1.前言
本人是个学生党,在过两年就要研究生毕业了,面临着找工作,相信很多人也面临或者经历过工作,定居租房买房之类的
在此,我们来采集一下上海在售的二手房信息,有人想问,为啥不采集新房?快醒醒吧,新房可远观而不可亵玩焉,一般人都买不起,看的只会心情不好,hhhh

当然,二手房估计你也买不起!咱们拿数据说话!
2.观察网站结构
以本人所在的城市上海为例,走在上海的大街小巷,你会看到很多做房产中介的,最常见的就是链家了~
我们进一下链家的上海二手房页面:http://sh.lianjia.com/ershoufang/?utm_source=360&utm_medium=cpp&utm_term=链家二手房交易&utm_content=链家二手房&utm_campaign=品牌词
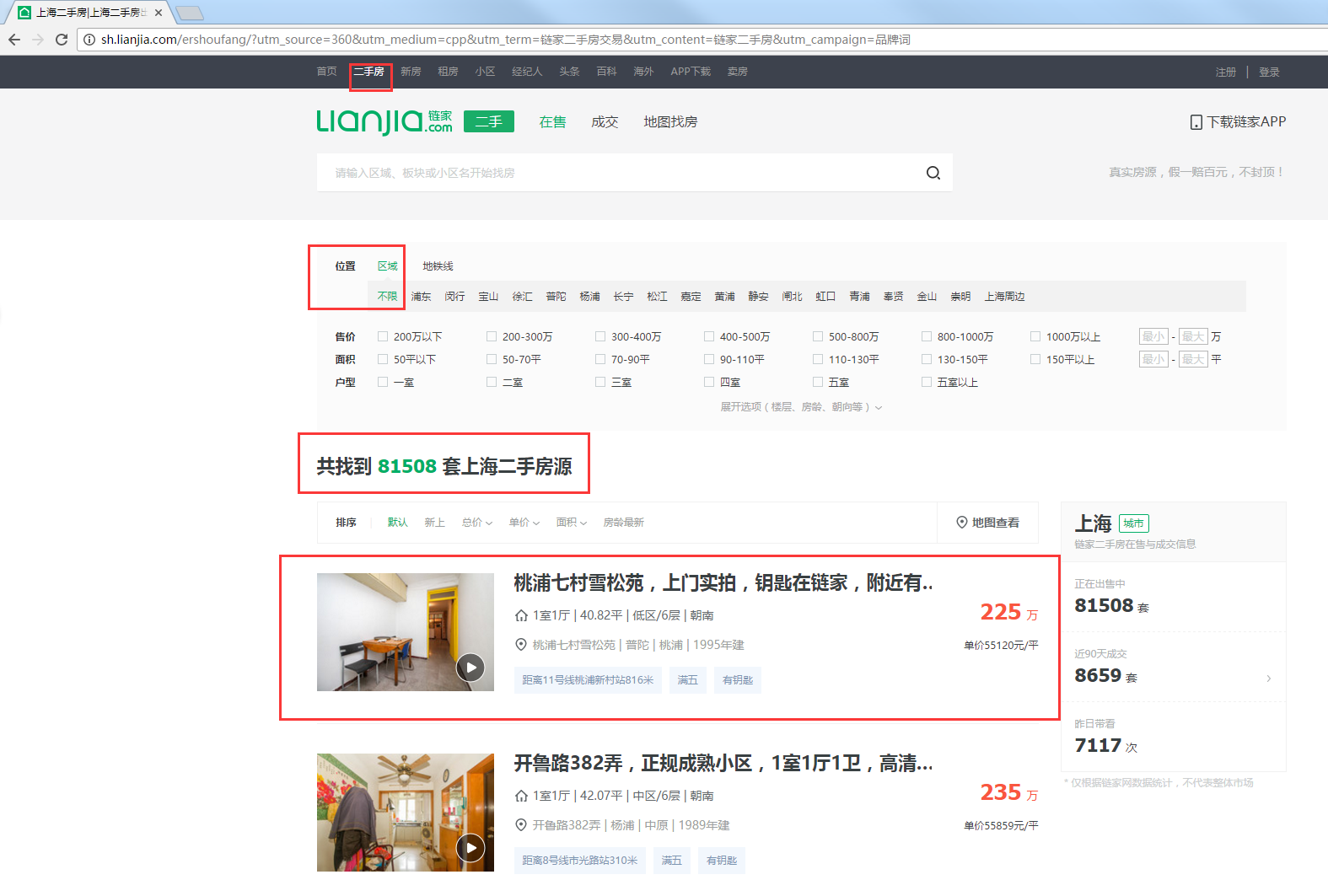
有81508套二手房源在出售,这么多!

3.寻找需要爬取信息
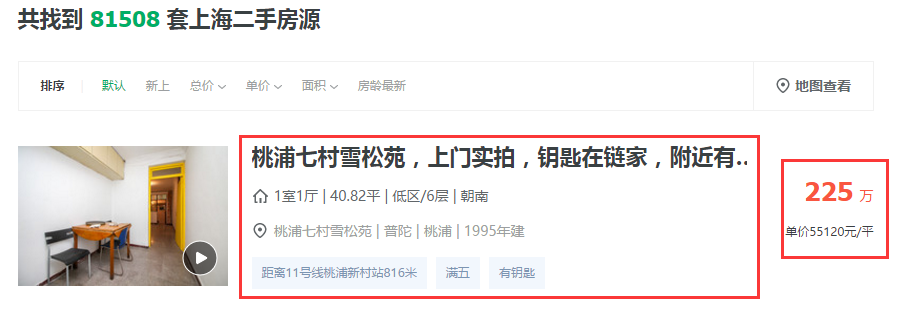
感觉这些红色框的我都想要,但是感觉还是不够全面,我们点击进去看看详细信息。
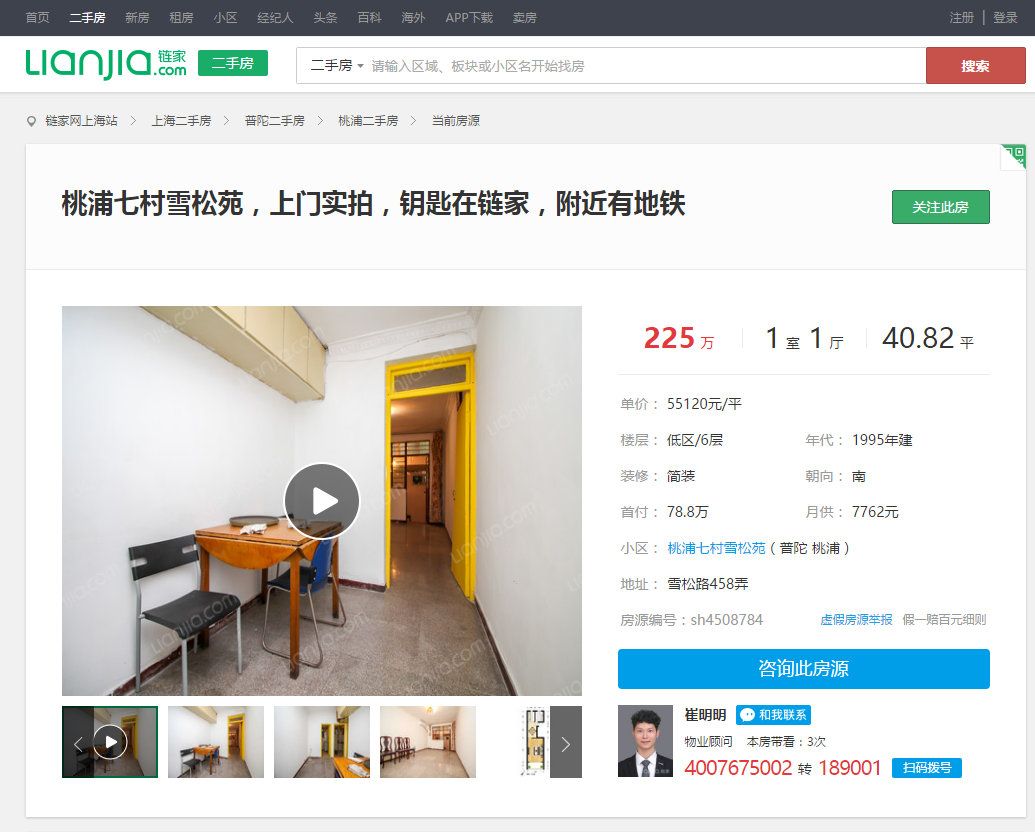
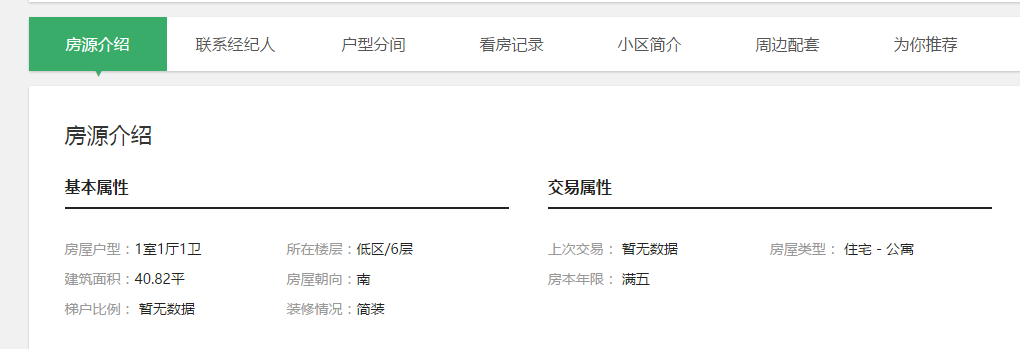
这里面的信息挺全的,当然,我根据需要的数据(可能之后分析需要用到)来选择爬取的数据
分析网页结构在我之前的文章里有写到,就不赘述了
传送门:
Python网络爬虫爬取智联招聘职位:https://ask.hellobi.com/blog/wangdawei/6710
爬取起点中文网月票榜前500名网络小说介绍:https://ask.hellobi.com/blog/wangdawei/7285
4.撰写爬虫
import requests
import re
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
ua=UserAgent()
headers1={'User-Agent': 'ua.random'}
houseary=[]
domain='http://sh.lianjia.com'
for i in range(1,400):
res=requests.get('http://sh.lianjia.com/ershoufang/d'+str(i),headers=headers1)
soup = BeautifulSoup(res.text,'html.parser')
for j in range(0,29):
url1=soup.select('.prop-title a')[j]['href']
url=domain+url1
houseary.append(gethousedetail1(url,soup,j))
def gethousedetail1(url,soup,j):
info={}
s=soup.select('.info-col a')[1+3*j]
pat='<a.*?>(.*?)</a>'
info['所在区']=''.join(list(re.compile(pat).findall(str(s))))
s1=soup.select('.info-col a')[0+3*j]
pat1='<span.*?>(.*?)</span>'
info['具体地点']=''.join(list(re.compile(pat1).findall(str(s1))))
s2=soup.select('.info-col a')[2+3*j]
pat2='<a.*?>(.*?)</a>'
info['位置']=''.join(list(re.compile(pat2).findall(str(s2))))
q=requests.get(url)
soup=BeautifulSoup(q.text,'html.parser')
for dd in soup.select('.content li'):
a=dd.get_text(strip=True)
if ':' in a:
key,value=a.split(':')
info[key]=value
info['总价']=soup.select('.bold')[0].text.strip()
return info
写了详细注释,相信萌萌的你可以看懂~

我们来看一下爬的结果:
houseary
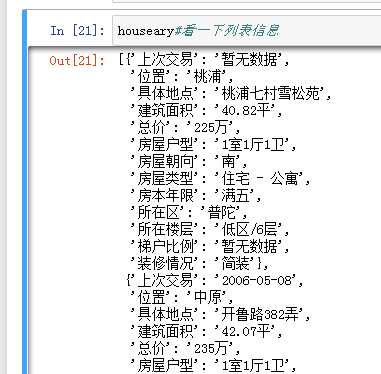
就是将每次爬取的信息做成dict依次添加在list中
接下来使用pandas神器~
import pandas
df=pandas.DataFrame(houseary)
df
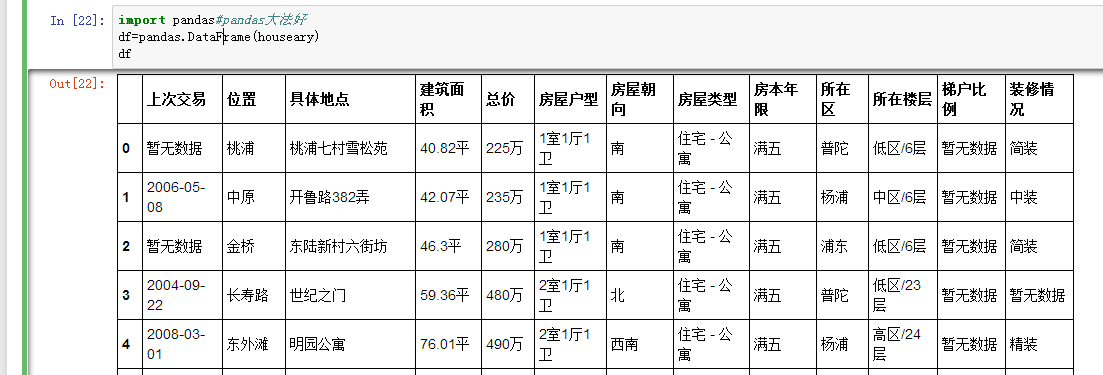
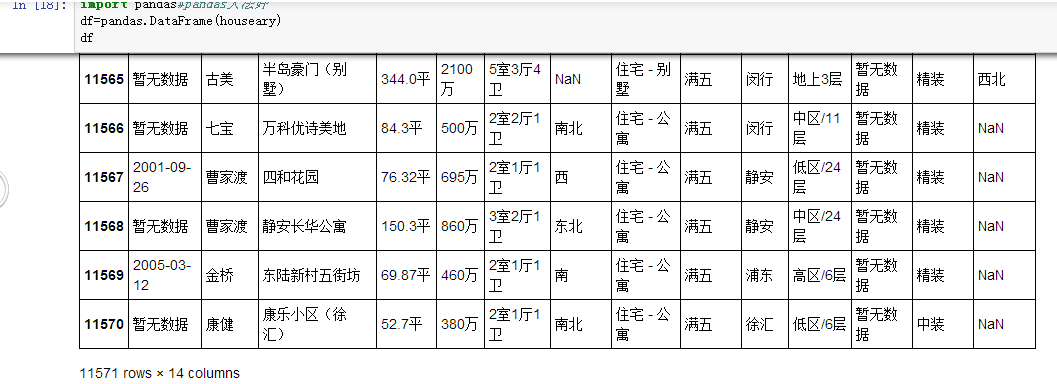
考虑到主程序写了双重for循环,函数里写了循环,所以时间复杂度是O(n^3),对于一个算法,一般是不可以接受的,好吧,萌萌的我只能接受,如果你问我为什么,我只能说,我写不出低复杂度的了。。。爬了这1w+条数据用了我1小时时间。。。各位dalao如果有方法可以指点一下,之后我想学习多线程提高爬取速度~

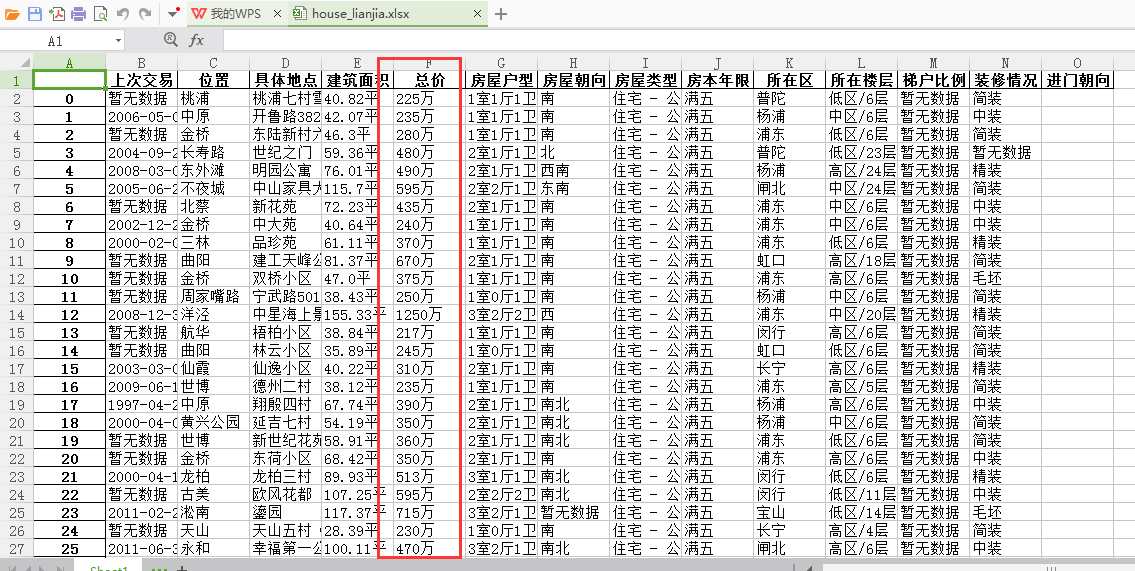
最后存到本地excel文件中
df.to_excel('house_lianjia.xlsx')
5.结语
看到这价格是不是有句mmp想说

之后会写一篇《Python数据采集和分析告诉你为何上海的二手房你都买不起!(二)》的数据分析和可视化的文章深入分析一下这次抓到的数据~敬请期待,么么哒

对爬虫有兴趣的小伙伴可以加我微信号:lezi10121643,记得加好友备注来自天善智能~
下次见~喜欢你就点个赞呗

