1.前言
昨晚学了一下bs4的BeautifulSoup,因为之前用的都是正则,感觉两者比起来,正则更加灵活,但控制不好就会爬到多余信息,而BeautifulSoup更加系统性。
2.观察网页结构
进入起点原创风云榜:http://r.qidian.com/yuepiao?chn=-1
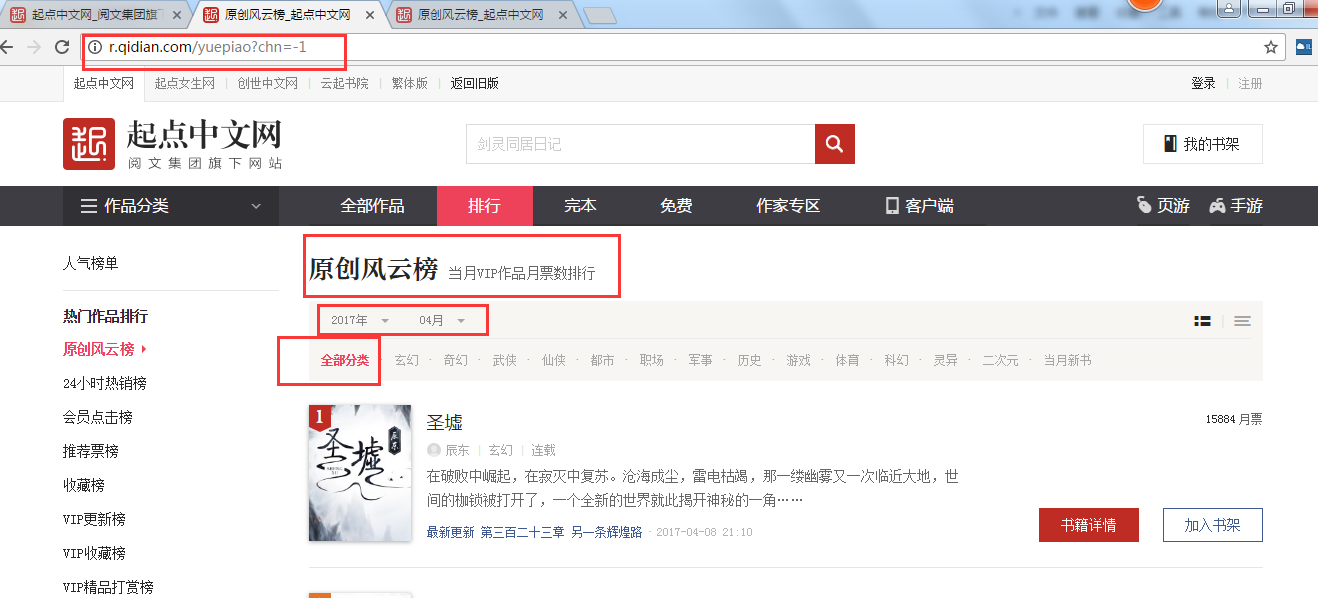
老套路,懂我的人都知道我要看看有多少内容和页数需要爬。

翻到页面底部,发现有25页
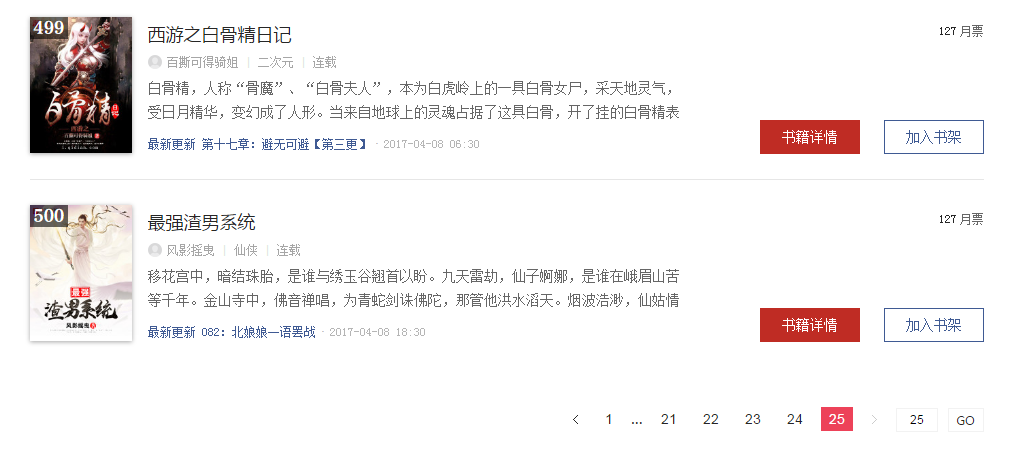
去最后一页看了一下,是第500个作品
在谷歌浏览器(推荐)按下F12进入贤者模式,哦不,开发者模式。。。差点暴露了什么
我们跳到第一页
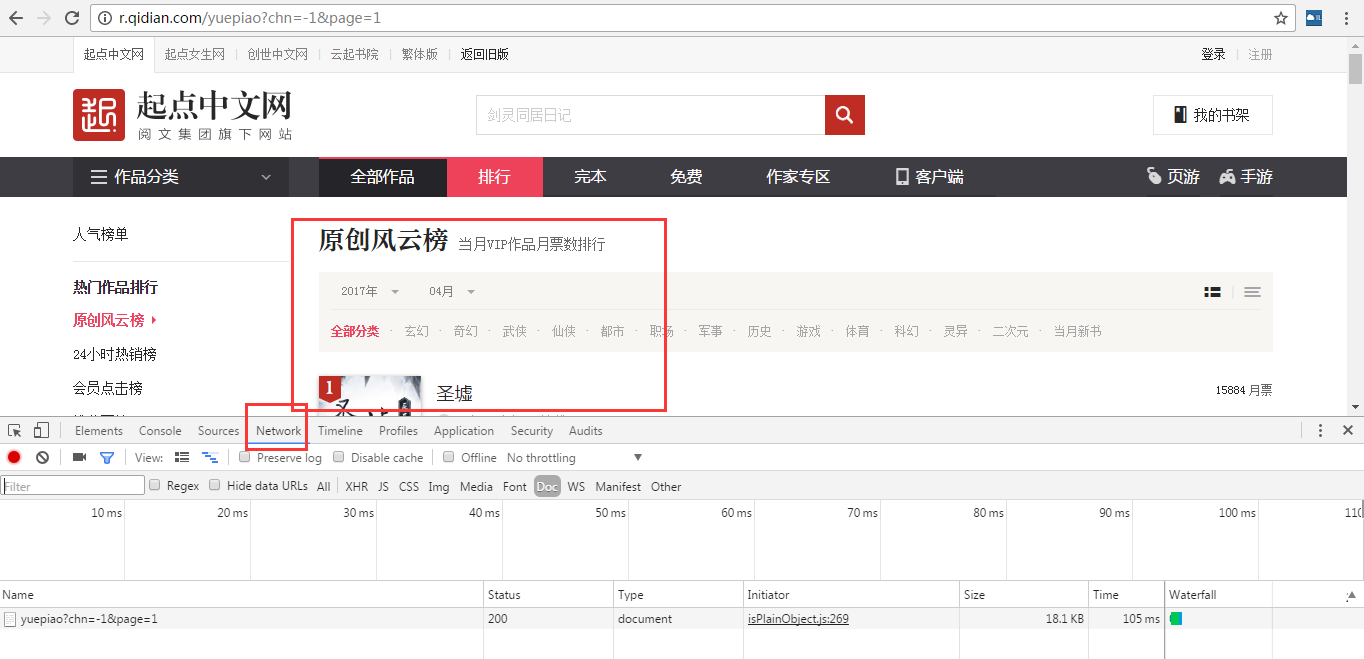
按F5刷新网页
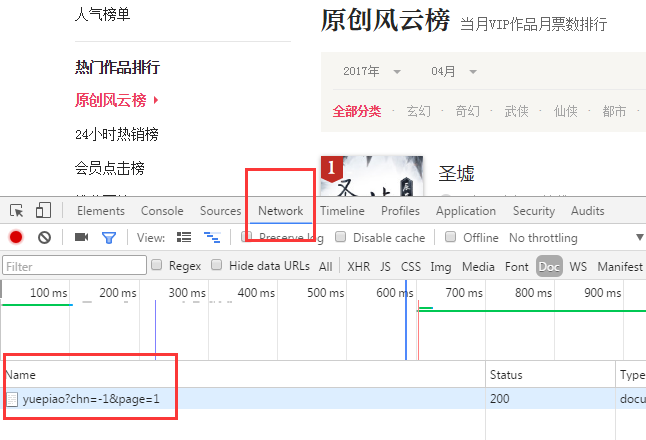
点击network,点击下面红框消息

看Header,可以知道我们get请求的访问返回200表示正常访问
在谷歌浏览器中输入https://chrome.google.com/webstore/detail/infolite/ipjbadabbpedegielkhgpiekdlmfpgal,安装小插件(丘老师开发的定位小插件),为后文定位准确有很大帮助。
安装好之后,浏览器右上角会出现
点击之后会出现一个图形界面
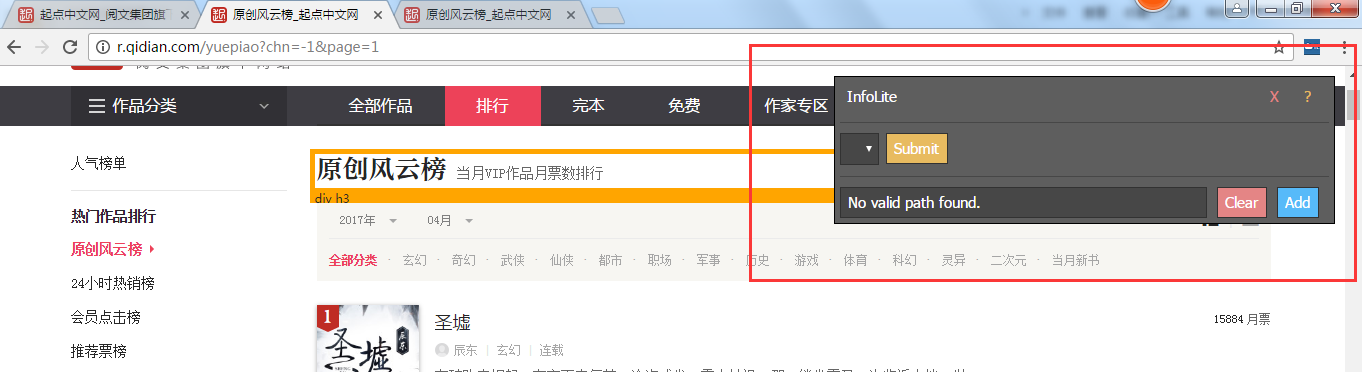
比如我要爬作品名字,鼠标点击页面作品,会出现绿色,表示选中了,同时左边和上面出现的黄色表示同时选中了,但我们不要左边和上面的黄色信息(听起来怪怪的!),然后点击左边和上面的黄的区域,黄色区域变红色了(红色表示不选择)
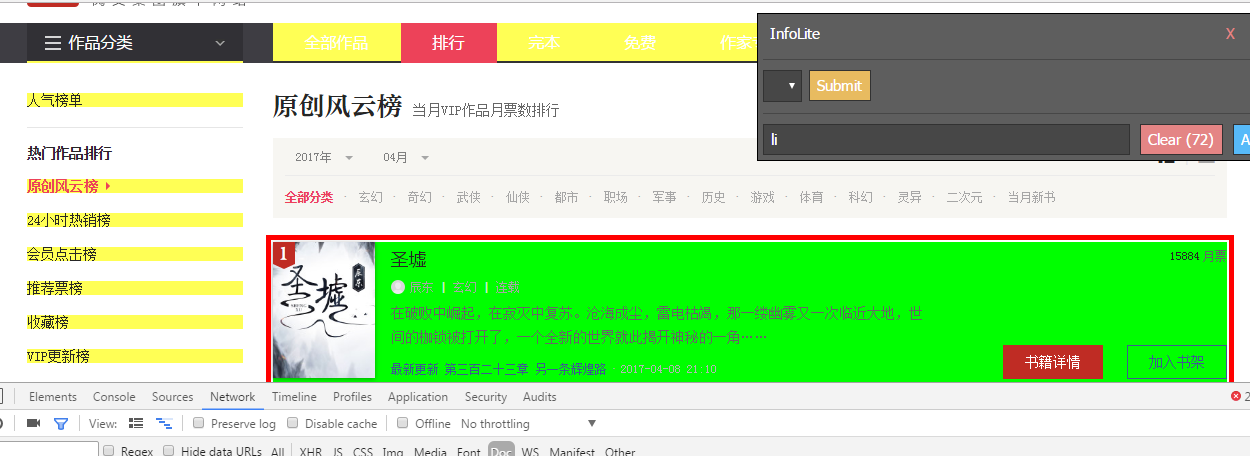
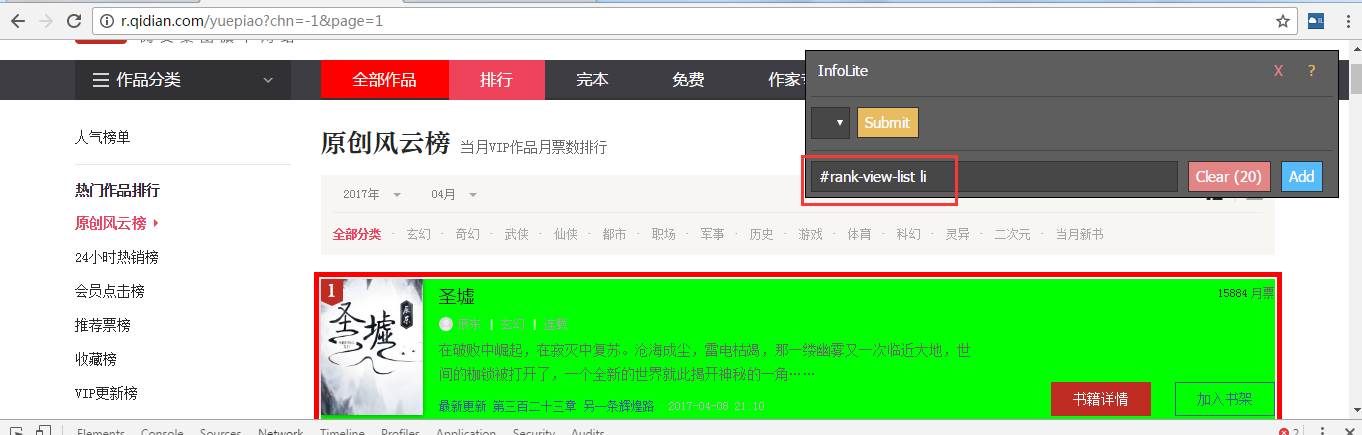
此时只有文章名字是绿色了,同时插件界面上显示rank-view-list li,经测试要把#去掉,定位完成。
在Preview中定位到我们要的部分
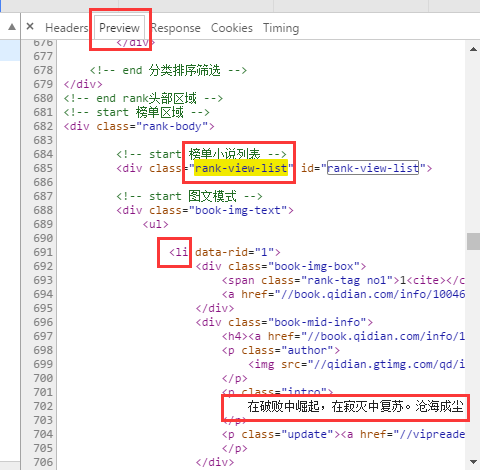
接下来使用BeautifulSoup(美丽汤)找出我们要的内容
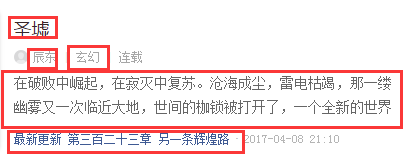
书名,作者,类型,简介,最新章节,书的地址链接 这些是我们要的
3.编写爬虫
import requests
from bs4 import BeautifulSoup
res=requests.get('http://r.qidian.com/yuepiao?chn=-1&page=1')
soup=BeautifulSoup(res.text,'html.parser')
筛选器
for news in soup.select('.rank-view-list li'):
print(news)
结果如下:
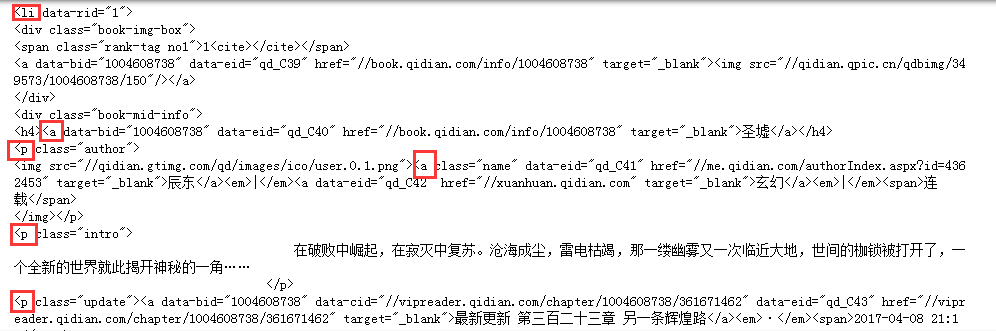
注意这些标签(因为美丽汤提取是基于标签的)
经过测试
for news in soup.select('.rank-view-list li'):
print(news.select('a')[1].text,news.select('a')[2].text,news.select('a')[3].text,news.select('p')[1].text,news.select('p')[2].text,news.select('a')[0]['href'])
可以设置提取内容如上面代码所示
提取结果是:

很乱,把内容存成字典格式再存放到列表中:
for news in soup.select('.rank-view-list li'):
newsary.append({'title':news.select('a')[1].text,'name':news.select('a')[2].text,'style':news.select('a')[3].text,'describe':news.select('p')[2].text,'url':news.select('a')[0]['href']})
len(newsary)
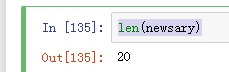
显示每页20个作品
import pandas
newsdf=pandas.DataFrame(newsary)
newsdf
使用pandas的DataFrame格式存放
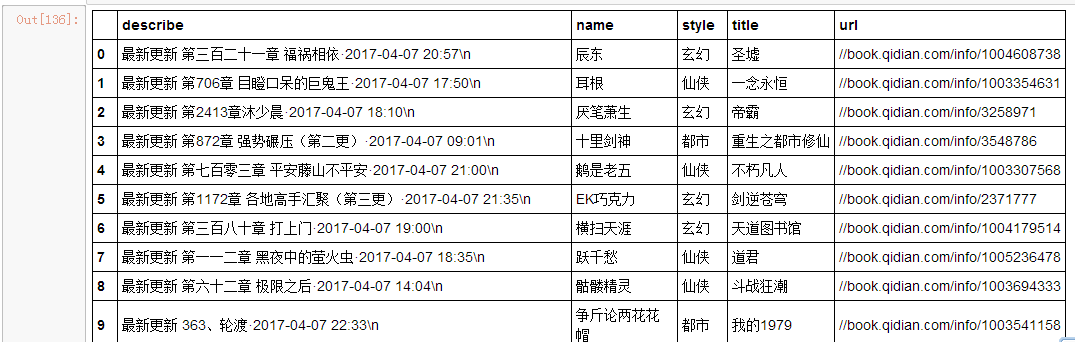
是不是舒服多了
但是,这只是第一页的信息,接下来老套路,观察网页结构,在我之前文章(爬取智联招聘信息里有写到:https://ask.hellobi.com/blog/wangdawei/6710)
使用循环爬取25页内容
import requests
from bs4 import BeautifulSoup
newsary=[]
for i in range(25):
res=requests.get('http://r.qidian.com/yuepiao?chn=-1&page='+str(i))
soup=BeautifulSoup(res.text,'html.parser')
for news in soup.select('.rank-view-list li'):
newsary.append({'title':news.select('a')[1].text,'name':news.select('a')[2].text,'style':news.select('a')[3].text,'describe':news.select('p')[1].text,'lastest':news.select('p')[2].text,'url':news.select('a')[0]['href']})
import pandas
newsdf=pandas.DataFrame(newsary)
newsdf
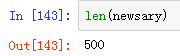
这次终于完整了
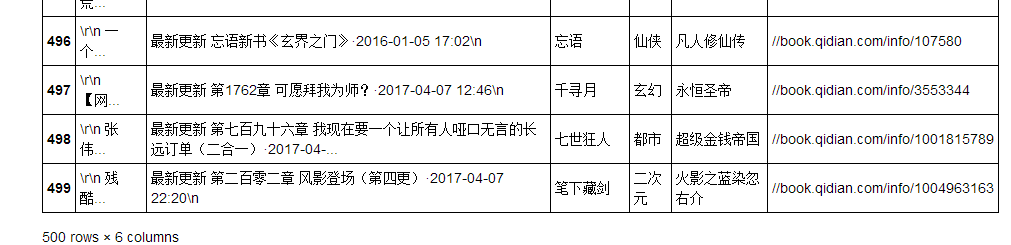
最后存到本地~
newsdf.to_excel('qidian_rank1.xlsx')
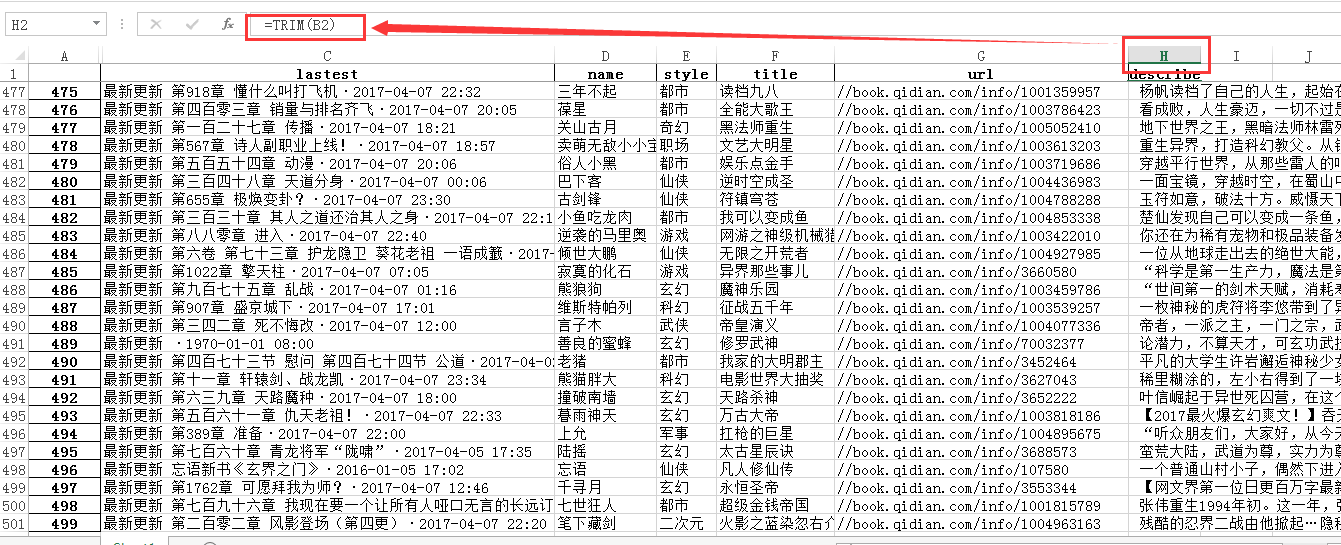
用excel做一些后处理,把简介前面的空格去掉,换一下列之间的顺序(更符合正常阅读)
4.结果展现