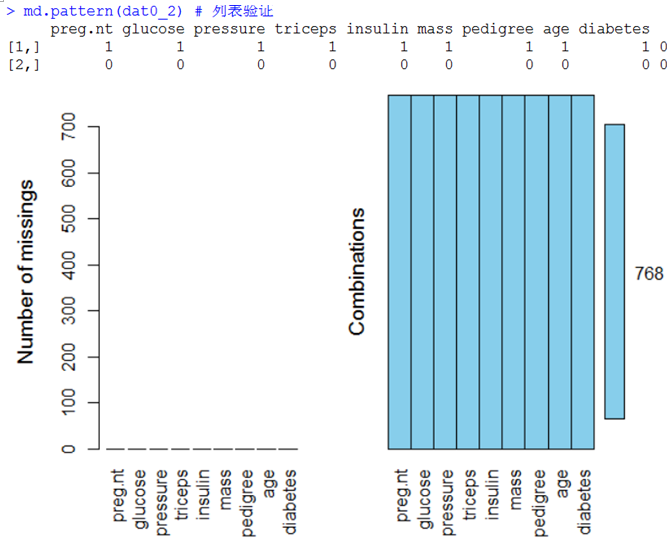
dat0_2<-knnImputation(dat0,k=10,meth ="weighAvg")
md.pattern(dat0_2) # 列表验证
aggr(dat0_2,prop=FALSE,numbers=TRUE) # 图形验证
结果如下:
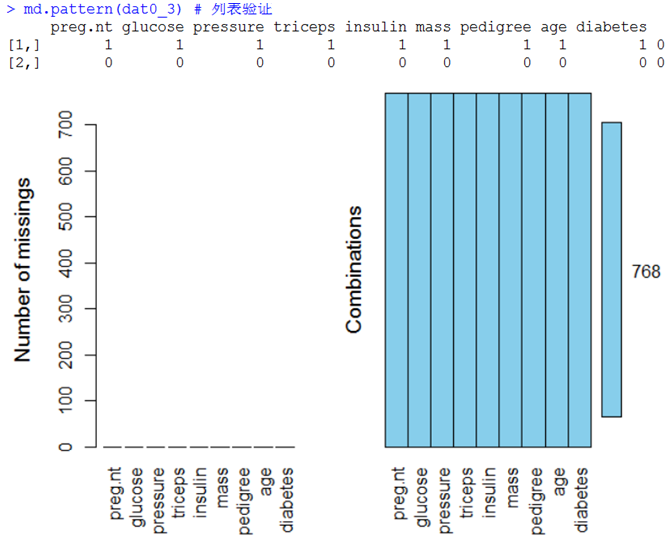
(3)线性回归填补
# 线性回归模型插补
dat0_3<-dat0
library(mice)
#无缺失的列:preg.nt,pedigree,age ,diabetes
dat_complete<-dat0_3[,c()]
#---填补glucose
##c('preg.nt','pedigree','age','diabetes')
datTR=dat0_3[!is.na(dat0_3$glucose),]#glucose非缺失
datTE=dat0_3[is.na(dat0_3$glucose),] #glucose缺失
lm1=lm(glucose~preg.nt+pedigree+age+diabetes,data=datTR)
summary(lm1) #看模型具体情况
#填补
dat0_3[is.na(dat0_3$glucose),"glucose"]<-round(predict(lm1,datTE)) # 利用datTE中
#---填补pressure
datTR=dat0_3[!is.na(dat0_3$pressure),]
datTE=dat0_3[is.na(dat0_3$pressure),]
lm1=lm(pressure~preg.nt+pedigree+age+diabetes+glucose,data=datTR)
summary(lm1) #看模型具体情况
#填补
dat0_3[is.na(dat0_3$pressure),"pressure"]<-round(predict(lm1,datTE))
#---填补triceps
datTR=dat0_3[!is.na(dat0_3$triceps),]
datTE=dat0_3[is.na(dat0_3$triceps),]
lm1=lm(triceps~preg.nt+pedigree+age+diabetes+glucose,data=datTR)
summary(lm1) #看模型具体情况
#填补
dat0_3[is.na(dat0_3$triceps),"triceps"]<-round(predict(lm1,datTE))
#---填补insulin
datTR=dat0_3[!is.na(dat0_3$insulin),]
datTE=dat0_3[is.na(dat0_3$insulin),]
lm1=lm(insulin~preg.nt+pedigree+age+diabetes+glucose,data=datTR)
summary(lm1) #看模型具体情况
#填补
dat0_3[is.na(dat0_3$insulin),"insulin"]<-round(predict(lm1,datTE))
#---填补mass
datTR=dat0_3[!is.na(dat0_3$mass),]
datTE=dat0_3[is.na(dat0_3$mass),]
lm1=lm(mass~preg.nt+pedigree+age+diabetes+glucose,data=datTR)
summary(lm1) #看模型具体情况
#填补
dat0_3[is.na(dat0_3$mass),"mass"]<-round(predict(lm1,datTE))
结果如下:
3.数据分区
#方法1:使用caret::createDataPartition,set.seed()对抽样结果无影响
#采用了上面的 k紧邻填补缺失值的结果
dat<-dat0_2
set.seed(124)
library(caret)
id<-createDataPartition(dat$diabetes,times=1,p=0.8,list=F)
traindat<-dat[id,]
testdat<-dat[-id,]
prop.table(table(dat$diabetes))
prop.table(table(traindat$diabetes))
prop.table(table(testdat$diabetes))
比例结果显示:

#方法2:使用sample函数抽样,set.seed()对抽样的结果有影响
set.seed(124)
id<-sample(c(TRUE,FALSE),size=nrow(dat),replace=T,prob=c(0.8,0.2))
traindat1<-dat[id,]
testdat1<-dat[!id,]
4.建立模型及评估
#-----------利用算法进行预测
#-----10折交叉验证选择参数(caret包)
control<-trainControl(method='repeatedcv',number= 10,repeats = 3)
# 利用rpart函数建立分类树
rpart.model0<-train(diabetes~.,data=traindat,method='rpart',trControl=control)
# 利用randomForest函数建立随机森林
rf.model0<-train(diabetes~.,data=traindat,method='rf',trControl=control)
# 利用nnet函数建立人工神经网络
nnet.model0<-train(diabetes~.,data=traindat,method='nnet',trControl=control)
#查看寻参结果
rpart.model0
rf.model0
nnet.model0
#rpart,rf,nnet训练模型
#决策树
rpart.model<-rpart::rpart(diabetes~.,data=traindat,control= (cp=0.0627907))
#随机森林
rf.model<-randomForest::randomForest(diabetes~.,data=traindat,mtry=2)
#神经网络
nnet.model<-nnet::nnet(diabetes~.,data=traindat,size=5,decay=0.1)
#存测试集预测的结果
result<- data.frame(algorithm=c("决策树","随机森林","人工神经网络"),
TPR=rep(0,3),
TNR=rep(0,3),
FPR=rep(0,3),
FNR=rep(0,3),
ACC=rep(0,3),
ERR=rep(0,3)
)
for(iin 1:3)
{train_pre<-predict(switch(i,rpart.model,rf.model,nnet.model),newdata=traindat,type='class')
test_pre<-predict(switch(i,rpart.model,rf.model,nnet.model),newdata=testdat,type='class')
#混淆矩阵
confusion<-table(actual=testdat$diabetes,predict=test_pre)
#测试集预测的结果
(TP <- confusion[4])
(TN <- confusion[1])
(FP <- confusion[3])
(FN <- confusion[2])
(N <- sum(testdat$diabetes == 'neg'))
(P <- sum(testdat$diabetes == 'pos'))
#TPR
result[i,2]<-TP/P
#TNR
result[i,3]<-TN/N
#FPR
result[i,4]<-FP/N
#FNR
result[i,5]<-FN/P
#ACC
result[i,6]<-(sum(TN) +sum(TP))/sum(confusion)
#ERR
result[i,7]<-(sum(FN) +sum(FP))/sum(confusion)
}
结果如下:


