更优阅读体验爬虫三步走(二)解析源码
=====================================================================
上一期爬虫三步走(一)获取源码 讲了如何获取网页源码的方法,这一期说一说怎么从其中获得我们需要的和数据。
解析网页的方法很多,最常见的就是BeautifulSoup和正则了,其他的像xpath、PyQuery等等,其中我觉得最好用的就是xpath了,xpath真的超级简单好用,学了之后再也不想取用美丽汤了。下面介绍xpath的使用方法。

首先需要安装lxml,windows下安装lxml是个大坑,知乎上有人给出了解决方法Python LXML模块死活安装不了怎么办?
详细的用法可以参考@爬虫 所写 爬虫入门到精通-网页的解析(xpath)
在这里我们尝试使用xpath来迅速获取数据。
例如想要获熊猫直播虎牙直播下主播的ID
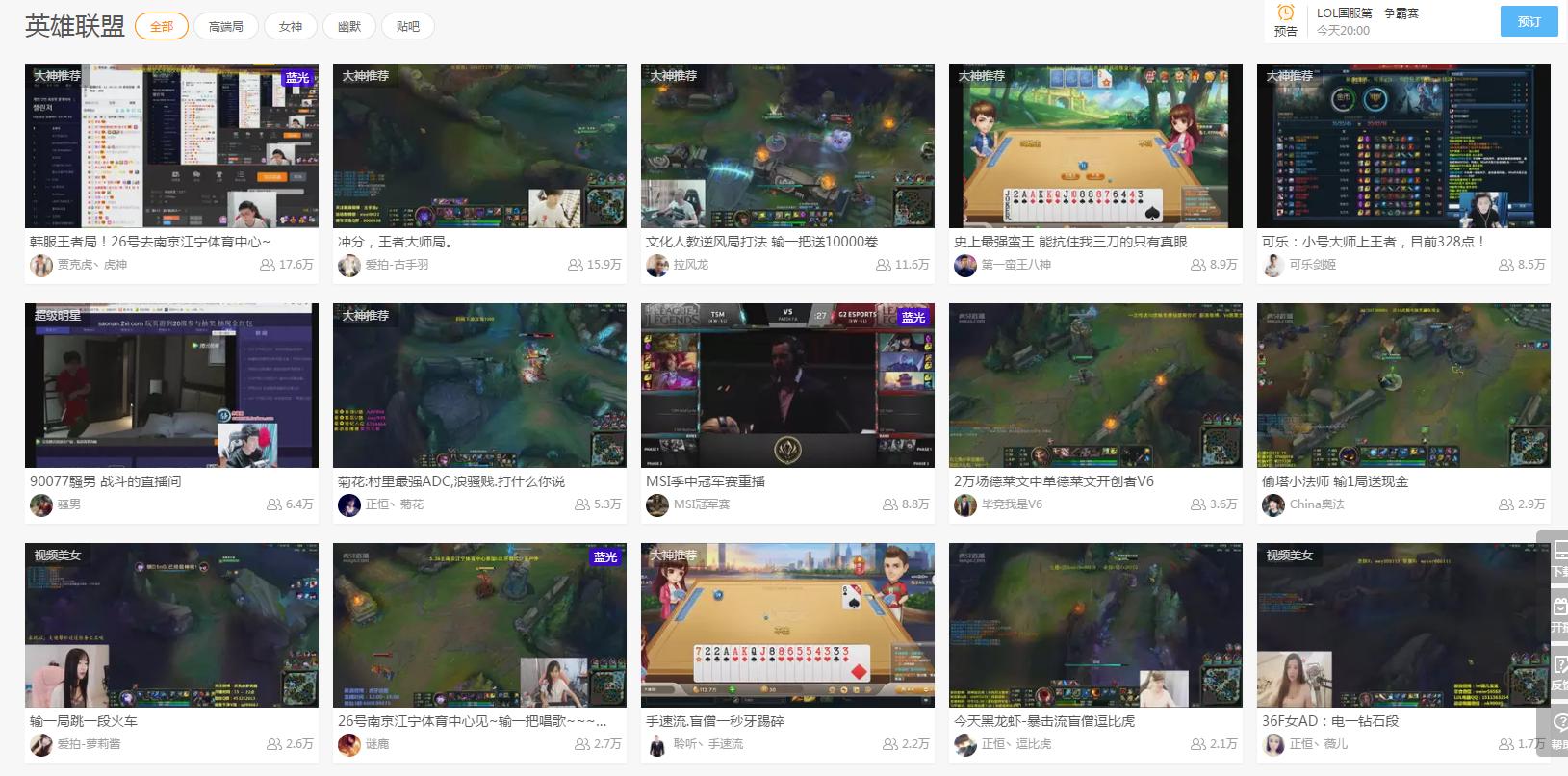
import requests
from lxml import etree
url = 'http://www.huya.com/g/lol'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
res = requests.get(url,headers=headers).text
s = etree.HTML(res)
print(s.xpath('//i[@class="nick"]/text()'))
输出:

下面一步步讲解为什么这样做。
import requests
from lxml import etree
首先是导入模块,requests很常见,但是xpath需要from lxml import etree,你肯点想问为什么这样写,回答是“我也不知道”,就像是约定俗成的东西一样。
url = 'http://www.huya.com/g/lol'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
res = requests.get(url,headers=headers).text
这三步就是平常获取源码的过程,很简单。
s = etree.HTML(res)
给一个html,返回xml结构,为什么这样写??答案和上面一样。最重要的就是下面的这一步:
s.xpath('//i[@class="nick"]/text()')
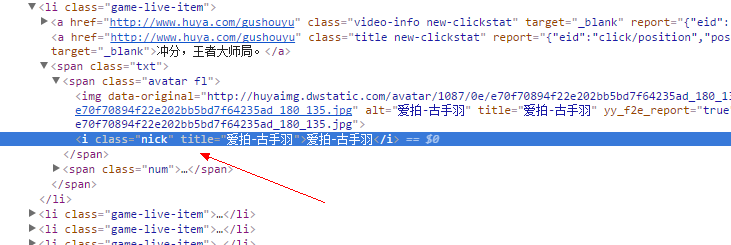
按下F12看到“爱拍-古手羽”在i标签下,接着我们右键打开“查看网页源代码”,搜索“爱拍-古手羽”

确实找到了“爱拍-古手羽”就在i标签下,那我们就把他提出来吧!
s.xpath('//i[@class="nick"]/text()')
这个段代码意思是,找到class为“nick”的i标签,返回其中的文本信息,当然你也可以返回i标签中的title,写法如下:
s.xpath('//i[@class="nick"]/@title')
text()返回的是文本信息,@title则是标签里面的具体属性的值,例如我想知道观众人数
import requests
from lxml import etree
url = 'http://www.huya.com/g/lol'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
res = requests.get(url,headers=headers).text
s = etree.HTML(res)
print(s.xpath('//i[@class="js-num"]/text()'))
只需在原来基础上修改一个属性,i标签class为“js-num”里面的值
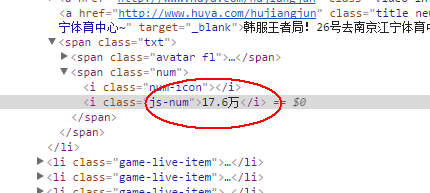
print(s.xpath('//i[@class="js-num"]/text()'))
返回结果是:
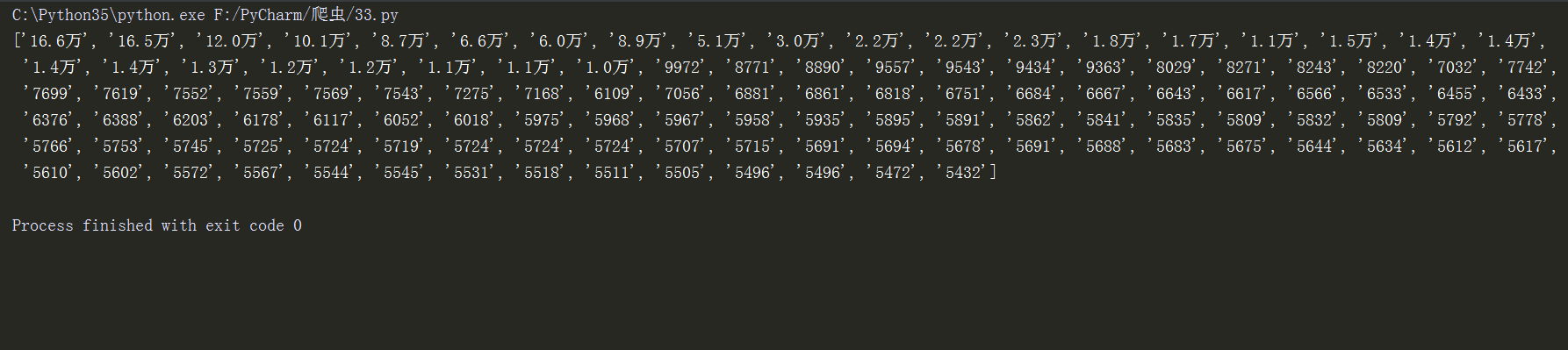
说明:在运行代码中,发现虎牙反爬虫做得挺好的,瞬间就识别爬虫身份并封了IP,所以我换了IP去访问,至于如何设置代理,在我的上一篇文章中有说到,去看看吧。
在实际操作中,你可能会遇到更加复杂的情况,所以一定记得去看看详细的教程。爬虫入门到精通-网页的解析(xpath)
小广告:喜欢爬虫、数据的可以关注一下我的微信公众号(zhangslob),多多交流。

