下午看了社区里的一篇文章《Python 爬虫实践:《战狼2》豆瓣影评分析》,感谢分享。
最近也是在学习爬虫,周末刚好看了词云图,这里就自己也来实现下。
周末的词云图介绍《word_cloud-用Python之作个性化词云图》
1. 豆瓣影评页面分析
我们到豆瓣电影模块,选择《战狼2》,找到下面的短评

页面地址:https://movie.douban.com/subject/26363254/comments?status=P
通过FireBug,观察页面,可以发现,评论信息还是很好拿的
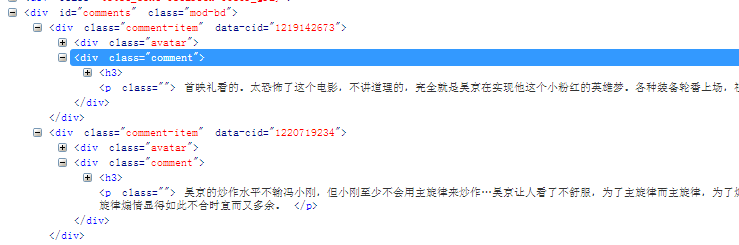
然后,我们看看下一页数据是怎么获取的

这里是直接用参数传的,多点几次观察,就会发现规律

这里有个小疑问,他这个参数start,短评每页20条没有问题,但是这个start,并不是0,20,40开始的,会跳跃,不知道为啥,
而且,这个limit貌似是假的,我改成100都没用,还是显示20条
而且,不登录的话,并不能看完所有的短评,后面会报错,说没有权限。
#解析当前页面
def parseCurrentPage(html):
soup = BeautifulSoup(html, "html.parser")
#获取评论信息
p_comments = soup.select('div#comments div.comment p')
p_lines=[]
for com in p_comments:
p_lines.append(com.contents[0].strip()+'\n')
#获取下一页信息,可以通过这个获取数据
p_next = soup.select_one('div#paginator a.next')
#print(p_next)
print(p_next['href'])
return p_lines
2. 生成词云图
这里的方法还是和周末的那一篇类似,这里多了一个stopwords的概念,就是剔除了一些没有用的词语,貌似网上可以找到通用的一些,我这里
直接根据测试,手动剔除的。
原文是自己使用pandas统计的词频,我这里直接就传给Wordcloud了,后面再试试
#指定需要提出的词语
stopwords = {u'个',u'一个',u'这个',u'个人',u'不是',u'就是',u'一部',u'这部'
,u'我们',u'所以',u'不会',u'这种',u'没有',u'各种',u'觉得'
,u'真的',u'知道',u'还是',u'但是',u'可以',u'这么',u'因为',u'很多'}
print('stopwords',stopwords)
3. 实例代码
刚刚看了下导出的评论文件,发现有重复数据,一定是哪里有问题

刚试了下,这个影评的返回结果有毒啊
https://movie.douban.com/subject/26363254/comments?start=20&limit=20&sort=new_score&status=P
和
https://movie.douban.com/subject/26363254/comments?start=26&limit=20&sort=new_score&status=P
这2个显示的内容居然是一样的。。看来还是得通过每次下一页的href属性去获取下一页地址
# -*- coding: utf-8 -*-
"""
Created on Tue Aug 22 16:13:24 2017
@author: yuguiyang
"""
import os
import urllib
from bs4 import BeautifulSoup
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
file_name = 'douban_movie_zhanlang.txt'
#根据URL,获取页面源码
def getHtml(url):
req = urllib.request.Request(url)
page = urllib.request.urlopen(req).read().decode('utf-8')
return page
#删除文件
def clearFile(targetFile):
if os.path.exists(targetFile):
os.remove(targetFile)
#将数据保存到文件
def save2file(lines,targetFile):
with open(targetFile,'a') as file:
file.writelines(lines)
#解析当前页面
def parseCurrentPage(html):
soup = BeautifulSoup(html, "html.parser")
#获取评论信息
p_comments = soup.select('div#comments div.comment p')
p_lines=[]
for com in p_comments:
p_lines.append(com.contents[0].strip()+'\n')
#获取下一页信息,可以通过这个获取数据
p_next = soup.select_one('div#paginator a.next')
#print(p_next)
print(p_next['href'])
return p_lines
def showWordCloud(targetFile):
#指定字体,是为了显示中文
font = r'C:\Windows\Fonts\simsun.ttc'
with open(targetFile) as file:
comments = file.read()
text_cut = jieba.cut(comments , cut_all=False)
#指定需要提出的词语
stopwords = {u'个',u'一个',u'这个',u'个人',u'不是',u'就是',u'一部',u'这部'
,u'我们',u'所以',u'不会',u'这种',u'没有',u'各种',u'觉得'
,u'真的',u'知道',u'还是',u'但是',u'可以',u'这么',u'因为',u'很多'}
print('stopwords',stopwords)
wordcloud = WordCloud(font_path=font,width=800,height=400,
background_color='white',stopwords=stopwords
).generate(' '.join(text_cut))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
def main():
url = 'https://movie.douban.com/subject/26363254/comments?start={0}&limit=20&sort=new_score&status=P'
clearFile(file_name)
#直接遍历200条评论,这里要注意,超过多少页后,需要登录才可以,这里暂时还没有做,就到200
for i in range(0,200,20):
print(url.format(i))
html = getHtml(url.format(i))
movie_comments = parseCurrentPage(html)
save2file(movie_comments,file_name)
#显示词云图
showWordCloud(file_name)
if __name__=='__main__':
main()



