
数据提取和处理
确定建模目标
数据提取需要服务于建模的目的,即这个模型回答了什么问题。 在开篇我就提了这次建模的目标是纯粹通过英雄选择,来预测比赛胜负,所以建模数据中的一条记录就是一场比赛。 而一条记录的具体内容就是天辉5名玩家和夜魇5名玩家,每人在这场比赛里选择的英雄,和最终的比赛结果。 因为一场比赛的流程是,玩家进入游戏,双方选择英雄,然后正式开始比赛,所以这里用到的是英雄选择之后,比赛正式开始之前的信息,预测比赛结束时的胜负。
另外我还想探讨一下如果想把比赛正式开始之后的信息也加入到模型中去进行预测,需要注意些什么。 举例来说我们想用天辉夜魇双方的英雄击杀总数来预测比赛胜负,这里需要注意两点:首先击杀数是随着比赛进行时间而变化的, 其次击杀数领先的一方有显著更高的几率获胜,特别是游戏进入尾声时,击杀数领先方几乎都是获胜方,虽然有例外存在。 所以用击杀数建模时,此变量必须添加时间这一维度,比如比赛开始十分钟时的击杀数差值,或者比赛总时长过半时的击杀数比等等。 然而 Steam API 只提供了比赛结束时的双方击杀数,所以我并不准备把这个变量加入模型。 不过把结束击杀数作为预测目标(因变量),那又是另一个有趣的模型了。
数据提取
首先,我提取了5000场比赛的基本信息,想对比赛数据有一个直观的了解。用到的是我整合后的 R 程序“dota2_data_query.R”, 从 “链接1” 查看代码。 用法是指定一条 match_id 给 mid.a,和想要提取比赛的总数给 N,程序就会自动找到对应的 match_seq_num,然后往后开始提取 N 条比赛信息。 最后程序会把所有信息汇总到一个 data.table,并储存在当前工作文件夹下的一个 rds 文件“RDSxxxxxx”里,“xxxxxx”即为 mid.a。
因为 Steam 服务器对一段时间内的 API 访问数或者访问数据量有限制(具体不明), 用get_match_history_by_sequence_num() 函数以最大值100条提取数据时,很快就会因为达到上限而无法继续,需要等待一段时间再发送请求。 所以在我程序里设置了1次提取数据的数量,目前是10。 总体数据提取效率还可以,提取10万场比赛的信息大概用时一个小时多一点,当然网络连接速度对用时有很大影响。
回到之前5000场的样本,我们看一下游戏大厅(lobby_type)和游戏模式(game_mode)的分布, 其中编号的含义参考之前 RDota2 的章节,具体每种模式的解释可以参考 “链接2”:
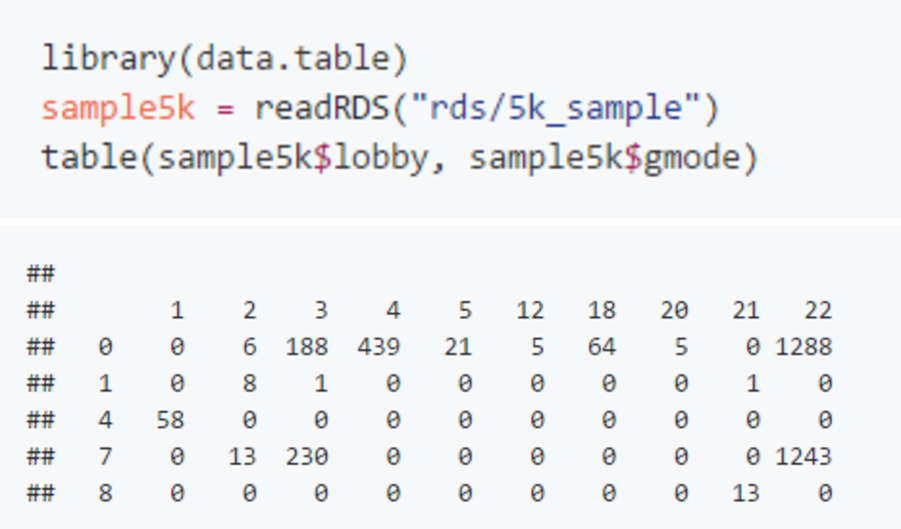
可以看到大多数游戏集中在了公共比赛(lobby_type=0)和排位比赛(lobby_type=7)的排位全阵营模式(game_mode=22)中, 一般全阵营模式(game_mode=1)只出现在与AI的比赛中(lobby_type=4)。 带 Ban/Pick 的队长模式(game_mode=2)只出现在了公共比赛(lobby_type=0),练习赛(lobby_type=1),和排位赛(lobby_type=7)中, 且这8场队长模式练习赛都是联赛(league_id>0)。此外,所有10场练习赛(lobby_type=1)都是联赛(league_id>0)。 然后我决定建模数据只包括,排位赛(lobby_type=22)的全部模式,和练习赛的队长模式(game_mode=2), 因为这些比赛的质量比较有保证,不大会出现消极游戏等情况。 同时要保证每场比赛必须有10位玩家参加。这些筛选条件都已经包含在“dota2_data_query.R”中,可以根据需要自行修改。
为了获得建模数据,我选了5场联赛,它们分别发生在4月30日,4月24日,4月18日,4月12日,和4月6日,然后往后各取了10万场比赛的信息。 不用担心会有重复,因为一天内进行的比赛数远远超过了我一开始的猜测。同时这几天也避开了重大的版本更新。 经过筛选后的 rds 文件我分享在了 “链接3”, 下面的程序可以读取它们,然后我们分别看一下10万场比赛筛选后还剩多少,以及它们发生在多长时间里:
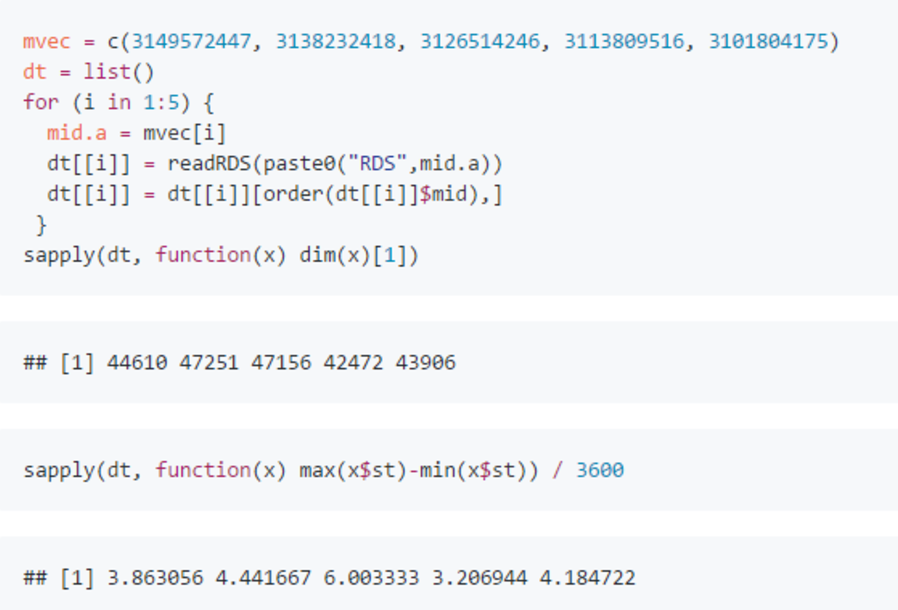
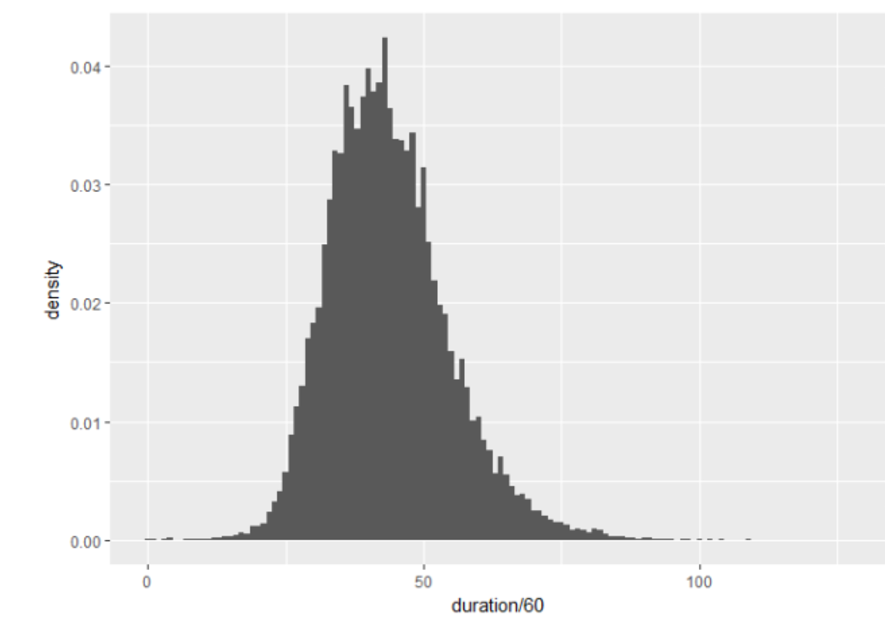
10万条筛选后还剩下4万多,而且发生在了3到6小时内,虽然有极少量被赋予序列号的比赛并没有正式开始, 但保守估计1小时里进行1万场比赛还是有的。 然后画一下游戏时长(分钟)的分布:

数据处理
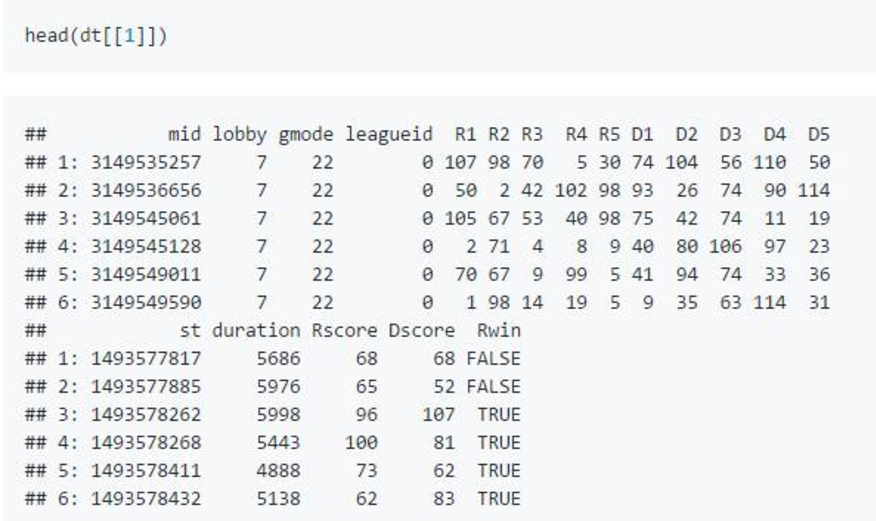
在提取的数据中,天辉的英雄选择放在了“R1”到“R5”,夜魇则是“D1”到“D5”,其中的数字分别代表天辉5名玩家和夜魇5名玩家所选英雄的编号。 但是这里的1到5并不是1到5号位,相反1到5之间并没有次序关系,即使它们之间相互交换内容,也不应该对建模结果造成影响。 所以需要用下面的代码进一步处理数据。在处理之前游戏时长少于15分钟的比赛会被剔除。


可以看到处理之后的数据,我用了另一种方式表达英雄选择:如果天辉方选择了编号为2的英雄,那么“R2”这个位置就会为1,反之为0; 夜魇方的选择则反应在“D2”,“R2”和“D2”不可能同时为1,因为 Dota2 一场比赛里英雄不能重复选择。 显然,每一行(一场比赛)代表英雄选择的0/1加起来一定是10。游戏大厅和游戏模式的信息我也总结了一下,放在 gtype 里。 除此之外我还加入了游戏时长,虽然这个信息在比赛开始之前并不能获知,但 Dota2 里英雄的作用随着游戏时间有着巨大的变化。 不同英雄组成的阵容有明显不同的强势弱势时期,获胜的基本策略之一就是在敌人强势时期避免作战,在己方强势时期结束比赛。 虽然游戏时长与游戏最后胜负紧密相关,而且要等到游戏结束才能得到这一信息,加入这一变量有“用结果预测结果”的嫌疑, 但它并不能单独决定胜负,游戏时长必须与英雄选择相互发生作用从而影响游戏结果。 此外,包含游戏时长这一变量的模型,在给定英雄选择进行预测时可以通过输入若干个假想游戏时长,得到这一阵容的胜率随时间发展而变化的趋势。 之后的模型章节,我会针对包含和不包含游戏时长这一变量分别建模,然后比较结果。
现在建模的脉络就很清晰了,自变量包括天辉英雄选择,夜魇英雄选择,游戏模式和时长,因变量是天辉是否获胜。 对游戏不熟悉的朋友可以想象成,你和对手分别从100多件武器防具里挑5件进行对决,再综合你俩打斗的模式和时长,预测谁会获胜。 我还想过把1条数据变成2条来建模,即自变量为己方阵容,因变量为己方是否获胜。 但如果这样处理数据,英雄阵容之间的克制关系就不能反映出来了,所以作罢。
建模及结果
处理之后的数据 MRD 中 ,我选出第3个,即发生在4月18日的比赛,作为验证数据(holdout),大概占总数据的20%,其余的作为训练数据(train)。

不过在建模之前我还想介绍一个常用的比较二元(binary)分类模型性能的参数 AUC(area-under-curve)。
模型性能参数 AUC
AUC 是评价二元分类问题一个常用的指标,它的取值在0-1之间,数值越大代表模型预测性能越好。那么,这个指标是如何设计的呢?(不感兴趣的客官建议绕过本节)
“天辉是否获胜”是一个典型的二元分类问题,可以用正确率来衡量这类问题的预测结果,但存在一些问题。 比如说100条记录里,真实的“是”(Yes/1)有20条,“否”(No/0)有80条。那么即使我们不做任何预测,直接标记所有100条记录为“否”,也有80%的正确率。 此时真实“是”里被标记正确的比例(true-positive-rate)为0%,真实“否”里被标记错误的比例也为(false-positive-rate)0%。 如果标记所有记录为“是”,那么这两个比例分别为100%和100%。 而一个完美的模型,即正确标记20条“是”记录和80条“否”记录的模型,给出的 true-positive-rate 为100%,false-positive-rate 为0%。
大多数二元分类模型给出的预测量是记录为“是”的概率,一个0和1之间的连续值。 所以需要建模者额外指定一个分界值,预测概率大于这个值的记录会被标记为“是”,反之为“否”。 而 AUC 描述的就是,针对不同的分界值,模型尽早挑出正确的“是”同时避免错误“否”的能力。 AUC(area-under-curve)顾名思义就是曲线下的面积,而这条被称为 ROC 曲线的绘制方法是: 把记录按预测概率从大到小排列,每个预测概率作为分界值时都会有与之对应的 true-positive-rate 和 false-positive-rate, 以 false-positive-rate 作为横轴,true-positive-rate 作为纵轴绘制点,即可得到 ROC 曲线。 比如预测概率从大到小排列为(0.92, 0.87, 0.76, 0.73, 0.68, 0.67, 0.64, 0.55, 0.43, 0.39), 真实值为(1, 1, 1, 1, 0, 0, 1, 0, 0, 0), 相应的 ROC 为下边左图:

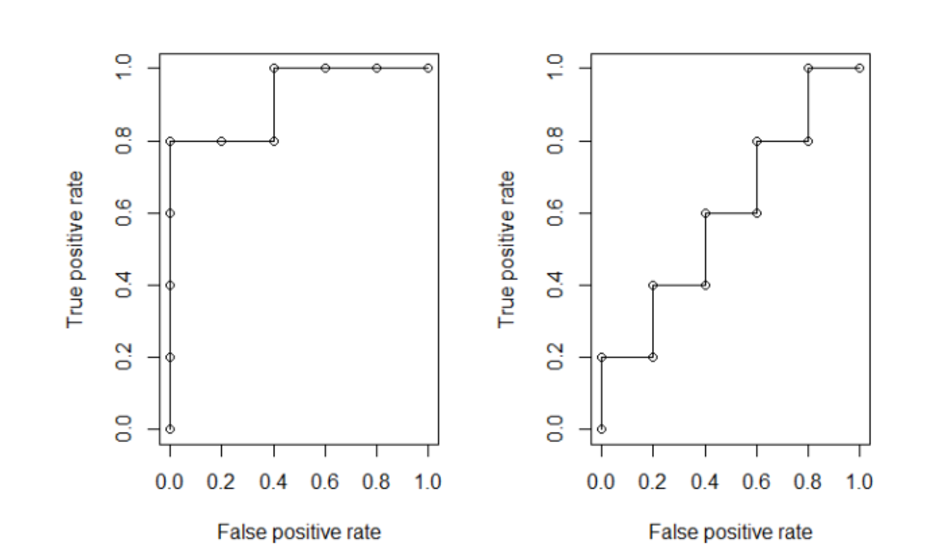
右图是随机预测时产生的 ROC。记录点多了之后,左边 ROC 就变为一条曲线,右边 ROC 就是(0, 0)到(1, 1)的对角线。 如果是完美的模型,那么 ROC 会从(0, 0)直接上升到(1, 0),再向右至(1, 1)。 完美模型 ROC 下的面积就是这个边长为1的正方形的面积,随机模型 ROC 即对角线之下的面积为0.5,所以一般模型 AUC 在0.5和1之间。 简单讲,模型 AUC 在0.8以上即被认为具有相当好的预测性能,0.6到0.8之间意味着数据具有一定的可预测性。 没什么预测能力的模型 AUC 会接近0.5,如果遇到小于0.5的情况,那应该是在处理数据或者建模的时候发生了错误。
naiveBayes 模型
首先我决定用 naiveBayes 模型尝试只用英雄选择信息建模。naiveBayes 的核心是条件概率:首先计算训练数据里天辉获胜的总体概率, 然后计算天辉获胜时各英雄的分布情况,再由条件概率得到选了某几个英雄时天辉获胜的概率。 模型特点是简单,不用调试任何参数,不容易过拟合,计算效率高。它在文本分析/情感分析方面被证实效果还是不错的: Dota2 英雄的数量只有124,1篇文章里面独特的字/词数可就多了,需要一个高效的算法处理这些信息。 下面的代码就完成了 naiveBayes 模型拟合,然后分别预测 train 和 holdout 并计算 AUC。
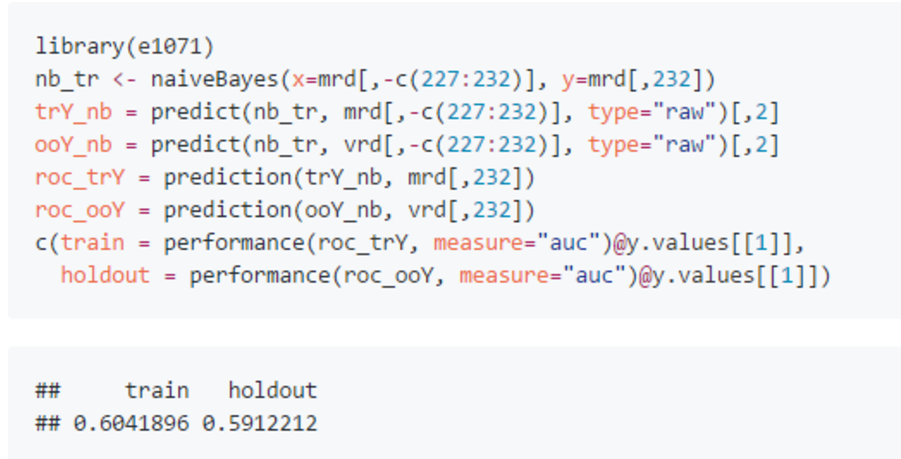
可以看到两个 AUC 非常接近,说明没有发生过拟合。 而且 AUC 接近0.6,表明英雄选择对比赛胜负还是有一定影响的。 这里还可以用关联规则分析(association-rule-learning),找出经常同时出现在一场比赛里的英雄组合, 他们出现在同一队则是相辅相成的关系,互为对手则是克制的关系。 把这样的英雄组合加入自变量,还可以进一步提高模型预测效果。
gradient-boosting-machine 模型
然后我决定用 gradient-boosting-machine(GBM)模型建模。 GBM 的核心是树状模型(tree-based model),它与 random forest 最大的不同就在于, random forest 里每一个树都是相对独立的,而 GBM 的单个树状模型是基于上一个树的拟合结果而建立的,是一个渐进过程。 在一个分类(classification)GBM 迭代过程中,当前的树模型会集中关注造成过往树模型分类错误的数据,目标就是更进一步提高模型预测的准确度。 这就使得 GBM 往往可以把衡量模型预测能力的一些指标推到一个非常高的程度,让它在很多建模比赛里拔得头筹。 GBM 最大的问题是很容易发生过度拟合(over-fitting),所以需要反复调试拟合参数。
建模用到 R package xgboost,是现在最好用的拟合 GBM 软件包,统计之都前辈何通是作者之一。 xgboost 在 R/Python/Java 都有各自版本,特点是提供了非常多可供调试的参数,拟合效率高。 首先我考虑不包括游戏时长,只用英雄选择和游戏模式作为自变量建模。 模型参数通过交叉验证调整得到,具体的过程就不介绍了,这里只给出调整后的参数, 此时树模型的特点是复杂度低(max.depth=2),数量大(nrounds=256):


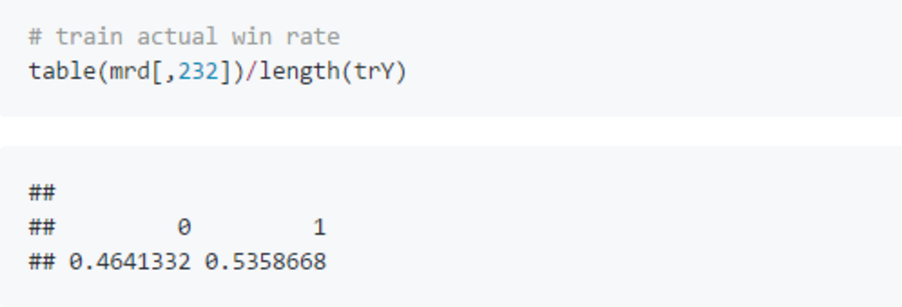
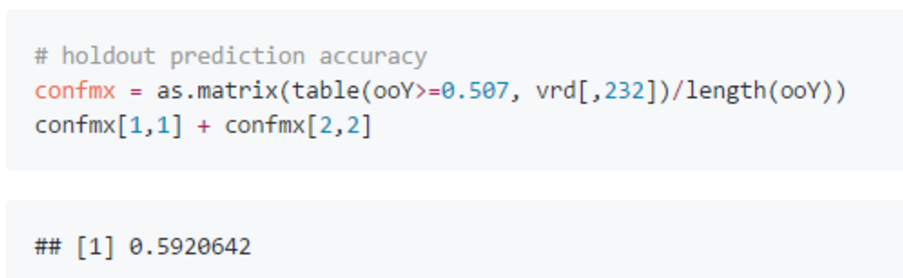
可以看到 train AUC 明显高于 holdout AUC,说明存在一些过拟合。 但其实用 GBM 建模或多或少都会存在一些过拟合,只要拟合迭代时 holdout error 没有先下降然后开始明显上升,那都是可以接受的。 同时 holdout AUC 达到了0.622,比之前 naiveBayes 模型有明显提升。 因为模型给出的预测是天辉获胜的概率,所以需要指定一个分界值,决定哪些比赛可以预测为天辉胜利。 这批数据里天辉获胜几率(53.6%)略高于夜魇(46.4%),所以0.5作为分解值并不是最合适的。 我们可以在 train 预测值上调整分界值,目标是最大化 train 上的预测正确率。 调整后的分界值为0.507,此时 train 上正确率是60.7%,holdout 上正确率是59.2%。
然后还可以提取模型变量的重要度排行。下面给出排行前列的几个变量。 第一列是变量,第二列 Gain 是指该变量给模型带来正确率提升的占比, Cover 和 Frequency 分别指在所有树结构模型中,由该变量区分的数据占比,和变量使用次数占比。 可以看到代表同一个英雄出现在天辉(例如R67)或者夜魇(例如D67)的变量,同时出现在重要度排行的前列, 说明这些英雄对模型预测能力的提高作用是稳定的,不管他们出现在天辉方还是夜魇方。
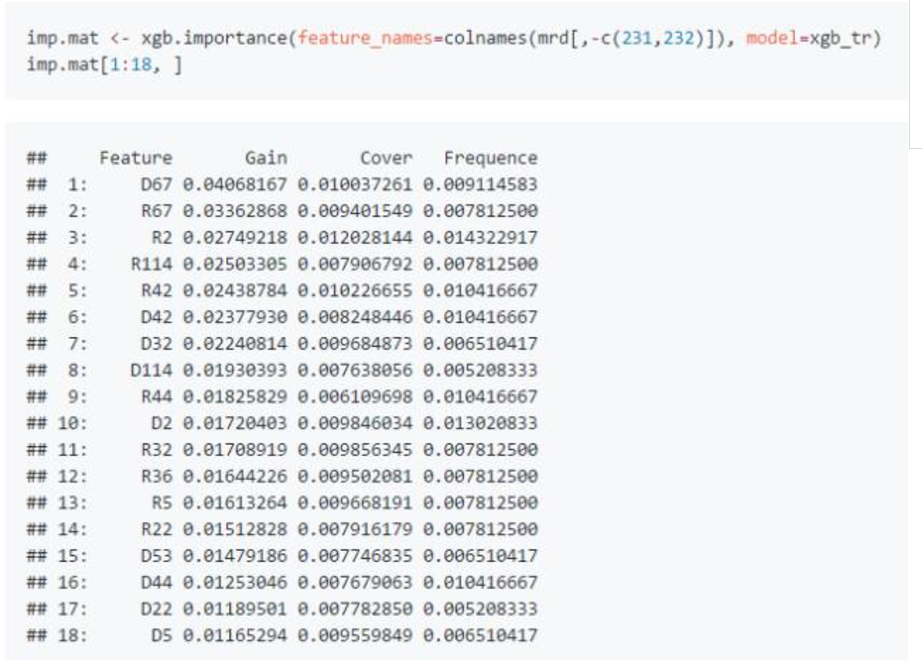
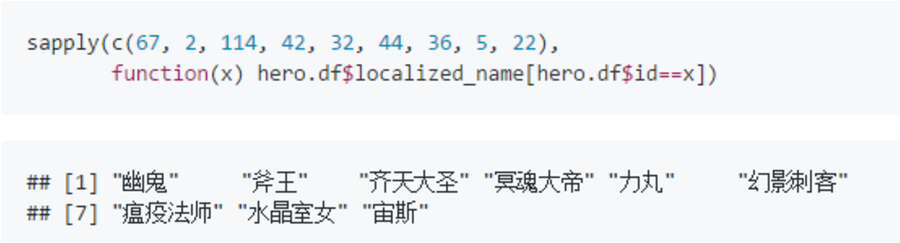
接着让我们看一下这些英雄都是谁吧。幽鬼,斧王,冥魂大帝,力丸,幻影刺客,瘟疫法师,水晶室女,宙斯, 在 Dotabuff网站“链接4”本月英雄胜率排行中均名列前茅。 新出的英雄齐天大圣,虽然被选中的几率挺高,但是胜率排名垫底。 需要注意的是,变量重要度排行针对的是变量在模型中的预测能力, 它与单独某个英雄对比赛胜负是正面还是负面作用没有直接关系,因为树模型中的变量都是互相影响着发挥作用的。 例如宙斯和力丸搭配对赢得比赛有正面作用,但如果队伍中同时出现后期才强势的英雄如幽鬼和幻影刺客那基本就别想赢了。 不过胜率还是可以说明一些问题的,比如说天辉夜魇平均胜率分别为53.6%和46.4%, 选了幽鬼(编号67)之后胜率有明显提升达到62.3%和55.7%,齐天大圣(编号114)的胜率则只有46.2%和39.6%。
单独某个英雄对比赛胜负的正负影响可以由回归模型得到:拟合的变量系数正负等同于作用正负,系数绝对值描述了作用大小。 这也是参数模型(parametric model)的优势,在回答商业问题时可以给出定量的解释。 但回归模型的限制也很明显,它需要我们指定模型考虑哪些变量相互作用(interaction),不然模型只会计算每个变量的单独作用。 关于回归模型的拟合,可以参考我之前的文章,“链接5”。
然后游戏时长被加入到自变量中,重新建模。这里除了 max.depth 和 nrounds 之外,其他的参数与之前相同:

加入游戏时长这个变量后,模型 AUC 又有了明显提升,与数据处理章节预想的一样。 同样的,分界值定为0.498,此时 train 上正确率是64.5%,holdout 上正确率是61.4%。
下面是变量重要度排行。 可以看到,游戏时长现在是以绝对优势处于排行的首位,但它肯定是与英雄选择相互发生作用(interaction)来提高模型预测能力的。 然后同一英雄出现在两边但是都排行前列的情况依旧很明显,同时大多数之前模型里排名靠前的英雄依旧表现出色:

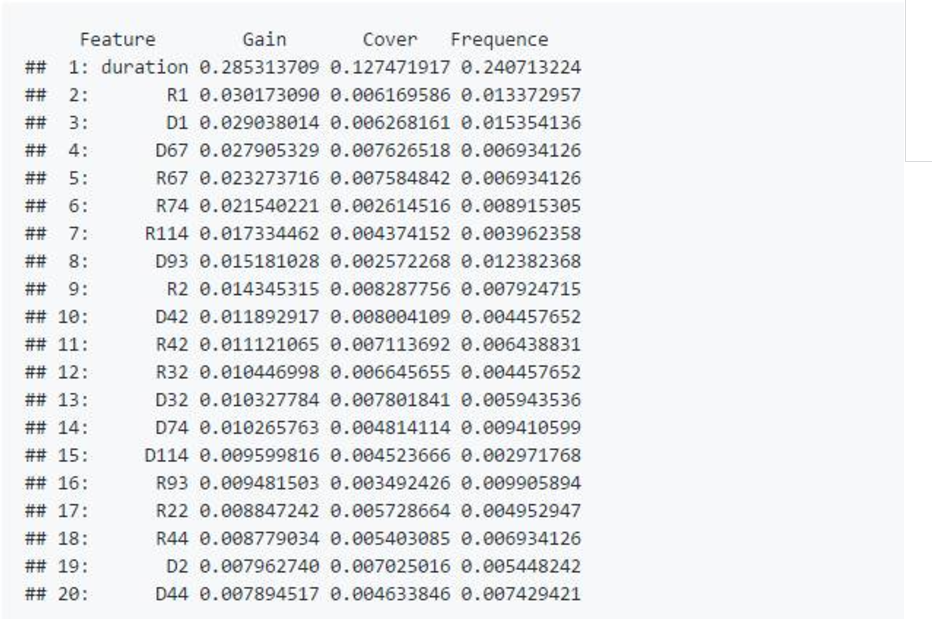
这里敌法师,祈求者,斯拉克,跃升到变量重要度排行的前列,他们都是比较典型胜率随游戏时长增加而显著提高的英雄。 比赛里常常可以看到30分钟后,敌法师对死命保护他的4个队友说:我已起飞,你们可以去一边开心麻将了。 而且敢选这几个英雄的玩家,一般对自己的水平还是有点自信的。

还是祈求者最上相
模型总结
GBM 模型0.66的 AUC,和略高于61%的正确率还是让人满意的。 因为除了英雄选择,影响一场比赛胜负的因素实在太多了,有的甚至发生在游戏之外。 如果选了某几个英雄就有很大几率赢得比赛,那么只能说这个游戏在英雄设计上是有巨大问题的,游戏也会因缺少跌宕起伏而乏味。 之前看到过一篇文章比较了 Dota2 和英雄联盟的不同,里面提到了 Dota2 地图从相对位移来说明显大于 lol,更大地图意味着更多变数。 同时 Dota2 更复杂的视野机制,物品,野怪等等,都给比赛增加了更多的不确定因素。 而韩国人在英雄联盟独领风骚的诀窍之一就在于对游戏进程的精准把握,什么时间该干什么都精确到秒,但这些都必须基于一个较稳定的系统。 面对 Dota2,这一套就不那么好使了,所以韩国战队在 Dota2 比赛里一直被各支中国队伍花式吊打。
但是话又说回来,游戏越复杂,推广起来就越不容易。 然后除了上述模型,我还试了 python 的深度学习 package Keras,效果并不理想,我认为主要原因有两点: 第一,数据不管是数量(行)还是维度(列)对深度学习来说都有些不够; 第二点当然是因为我调试和迭代得还不够,Google 经常花几个月时间训练它的神经网络,这对个人来说成本过高。 另外,尽管 GBM 模型可以回答哪些变量对模型预测能力贡献最大,但是由于其正负影响无法量化,缺乏变量作用的定量解释。 所以有兴趣的同学可以尝试用相同数据建一个回归模型,同时考虑关联规则分析(association-rule-learning)找出重要的变量交互作用(interaction), 比如两个或者多个英雄之间的相生相克关系,加入模型。 除此之外,还可以考虑当能获取的信息时间粒度不同时,对比赛胜负的预测会有什么影响,或者不局限于比赛胜负,考虑别的预测目标。 这些都是些比较有趣的思考方向,等待大家未来的探索。
在我写这篇文章的时候,统计之都正在清华举办第十届中国 R 语言会议。 通过统计之都,我认识了很多优秀的朋友,在这里也获益良多。所以祝统计之都越办越好,也期待更多人的加入!
作者简介:侯澄钧,俄亥俄州立大学运筹学博士, 目前在美国从事财产事故险(Property & Casualty)领域的保险产品开发,涉及数据分析、统计建模和产品算法优化等方面的工作。
链接参考:
链接一:
https://github.com/chengjunhou/Tutorial/blob/master/rdota2/dota2_data_query.R
链接二:
http://dota2.tgbus.com/zt/system/moshi.shtml
链接三:
https://github.com/chengjunhou/Tutorial/tree/master/rdota2
链接四:
https://www.dotabuff.com/heroes/meta
链接五:
http://cos.name/2016/10/data-mining-1-lasso/