介绍
聚类意思就是把一个大数据集按照某种距离计算方式,分成若干个分类。其中每个分类类内的差异性比类与类之间的差异性小很多,差不多和古语“物以类聚,人以群分”有几分相似吧。
常见三种聚类描述
如果您想对聚类方法了解更多,您可以访问https://cran.r-project.org/web/views/Cluster.html这个网页,或许它能够帮助到你,也欢迎您在评论区评论我的文章
聚类步骤
(1) 选择合适的变量。选择能够很好代表个体不同维度上的数据指标,指标之间尽量有较大不同,这样分类的效果较好。这一步非常关键,如果变量变量不好聚类出来的结果肯定不好
(2) 数据归一化处理,可以直接使用scale函数,也可以自定义函数实现
(3) 寻找异常点,像K-means均值算法对异常值敏感,所以聚类之前要检查是否含有异常值。你可以通过outliers包中的函数来筛选(和删除)异常单变量离群点。 mvoutlier包中包含了能识别多元变量的离群点的函数。
(4) 确定聚类方法,例如系统聚类、K-means聚类、K-中心点聚类(PAM)等
(5) 多次进行聚类,查看聚类之后的效果,确定最终聚类类数
(6) 最后图表展示聚类的结果
接下来我们将着重介绍系统聚类和K-means聚类,同时也会对K-中心点聚类和clara聚类的函数参数进行介绍
系统聚类
常见几个步骤
- 选取需要的变量
- 对变量数据进行归一化处理
- 计算距离矩阵
- 利用hclust()函数实现层次聚类,具体聚类方法有以下几种,结合自身需求进行选择

- 利用NBclust函数帮助确定最佳聚类类数(不过这里的最佳聚类类数可能有多个,你要结合业务知识或需求,选择其中符合自身需求的类数)
下面用系统聚类来做个小案例
# 获取数据
data(nutrient, package="flexclust")
row.names(nutrient) <- tolower(row.names(nutrient))
# 数据归一化处理
nutrient.scaled <- scale(nutrient)
# 计算距离矩阵
d <- dist(nutrient.scaled)
fit.average <- hclust(d, method="average") #平均联动聚类方法
plot(fit.average, hang=-1, cex=.8, main="AverageLinkage Clustering")
#确定聚类的个数
library(NbClust)
devAskNewPage(ask=TRUE)
# NbClust函数利用它内部30个评价指标帮助我们判断最佳聚类类数K,投票建
# 议数越多的,则这个类数就是最佳聚类数,具体见帮助
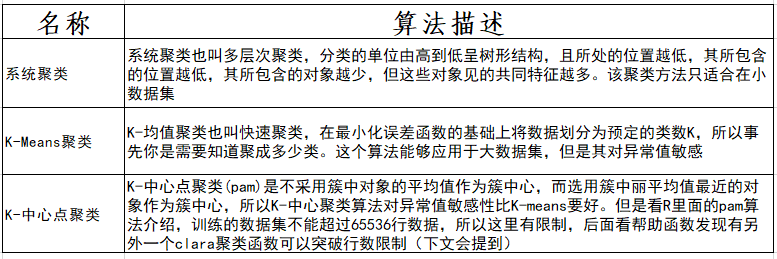
nc <- NbClust(nutrient.scaled,distance="euclidean",min.nc=2, max.nc=15, method="average")
table(nc$Best.n[1,])
 输出结果
输出结果
# 这里我们选择聚成5类
# 输出聚类结果
cluster_data<-cutree(fit.average,k=5)
table(cluster_data)
aggregate(as.data.frame(nutrient.scaled), by=list(cluster=cluster_data), mean)
# 画出聚类图
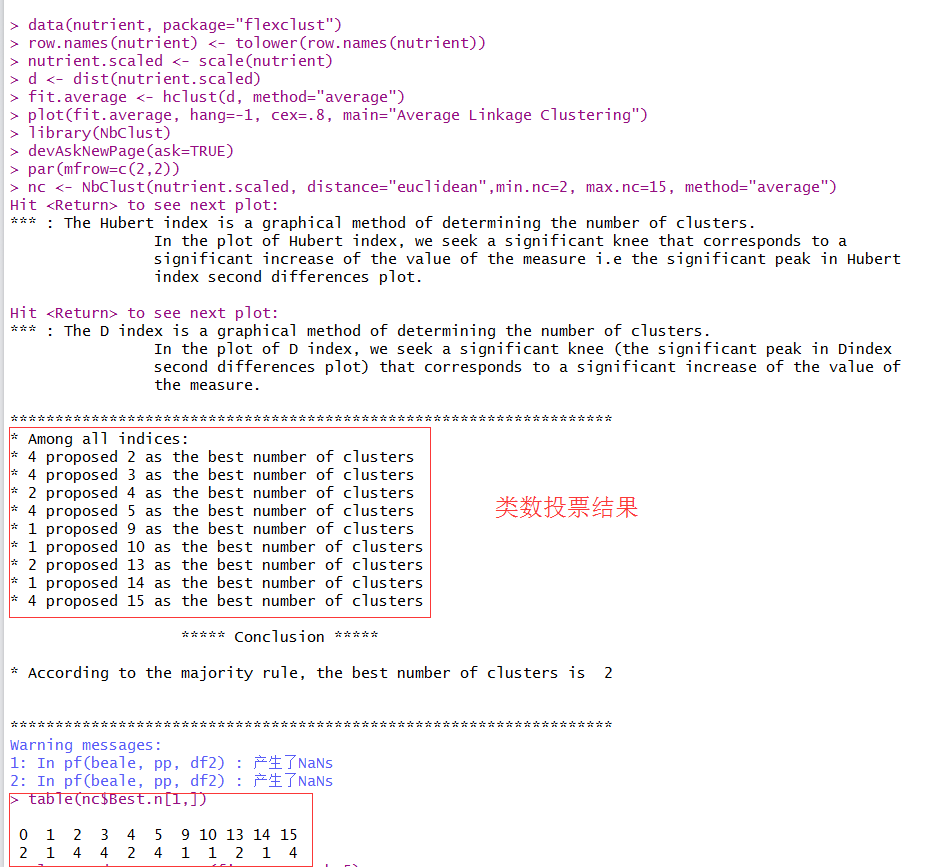
plot(fit.average, hang=-1, cex=.8,main="数据源聚成五类的结果")
# 对树状图进行划分
rect.hclust(fit.average, k=5)
# 把最终的聚类结果和原数据组合成dataframe
result<-cbind(nutrient,cluster = cluster_data)
K-means均值聚类
接下来我们将用一个餐饮客户的消费行为特征数据如下表所示(附件含数据集),根据这些数据将客户进行分类,并评价客户的价值。
数据集包含四个变量,分别是 用户ID,R(最近一次消费的时间间隔)、F(消费频率)、M(消费总金额)
1、数据获取及预处理
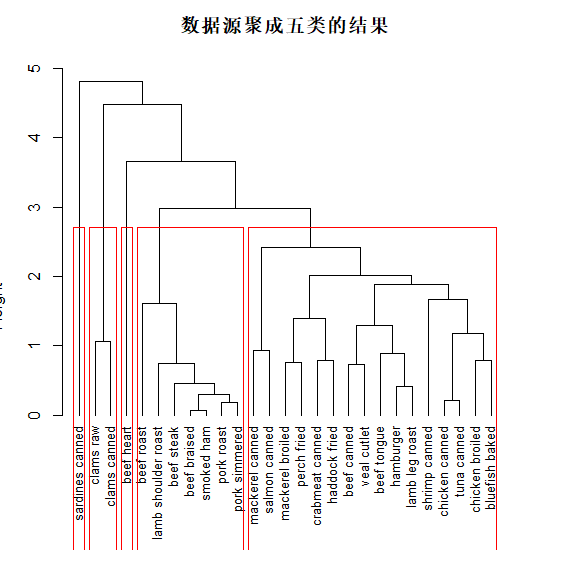
setwd('D:\\study\\R语言数据分析与挖掘实战\\第5章挖掘建模\\chapter5\\示例程序\\data')
# 读入数据
Data<-read.csv("consumption_data.csv",header = T)
# 查看数据
head(Data)
# 数据归一化
data_scale<-scale(Data[,c(2,3,4)])
2、异常值检测
# 异常值检查
##利用单变量异常检测函数boxplot.stats()函数实现
out_data1<-boxplot.stats(Data[,2],coef = 4)
index1<-which(Data[,2] %in% (out_data1$out)) # 变量R中的异常值
out_data2<-boxplot.stats(Data[,3],coef = 4)
index2<-which(Data[,3] %in% (out_data2$out)) # 变量F中的异常值
out_data3<-boxplot.stats(Data[,4],coef = 4)
index3<-which(Data[,4] %in% (out_data3$out)) # 变量M中的异常值
#这里我们定义两个指标都异常的才异常,这里的是空值,但是定义异常的方法不绝对,具体看分析场景
intersect(index1,index3) #intersect求集合之间的交集
运行结果
3、利用kmeans函数实现
# data_scale 标准化之后的数据集,center 类数
kmean_data<-kmeans(data_scale,centers = 3)
# 各类数量
kmean_data$size
# 各类占比
kmean_data$size/sum(kmean_data$size)
#源数据与类组合dataframe
df<-data.frame(Data,cluster = kmean_data$cluster)
# data_scale 标准化之后的数据集,center 类数
kmean_data<-kmeans(data_scale,centers = 3)
# 各类的个数
kmean_data$size
# 各类占比
kmean_data$size/sum(kmean_data$size)
#源数据与类组合dataframe
df<-data.frame(Data,cluster = kmean_data$cluster)
# 查看各类的指标平均值
(t1<-aggregate(df[,c(2,3,4)],by=list(cluster= df$cluster),mean))
运行结果:

##利用图表来观察各类的指标的数据密度分布
attach(df)
par(mfrow=c(1,3))
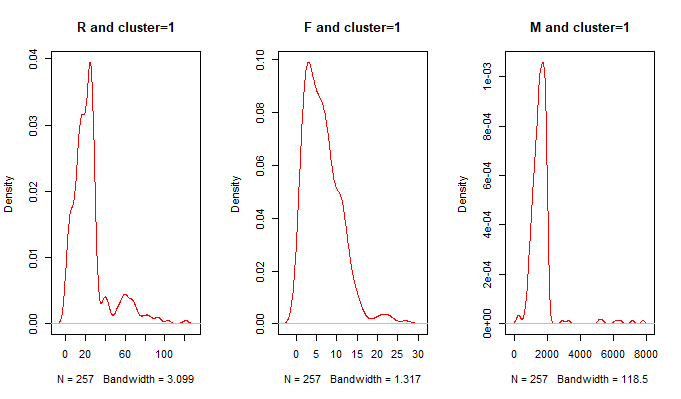
plot(density(df[cluster==1,2]),col='red',main = 'R and cluster=1')
plot(density(df[cluster==1,3]),col='red',main = 'F and cluster=1')
plot(density(df[cluster==1,4]),col='red',main = 'M and cluster=1')
par(mfrow=c(1,3))
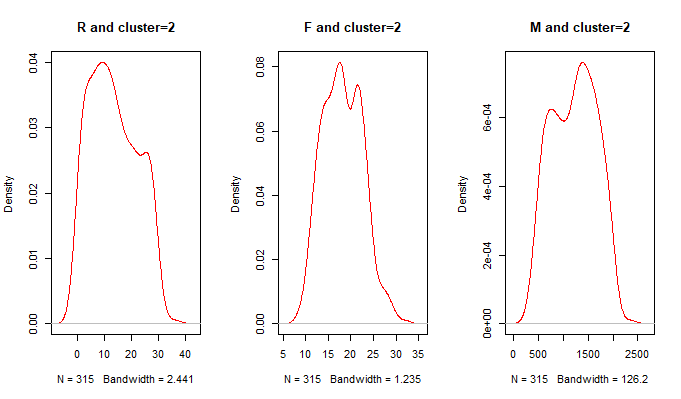
plot(density(df[cluster==2,2]),col='red',main = 'R and cluster=2')
plot(density(df[cluster==2,3]),col='red',main = 'F and cluster=2')
plot(density(df[cluster==2,4]),col='red',main = 'M and cluster=2')
par(mfrow=c(1,3))
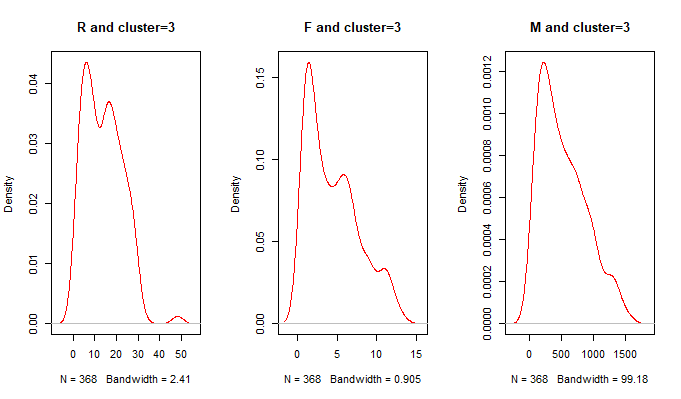
plot(density(df[cluster==3,2]),col='red',main = 'R and cluster=3')
plot(density(df[cluster==3,3]),col='red',main = 'F and cluster=3')
plot(density(df[cluster==3,4]),col='red',main = 'M and cluster=3')
detach(df)
客户价值分析:
第一类:用户R集中在10-30天,F消费次数集中在5-20次之间,M消费金额分布在1600-2000之间
第二类:用户R集中在5-30天,F消费次数集中在10-30次之间,M消费金额分布在500-2000之间
第三类:用户R集中在10-30天,F消费次数集中在1-10次,M消费金额分布在200-1000之间
对比分析:第一类用户消费金额非常大,消费频次和时间间隔中等,属于我们的高端消费人群,这一人群我们要尽量使用(贵宾会员等优质服务)增加他们的消费次数,从而增加营收。第二类用户消费总金额中等,时间间隔短,消费次数多,属于经常光顾的中等消费人群。第三类用户的消费金额和消费次数较低,时间间隔较长,属于价值较低消费人群。
其他两个聚类的参数介绍
K-中心聚类
公式: pam(x, k, stand = FALSE)
X表示数据集,K表示聚类数,Stand表示对变量是否归一化处理
由于pam函数的聚类的数据集有行数限制(太大会报错),所以如果数据集较大的时候,则改用cluster包中的clara函数
K-中心聚类 (应用于大数据集)
公式: clara(x, k, stand = FALSE, samples)
X表示数据集,K表示聚类数,Stand表示是否归一化出来,要注意的是这里的samples---抽取的样本数,建议设置大于100以上


