在数据分析中,时间序列应该很常见,这里,我们看看在pandas里面的使用
1. 日期和时间数据类型
经常使用的datetime,time,及calendar模块
from datetime import datetime
now = datetime.now()
now
Out[33]: datetime.datetime(2017, 8, 18, 9, 43, 46, 360886)
now.year
Out[34]: 2017
now.month
Out[35]: 8
now.day
Out[36]: 18
datetime.timedelta表示2个datetime对象的时间差
a = datetime(2018,8,18) - datetime(2018,8,17)
a
Out[38]: datetime.timedelta(1)
a.days
Out[39]: 1
a.seconds
Out[40]: 0
class datetime.timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, minutes=0, hours=0, weeks=0)
A timedelta object represents a duration, the difference between two dates or times.
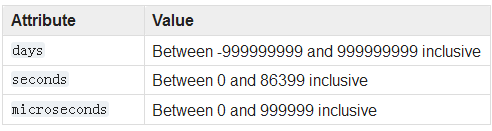
我们可以给datetime加上或者减去一个或多个timedelta
from datetime import timedelta
start = datetime(2017,8,18)
start + timedelta(days=-12)
Out[44]: datetime.datetime(2017, 8, 6, 0, 0)
start + timedelta(seconds=600)
Out[45]: datetime.datetime(2017, 8, 18, 0, 10)
2. 日期转换
pandas.to_datetime(arg, errors='raise', dayfirst=False, yearfirst=False, utc=None, box=True, format=None, exact=True, unit=None, infer_datetime_format=False, origin='unix')
dayfirst参数
#比如有时候,我们的格式,可能是day在前面,默认的话,会转换为 月/日/年
pd.to_datetime(['06/08/2017','07/08/2017'])
Out[29]: DatetimeIndex(['2017-06-08', '2017-07-08'], dtype='datetime64[ns]', freq=None)
#使用dayfirst,指定日期,日/月/年
pd.to_datetime(['06/08/2017','07/08/2017'],dayfirst=True)
Out[30]: DatetimeIndex(['2017-08-06', '2017-08-07'], dtype='datetime64[ns]', freq=None)
我们可以将一个包含日期信息的DataFrame封装成datetime
df = pd.DataFrame({'year': [2015, 2016],
'month': [2, 3],
'day': [4, 5]})
df
Out[32]:
day month year
0 4 2 2015
1 5 3 2016
pd.to_datetime(df)
Out[33]:
0 2015-02-04
1 2016-03-05
dtype: datetime64[ns]
这样转换的时候,是一定需要,最少满足年月日3列,不然会报错
ValueError: to assemble mappings requires at least that [year, month, day] be specified: [day,month] is missing
errors参数
errors : {‘ignore’, ‘raise’, ‘coerce’}, default ‘raise’
If ‘raise’, then invalid parsing will raise an exception
If ‘coerce’, then invalid parsing will be set as NaT
If ‘ignore’, then invalid parsing will return the input
如果一个日期不符合规范,默认是会报错的,我们可以通过errors参数来控制
pd.to_datetime('13/13/2017')
ValueError: month must be in 1..12
pd.to_datetime('13/13/2017',errors='ignore')
Out[38]: '13/13/2017'
pd.to_datetime('13/13/2017',errors='coerce')
Out[39]: NaT
这个NaT,就是Not a Time,在时间序列里面表示NA值
pd.to_datetime(1)
Out[21]: Timestamp('1970-01-01 00:00:00.000000001')
pd.to_datetime(10)
Out[22]: Timestamp('1970-01-01 00:00:00.000000010')
s1 = pd.Series(['2017-01-01','2017-02-01','2017-03-01']*3)
s1
Out[24]:
0 2017-01-01
1 2017-02-01
2 2017-03-01
3 2017-01-01
4 2017-02-01
5 2017-03-01
6 2017-01-01
7 2017-02-01
8 2017-03-01
dtype: object
pd.to_datetime(s1)
Out[25]:
0 2017-01-01
1 2017-02-01
2 2017-03-01
3 2017-01-01
4 2017-02-01
5 2017-03-01
6 2017-01-01
7 2017-02-01
8 2017-03-01
dtype: datetime64[ns]
3. 时间序列基础
最基本的时间序列类型,就是以时间戳为索引的Series
s = pd.Series(np.random.randn(3),index=[datetime(2018,8,1),datetime(2018,8,2),datetime(2018,8,3)])
s
Out[52]:
2018-08-01 0.360137
2018-08-02 1.422533
2018-08-03 -1.079172
dtype: float64
s.index
Out[53]: DatetimeIndex(['2018-08-01', '2018-08-02', '2018-08-03'], dtype='datetime64[ns]', freq=None)
type(s)
Out[54]: pandas.core.series.Series
不同索引的时间序列之间的算术运算会按时间自动对齐
s+s[1:]
Out[56]:
2018-08-01 NaN
2018-08-02 2.845066
2018-08-03 -2.158345
dtype: float64
s
Out[57]:
2018-08-01 0.360137
2018-08-02 1.422533
2018-08-03 -1.079172
dtype: float64
s[1:]
Out[58]:
2018-08-02 1.422533
2018-08-03 -1.079172
dtype: float64
4. 索引、选取、子集构造
对于时间序列的处理,有很方便的方式
longer_ts = pd.Series(np.random.randn(1000),
index=pd.date_range('1/1/2000', periods=1000))
longer_ts.head()
Out[76]:
2000-01-01 -0.617652
2000-01-02 1.331210
2000-01-03 0.351012
2000-01-04 -1.686123
2000-01-05 -0.426614
Freq: D, dtype: float64
longer_ts['2000-01-01':'2000-01-04']
Out[77]:
2000-01-01 -0.617652
2000-01-02 1.331210
2000-01-03 0.351012
2000-01-04 -1.686123
Freq: D, dtype: float64
longer_ts['01/01/2000':'01/04/2000']
Out[78]:
2000-01-01 -0.617652
2000-01-02 1.331210
2000-01-03 0.351012
2000-01-04 -1.686123
Freq: D, dtype: float64
对于DataFrame来说,也是一样的
pandas.date_range(start=None, end=None, periods=None, freq='D', tz=None, normalize=False, name=None, closed=None, **kwargs)
Return a fixed frequency datetime index, with day (calendar) as the default frequency
freq参数可以参考网址:http://pandas.pydata.org/pandas-docs/stable/timeseries.html#offset-aliases
#从2017-01-01开始,每个周三,生成100个
dates = pd.date_range('1/1/2017', periods=100, freq='W-WED')
long_df = pd.DataFrame(np.random.randn(100, 4),
index=dates,
columns=['Colorado', 'Texas', 'New York', 'Ohio'])
long_df.head()
Out[92]:
Colorado Texas New York Ohio
2017-01-04 -1.061954 0.324256 1.532633 -0.310599
2017-01-11 1.211990 -0.241169 -0.488018 -0.473085
2017-01-18 0.112726 -0.021406 -0.903449 -1.191892
2017-01-25 0.247537 -0.086301 1.252001 1.119687
2017-02-01 -0.058160 -0.856956 -0.783473 0.081420
#选取1月份所有数据
long_df.loc['2017-01']
Out[94]:
Colorado Texas New York Ohio
2017-01-04 -1.061954 0.324256 1.532633 -0.310599
2017-01-11 1.211990 -0.241169 -0.488018 -0.473085
2017-01-18 0.112726 -0.021406 -0.903449 -1.191892
2017-01-25 0.247537 -0.086301 1.252001 1.119687

