总结
根据以往工作学习中没有太在意或者说没意识到的地方,做一个关于SSIS数据提取的细节技巧总结。
(这是一篇没有图的文章)
1.禁忌的select *
在数据流中,运行时,OLEDB源,ODBC源等组件向SQL Server 发送一条select * from table的命令,然后返回表的每行每列。
缺点: a.可能仅仅只需要表中列的子集,但是在抽取到目标系统之前,请求的每一列提取都会产生开销,消耗资源。想想如果数据库如果在不同的服务器上,而且还包括不同的层(文件系统,SQLServer数据存储引擎,查询处理器,表格数据流,数据协议,最终到SSIS管道,可能还有别的层),请求的冗余列乘以行数处理的开销也不低了。
b.如果同事或者别人突然向源表中加入一列且包通过select *请求的数据,那么目标和源表结构就不同,包不知道如何处理多余列,运行肯定失败。
故意设计:为了维护和安全,所需要的列应该被显示指定。(当然源适配器提供了列复选框筛选的功能,但是多一事不如少一事。)
2.源适配器中限定行数
where子句是用来提升性能工具之一,只抽取需要行数的数据,不需要的行用where条件过滤掉。别在ssis中再来处理不用的行数。请求的越少,所需要的处理和IO就更少,从而解决方案就会越快。
3.提取时转换
当然不是对每种转化都可行,特别是需要记录数据中错误的时候。但是对于基础的操作还是很意义的,比如:修剪空白,锐化数据类型(值的最小类型),未知处理,提供友好列名等。将简单的数据清洗工作 交给SQLServer数据引擎来完成,它的效率更高,从而提高ETL性能且降低包的复杂性。其实防止不良数据最好的办法是规范应用程序的数据输入。
4.提取时合并
同一个数据库中,能在一个适配器中合并就一个适配器里合并。例如从同一数据库提取sale_A表和sale_B表,在一个源ssis适配器中两张表union all即可。别用两个单独的ssis源适配器分别抽取每张表,然后在ssis中使用UnionAll组件合并。(横向合并 join也是相同的道理)
5.数据库中排序
SQLServer 对存储在表中的数据那是相当熟悉,所以才能高效的执行某些操作。特别当它有索引来帮助完成查询工作。对大型数据集而言,SQLServer比SSIS更适合排序操作。比如,从一张表获取数据,然后合并联接转换的时候使用(合并联接转换组件需要先排序操作输入),虽然在ssis可以使用排序转换对其进行排序,但如果数据源是个关系型数据库,那么就应该尝试在select子句抽取的时候对数据进行直接order by排序。因为SQLServer在大型数据集排序比ssis效率高,极大提升性能。
6.模块化封装
对于经常要用的查询,如果能接触到源系统,尝试封装这些查询。当然现实中可能不会被允许接触源系统。但是如果可以,这种封装将会带来非常大的好处。
封装方式:创建视图,存储过程以及读取数据的函数 。
好处:
a.如果封装到存储过程中,那么非常容易的在用户自定义函数或者视图中封装该存储。非常容易的在SQLServer中查询该存储过程,不用深入ssis包中查看了。
b.如果查询逻辑发生变化,比如查询条件变了,或者查询指向另一张表。那么此时只需要修改一个位置就行了。同时所有函数调用也会得到好处。但是此处有一个风险。如果要删除某列来更改查询的话,那么调用该函数的包将可能会报错。因为丢失了列,ssis会不知所措了。
7.使用基于集的逻辑
SQLServer中提供了相关集逻辑操作的关键字,比如union,except,intersect,具体含义看下图。还可以利用公共表达式CTE。
如果两张表A,B有交集的话 ,如图:
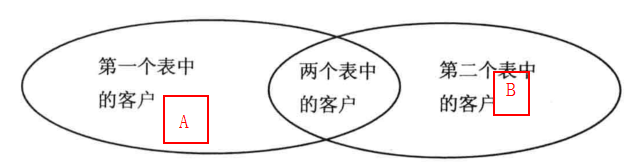
A union B :A,B表的并集(没去重)
A except B :在A中存在且在B中不存在的
A intersect B : A,B表的交集
