翻译/编辑/原创:Vivian Ouyang 数据圈资深成员
作者简介:美国达拉斯一家医院数据中心工作,职位是data scientist。主要做healthcare方面的数据分析建模
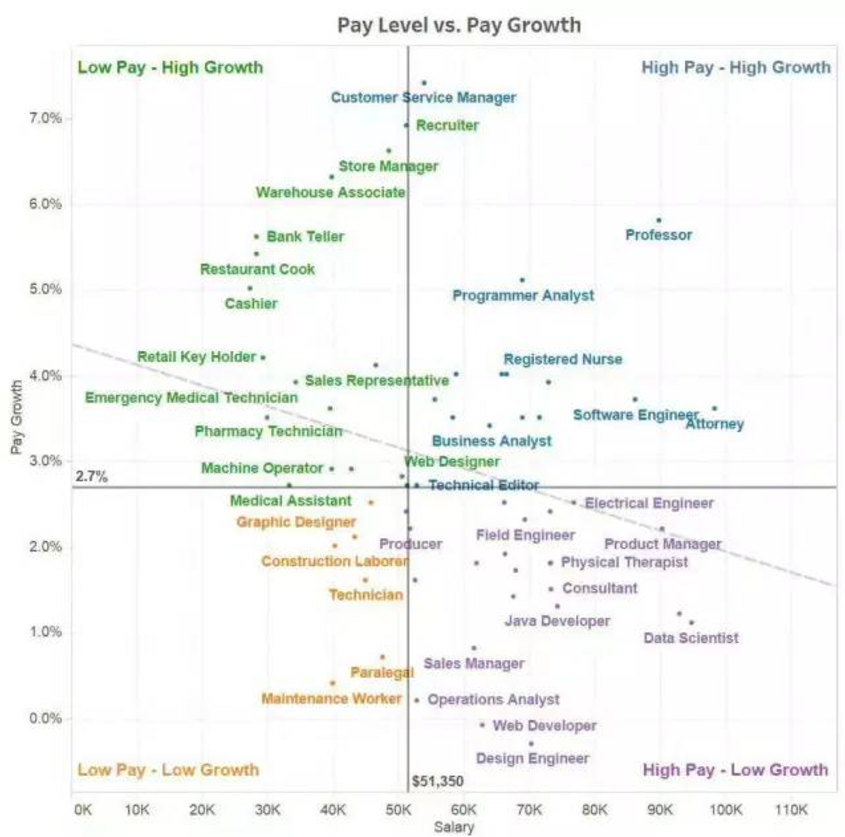
这个介绍主要是方便刚入行的数据科学家。通过这个指导,使你直接解决机器学习的问题以及从中获得经验。先看看薪水,对号入座:
而且我会尽量用简单易懂的方式来介绍每一个算法,不会涉及很多数学,而是帮助你从原理上理解每个算法,每一个算法都附上R和Python的程序来帮助你直接去应用程序解决问题。一般经常使用的机器学习算法有以下11种
1.线性回归Linear Regression
2.逻辑回归Logistic Regression
3. 决策树Decision Tree
4.随机森林Random Forest
5.支持向量机SVM
6.朴素贝叶斯Naive Bayes
7.最近邻居法KNN
8.K平均算法K-Means
9.神经网络Neural Networks
10.降维算法Dimensionality Reduction Algorithms
11.梯度提升Gradient Boost & Adaboost
首先第一期介绍线性回归(1)。我会一个专题一个专题的进行介绍。线性回归算是所有方法的入门,但是也是应用很广的一个模型。比如逻辑回归本质上和线性回归也有共通的地方。所以把它作为第一个介绍的项目。
线性回归Linear Regression
线性回归一般用来估计实际连续目标变量的值(比如房价或者销售额)。在这里我们用最优的一条线来表示自变量(X)和因变量(Y)之间的关系。这条最优的线就是回归线然后可以用一个简单的函数表示
Y=aX+b
X是“独立变量”( Independent Variable),也可以叫,解释变量,输入变量,预测变量,它是表原因的。国内一般翻译为“自变量”。Y是“依赖变量”(Dependent Variable,从字面上硬翻),也可以叫,输出变量,响应变量,或者因变量,它是表结果的,是你的目标变量。其中a被称为斜率而b被称为截距。而系数a和b的值是使每一个数据点与回归线之间距离的平方的和最小的解。下面是用散点图来表示回归线。你可以看到一条黑色的线穿过了数据点
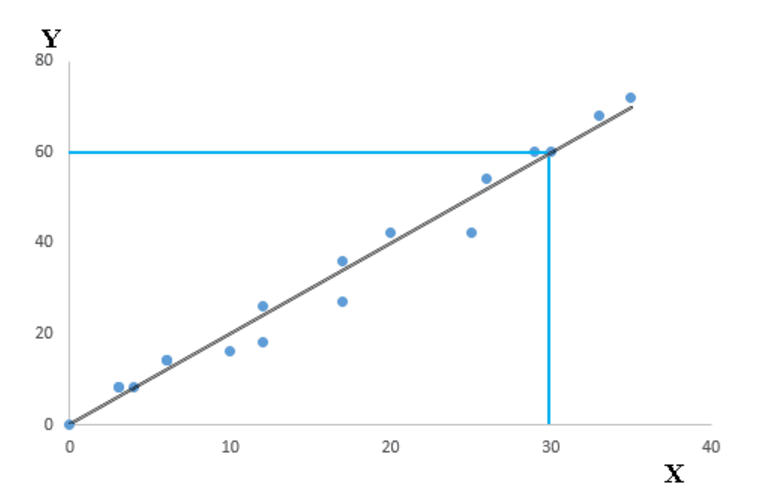
从上面的图可以看到,这条回归线穿过了坐标(0,0),(4,8)还有(30,60),我们可以用简单的高中数学知识解方程得到系数a=2,系数b=0.然后我们的回归方程可以写成
Y= 2*X + 0=2X
下面一个问题是我们怎么找到最优的回归线呢,简单来说,最优的回归线就是能用X的值更准确的得到Y的值的那条线。如下图,predicted是用X预测的Y,而actual是指实际的Y值。换句话说,就是用X得到的预测Y值和实际的Y值之间的不同最小的回归方程,这个不同称为误差(error)。
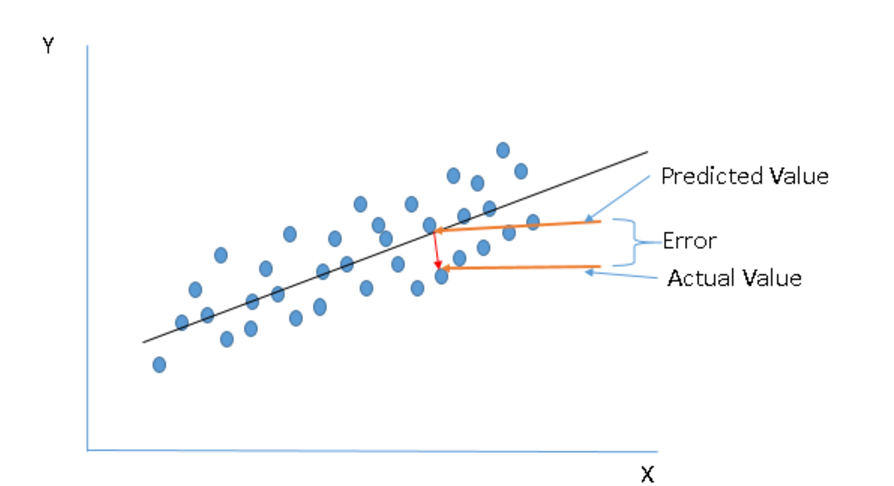
所谓不同最小,就是指误差最小,一般有三种方式来判断最小值
I.所有误差的和(∑error)
II.所有误差绝对值的和(∑|error|)
III. 所有误差的平方的和(∑error^2),又被称为平方误差和(SSE)
使用I这种方法容易让正值和负值进行一定的抵消,显然有时候其实有很大的error但是抵消了得到0,显示没有error。所以这种方法一般不会被采用。而II和III比较类似,都很好的避免了I的正负抵消的问题,但是一般来说∑error^2会大于∑|error|,从而让预测Y值和实际的Y值的不同更加的显著和容易被探测到。所以一般的回归分析中,我们的回归方程中的参数都是使III最小而求得的值。
介绍完了怎么计算回归模型的参数,我们再来谈一下,用什么样的指标去度量线性回归的表现呢。肯定有人会说可以用SSE来度量啊。确实可以,但是SSE度量线性回归的表现有一个问题。下面我们用一个简单的例子来说明,先看下面的两个数据表格
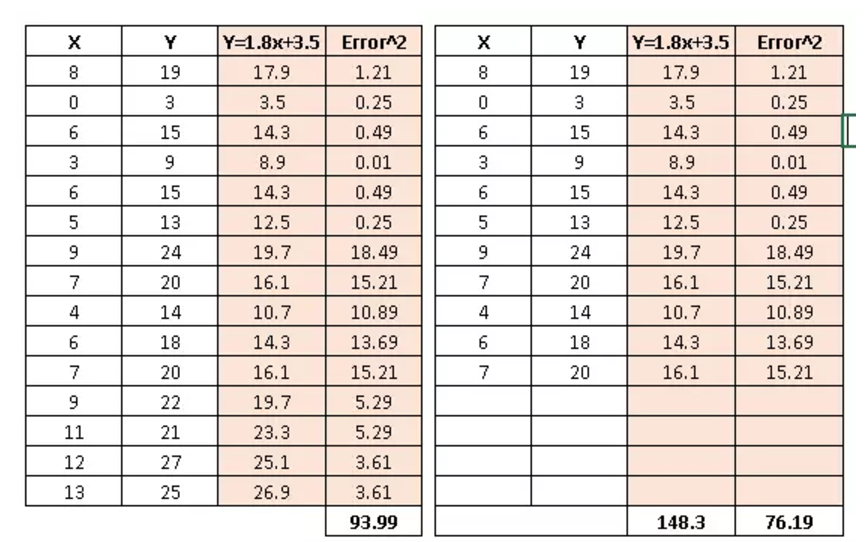
当我减少数据集的数据点时,我的SSE会从93.99降到76.19,所以SSE对于数据集中的数据个数比较敏感,有时候并不是你的线性模型好,而是你的数据个数比较少。
第二个可以判断线性模型好坏的是R平方(R-square),R平方是指输出量Y可以被输入量X解释的百分比,公式如下
R-square=1-(∑(Y_预测-Y_实际)^2)/(∑(Y_实际-Y_均值)^2)
Y_实际 是实际的Y数据,Y_预测是用X算出来的Y,而Y_均值是Y的均值。R平方的范围在0到1之间。0代表这个回归模型根本解释不了Y的变化,1 表示这个回归模型可以充分地解释Y的方差变化。一般来说R平方越高,模型应该越好,但是R平方有和SSE类似的毛病。它不好的在于,随着你输入变量X增多,它总会增加,甚至你不断的加随机的输入变量(变量与Y完全不相干),它还是会不断变大。所以有时候它的增大是假的。
正是因为这个原因,我们需要第三个常用的指标来判断线性回归的表现。那个指标就是校正R平方(Adjusted R-square)。校正R平方可以理解为,给进入模型的输入变量一个惩罚机制,你加入的输入变量X越多,我的惩罚越大。因此校正R平方可以理解为计算真正和Y有关的输入变量X可以解释的Y的百分比。它引入了模型的自由度,自由度从统计上来讲,是指当以样本的统计量来估计总体的参数时,样本中独立或能自由变化的数据的个数。在这里为了方便理解,可以认为是代表着引入输入变量X的个数。因此如果加入的输入变量能解释的Y的百分比无法抗衡自由度的增加的话,你的校正R平方不会增加而是会降低。一般校正R平方用于有多个X的情况,就是多元回归模型。 下面是计算公式。

R^2是样本的R平方值,N是整体样本量,p是你输入的X的个数。
既然说到了多元回归,就来简单介绍一下多元回归吧。回归分析一般有两类:一类是简单的回归分析以及多元回归分析。简单回归分析的输入变量就一个X,多元回归分析就是有多个输入变量X1,X2,...,Xk。这个世界就是一个复杂的世界,所以一般来说,没有任何一个事情是只有一个因素来决定的,所以一般来说,当我们想预测某个连续变量的时候(例如你的血压或者工资,或者保险费),把多个因素加在线性回归里会比只用单一的因素进行预测更加准确。
在多元线性回归里面,最容易碰到的就是输入变量X1,X2,...,Xk之间有很强的相关性,这个现象一般叫做多重共线性问题。这个是每一个做线性模型的分析师们需要避免的情况,很多人做特征工程,其中重要的一步就是输入变量筛选,而这个筛选很大的原因是为了避免多重共线性的问题。为了避免这样的问题,我们使用一个叫方差膨胀因子VIF(Variance Inflation Factor)来测量多重共线性。如果这个多元线性模型没有共线性的问题,那么所有的输入变量的VIF基本上应该都小于2。如果有大于的情况,你需要计算输入变量之间的相关性来进行筛选。
当然除了多重共线性的问题,多元回归有时候还会遇到异方差,以及Y本身是自相关的,比如时间数据,感兴趣的朋友可以去自行寻找相关的介绍,我就不详细介绍了,因为可能涉及很多理论公式。除此以外我们还有多项式回归分析和曲线回归分析。下面我就介绍怎么用python和R来玩转线性回归。
python的程序
#首先加载需要的包和模块比如pandas,numpy等等#
from sklearn import linear_model
#然后加载训练数据和预测数据(检验数据)#
#确定输入变量和输出变量,其中输出变量需要是数值变量#
x_train=input_variables_training_datasets#训练数据中的输入变量#
y_train=target_variables_training_datasets #训练数据中的输出变量#
x_test=input_variables_test_datasets#预测数据中的输入变量#
#运行回归分析的函数
linear = linear_model.LinearRegression()
#用训练数据训练这个回归模型然后检查结果和参数#
linear.fit(x_train, y_train)
linear.score(x_train, y_train)
#显示参数和截距
print('coefficient: \n', linear.coef_)
print('intercept: \n', linear.intercept_)
#用训练的模型来预测模型中的输出变量Y#
predicted= linear.predict(x_test)
R的程序
#导入训练数据集以及预测数据集
#确定输入变量和输出变量,其中输出变量需要是数值变量#
x_train <- input_variables_training_datasets#训练数据中的输入变量#
y_train <- target_variables_training_datasets#训练数据中的输出变量#
x_test <- input_variables_test_datasets #预测数据中的输入变量#
x <- cbind(x_train,y_train)#生成训练数据集#
#用训练数据训练这个回归模型然后检查结果和参数#
linear <- lm(y_train ~ ., data = x)
#summary()显示结果和参数值#
summary(linear)
#用训练的模型来预测预测模型中的输出变量Y#
predicted= predict(linear,x_test)
下面我将使用美国AllState保险公司在Kaggle上的一个数据来演示一个多元线性回归的学习案例。每一行代表一个保险理赔(claims),我们需要用公司提供的这些变量来预测最终损失(loss),其中第一列是id号,这个数据集有连续变量和非连续变量,为了方便理解,我们只选取部分的变量来做多元回归,数据集我会附在这一期的最后AllState的压缩文件中。
下面是运行的R程序
setwd("C://Allstate") #设置你自己的路径##
full<-read.csv("train.csv")
test<-read.csv("test.csv")
#选取cat2,cat7,cat10,cat11,cat12,cat57,cat72,cat80,cat79,cat81,cat87,cat89,cat101,cont2,cont3,cont7,cont11,cont12作为自变量
feautres<-c("cat2","cat7","cat10","cat11","cat12","cat57","cat72","cat80","cat79","cat81","cat87","cat101","cont2","cont3","cont7","cont11","cont12","loss")
feautres_1<-c("cat2","cat7","cat10","cat11","cat12","cat57","cat72","cat80","cat79","cat81","cat87","cat101","cont2","cont3","cont7","cont11","cont12")
full_feautres<-full[,feautres]
lm.fit <- lm(loss ~ ., data = full_feautres) #运行回归程序#
lm.predict.test<- predict(lm.fit, newdata = test) #预测值#
All state的数据可以在本文下载,衔接如下
链接: https://pan.baidu.com/s/1hrJh4EC 密码: wsfd
数据挖掘与大数据分析
(datakong)

