为什么写这篇文章?
现在大数据这个词应该说比空气中氧气的成分占比都要大。前几天项目遇到一个问题,有一部分系统日志数据需要通过大数据平台来处理和分析,数据量不算大5年每月500万左右,在把这部分数据导到hdfs进行存储时候,那问题来了,首先这仅仅是日志数据,hdfs文件的备份策略默认是3倍(有人会说你可以修改备份策略,不让数据备份3份,这不是讨论的核心问题),再加上我们的大数据平台资源有限,这部分数据是否需要全部导入到大数据平台?这时候我就在想,我分析这部分数据的目标是什么?5年的数据量中时间跨度有多大的数据是用来支撑我的分析目标的?假如公司的大数据平台资源足够,那这部分数据是否有必要全部导入?这时候我就想到了几年前读过的《DW2.0:下一代数据仓库的构架》中提到的数据生命周期的含义,怎么去说服周边的人在大数据平台架构下去接纳这种架构。文章内容仅仅是说明要点,
PS:某东搜了一下,这本书已经不再销售,最新的一篇评论是在2012年12月,我当时看的也是网上流传的扫描电子版。
作者:数据仓库之父比尔·恩门(Bill Inmon),最早的数据仓库概念提出者,在数据库技术管理与数据库设计方面,拥有逾35年的经验。他是“企业信息工厂”的合作创始人与“政府信息工厂”的创始人。恩门先生在上世纪80年代,其《建立数据仓库》一书中定义了数据仓库的概念,随后又给出了更为精确的定义:数据仓库是在企业管理和决策中面向主题的、集成的、与时间相关的、不可修改的数据集合。与其他数据库应用不同的是,数据仓库更像一种过程,对分布在企业内部各处的业务数据的整合、加工和分析的过程。在2010年前后出现了《DW2.0:下一代数据仓库的构架》 ,书中讨论了DW2.0的几个重要特征:数据的生命周期,数据仓库应该包含非结构化数据,元数据的重要性,数据仓库的技术基础。
1、数据仓库1.0架构简述
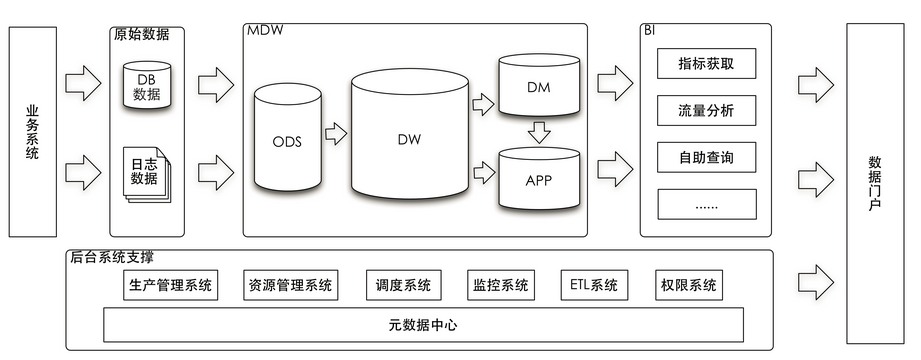
数据仓库既包含粒状数据又包含整合数据,这就是他的奥秘,个人感觉也是数据仓库的最核心思想。Bill Inmon 提出的以数据和技术驱动的数据仓库架构和Ralph Kimball提出的业务导向的数据仓库架构一直是大家争论的地方,现阶段实际项目中我们通常会结合两种架构思想去搭建企业数据仓库,但对于数据仓库既包含粒状数据又包含整合数据这一点是任何一种架构都必须满足的。在第一代数据仓库架构中还有一个重要的特点就是包含历史数据的集合,需要存放有价值的数年前的数据。下图是通常情况下我们采用的数据仓库架构,不同的企业针对自身的业务特点在实际搭建数据仓库时会有所不同。
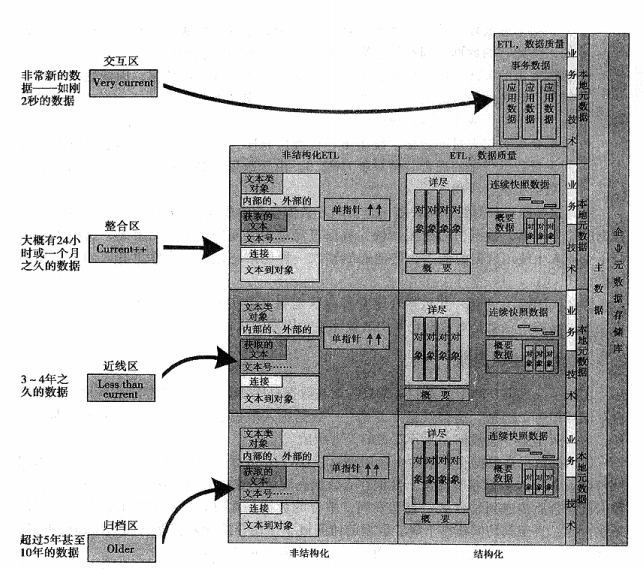
2、DW2.0架构中的数据生命周期理论
DW2.0之所以提出,而且得到一些企业人士的认可,是因为数据仓库基础建设成本的不断增加,通过元数据降低数据丢失风险,数据需要满足快速访问,数据量的不断增加。而这中间最大的不同就是数据生命周期的提出,在DW2.0数据仓库中,有四个主要的数据生命周期区:
*交互区:数据仓库以更新模式下完成构建,在交互区经过数据调整后就会进入整合区,一般为事务型数据。
*整合区:数据在这里经过整合并完成分析处理,使用频率最高,但一般2-3年之后数据访问频率会急剧下降 。
*近线区:作为整合区数据的一个缓存区域,这个区域不是必须的,有时候数据可以直接从整合区进入归档区,而在数据访问频率和效率差别较大时,需要通过近线区来处理。
*归档区:存放访问概率显著下降但仍有可能被访问的数据,归档区的数据可以从近线区也可以从整合区进入,通常是5-10年,或者更长时间周期的数据。但是目前社会发展的情况来看,3年以上的数据被访问的概率已经极低,可以进入归档区,而不一定是5年以上的。
下图借用《DW2.0:下一代数据仓库的构架》 中的插图。
DW2.0中的另一个重要思想,将非结构化数据纳入到数据仓库中,这部分不做太多讨论,以现在数据多样性来说,非结构化数据是必不可少的,相比较DW2.0概念刚提出的2010年,已经不算新鲜的。对于整个DW2.0生命周期理论的更详细介绍,推荐大家去看书中的讲解,我这里主要做抛砖引玉。
3、DW2.0架构在大数据架构中的必要性
现在很多大数据厂商或者专家学者在做大数据介绍时会举一个例子,客户到银行查多年前账户明细,银行一般会让客户等待几天时间才能出明细,本人没有参与过银行数据体系架构,猜测应该是使用了DW2.0类似的架构。然后就开始“套路”了:采用基于hadoop的大数据平台架构能给解决部分客户的这种特殊性需求,从根本上解决海量数据查询效率低的问题。
做产品的童鞋们都知道,在做产品迭代的时候不会把所有客户反馈的产品功能诉求都融入到下一个版本中,产品迭代围绕的是目标客户群体的普遍性需求和产品目标。上面提到的银行查询账户明细的需求是普遍性需求还是特殊性需求,预期实现这个需求的投入有多大?大数据架构体系下对于基础设施建设的资源成本消耗,是不得不考虑的一个因素。
你要跟我说数据就是资产就是财富,我想说你被“洗脑 ”了吧。
三年,这应该是大多数行业多数场景下数据生命周期的重要阶段。对于每个区的时间点划分,除了数据使用频率的变化作为主要依据之外,数据资产质量也是必须考虑的,比如系统日志数据,那它的数据生命周期就很短,每个区的划分就会完全不同,1年或者2年以上的数据都有可能要进入归档区;企业经营数据,对于互联网金融企业作为风控的重要依据,近3年数据已经是完全够用的,严格意义来说,一年以上的数据在整个风控体系中的占比就已经很低了;对于国家经济研究部门,数据生命周期的划分就会拉长,甚至超过10年或者20年以上的数据才会进入归档区。

