上一篇文章曾经提过,Tensorflow 模型的一个共性就是需要定义 Placeholder 以固定住静态的 Graph、避免由于不断重复向 Graph 中写入相同的运算规则而使速度越来越慢。为此,我们完全可以定义出一个基类来处理 Tensorflow 模型的共性。首先看结构:
# 继承普通的分类器基类 ClassifierBase 以复用代码
class TFClassifierBase(ClassifierBase):
"""
初始化结构
self._tfx、self._tfy:模型输入数据和输入标签对应的 Placeholder
self._y_pred_raw、self._y_pred:模型输出对应的 Tensor
self._sess:Tensorflow 中的 Session
"""
def __init__(self, **kwargs):
super(TFClassifierBase, self).__init__(**kwargs)
self._tfx = self._tfy = None
self._y_pred_raw = self._y_pred = None
self._sess = tf.Session()
注意到我们定义了两种模型输出:self._y_pred_raw 和 self._y_pred,它们的区别在于(假设有 N 个样本,K 个类别):
- self._y_pred_raw:此为模型的“原始输出”。如果模型是个概率模型的话,它就记录着每个样本属于每个类别的概率。所以它是 N x k 的矩阵
- self._y_pred:此为模型的“类别输出”,它会输出每个样本所属的类别。所以它是 N x 1 的向量
然后是模型的性能判定标准,这里以最常用的准确率为例:
@staticmethod
def acc(y, y_pred, weights=None):
y_arg, y_pred_arg = tf.argmax(y, axis=1), tf.argmax(y_pred, axis=1)
same = tf.cast(tf.equal(y_arg, y_pred_arg), tf.float32)
if weights is not None:
same *= weights
return tf.reduce_mean(same)
最后是分 Batch 训练这么个思想。在上一篇文章中,我们每次训练时是将所有样本全都扔给模型的,这样如果样本量非常大的话,我们的内存肯定就遭不住。为此,我们可以把样本切分成一个个的小 Batch、并逐个将它们喂给模型。相应的实现也比较直观:
def batch_training(self, x, y, batch_size, train_repeat, *args):
# 这里规定 args 参数的前两个需要是:
# + 模型的“损失” —— loss
# + 模型的“训练步骤” —— train_step
loss, train_step, *args = args
epoch_cost = 0
for i in range(train_repeat):
if train_repeat != 1:
# 利用 Numpy 相应方法随机提取 Batch
batch = np.random.choice(len(x), batch_size)
x_batch, y_batch = x[batch], y[batch]
else:
x_batch, y_batch = x, y
# 将一个 Batch 的数据喂给相应 Placeholder 以获得损失并完成训练
epoch_cost += self._sess.run([loss, train_step], {
self._tfx: x_batch, self._tfy: y_batch
})[0]
return epoch_cost / train_repeat
以上就是一个 Tensorflow 模型基类的所有实现了,现在我们来看看如何把它应用到 LinearSVM 上(只写出了核心步骤,因为大多数东西上一篇文章都说过了):
self._w = tf.Variable(np.zeros([x.shape[1], 1]), dtype=tf.float32, name="w")
self._b = tf.Variable(0., dtype=tf.float32, name="b")
self._tfx = tf.placeholder(tf.float32, [None, x.shape[1]])
self._tfy = tf.placeholder(tf.float32, [None, 1])
self._y_pred_raw = tf.matmul(self._tfx, self._w) + self._b
self._y_pred = tf.sign(self._y_pred_raw)
loss = tf.reduce_sum(
tf.nn.relu(1 - self._tfy * self._y_pred_raw)
) + c * tf.nn.l2_loss(self._w)
train_step = tf.train.AdamOptimizer(learning_rate=lr).minimize(loss)
self._sess.run(tf.global_variables_initializer())
# 通过数据量和 Batch 大小来定出每个 Epoch 中进行多少次 Batch 训练
train_len = len(x)
batch_size = min(batch_size, train_len)
do_random_batch = train_len > batch_size
train_repeat = 1 if not do_random_batch else int(train_len / batch_size) + 1
for i in range(epoch):
# 调用刚定义的方法来完成 Batch 训练
l = self.batch_training(x, y, batch_size, train_repeat, loss, train_step)
# 若模型损失小于阈值、则结束训练
if l < tol:
break
调用的方法也是比较直观的:
svm = LinearSVM()
svm.fit(x, y, kernel="poly", p=12) # 多项式核,次数为 12
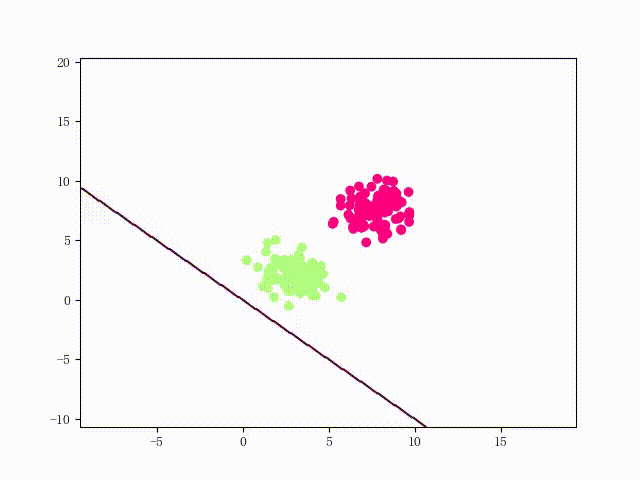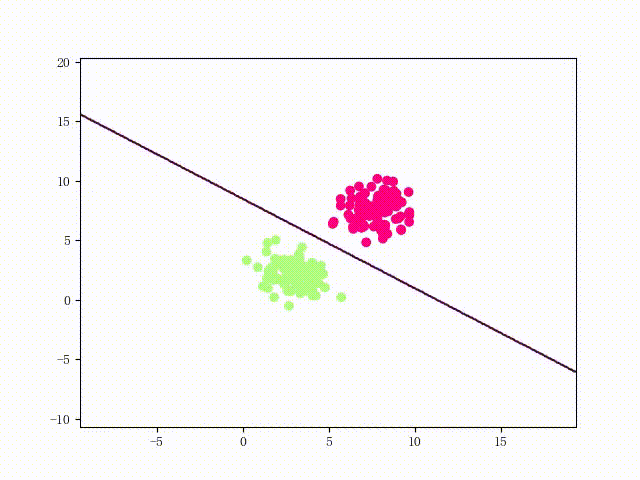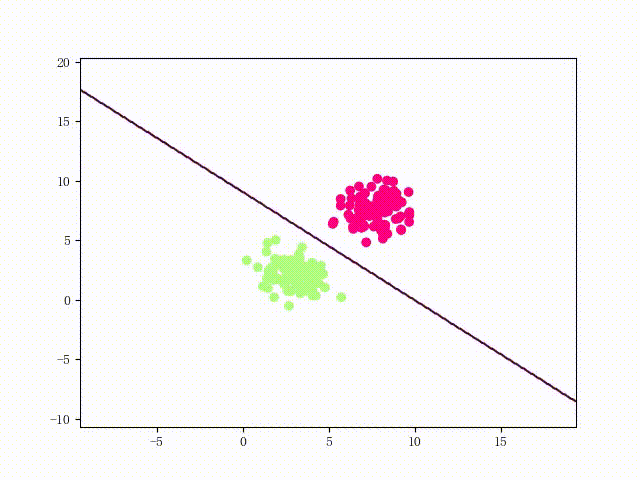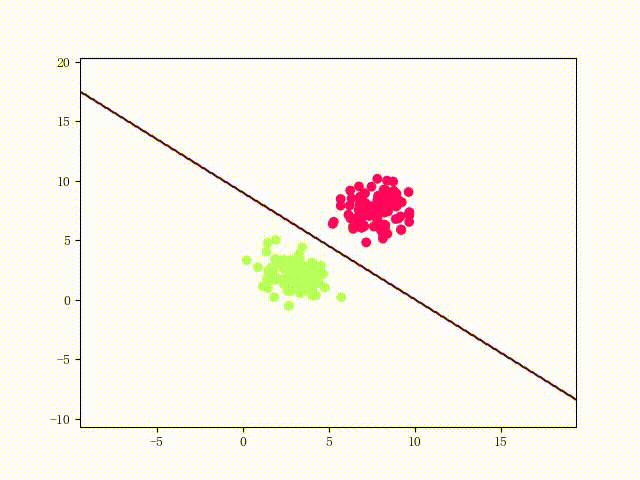
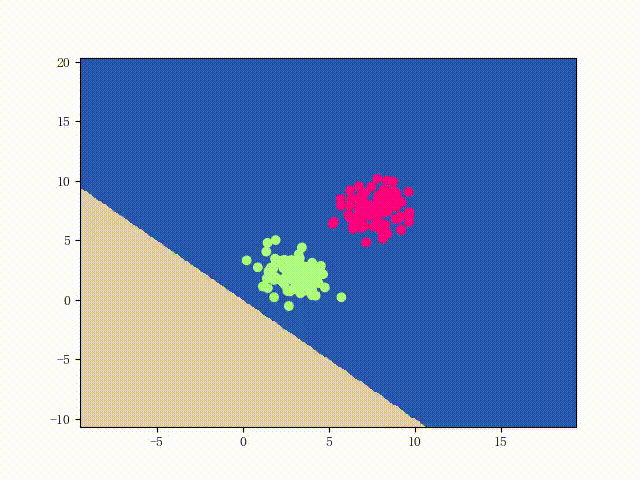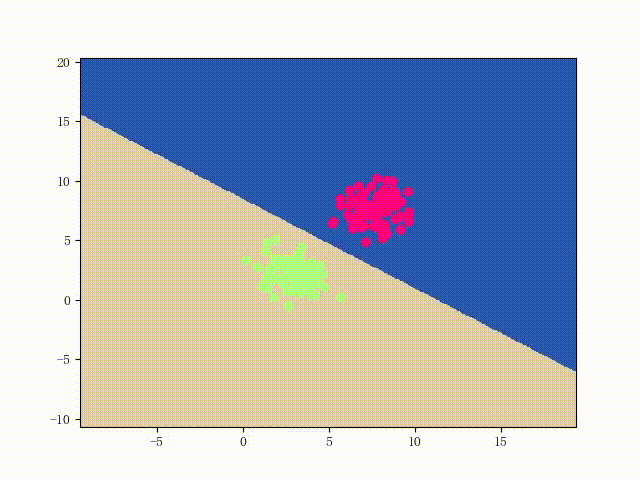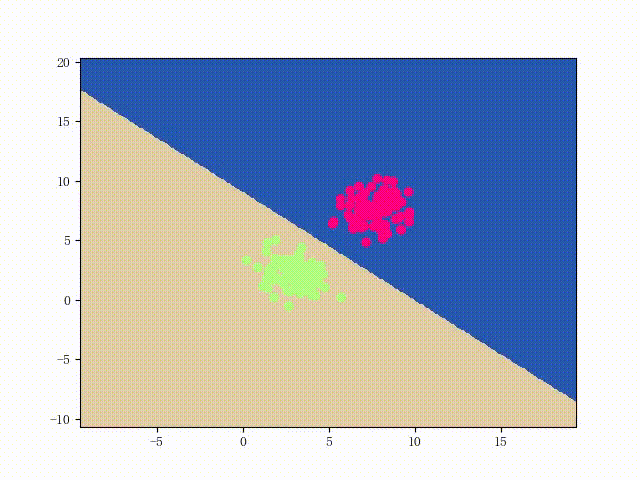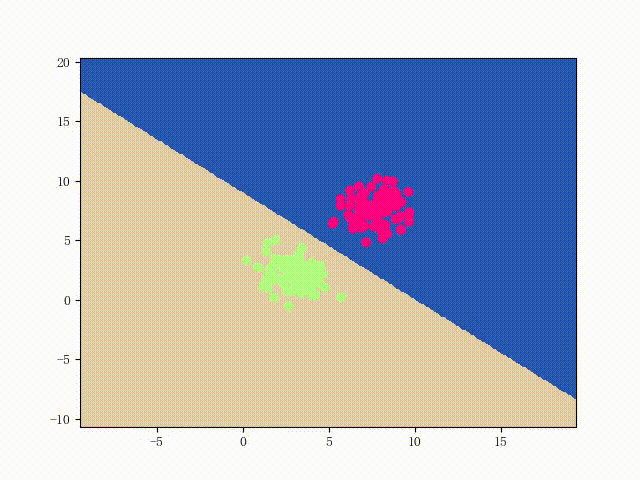
可以用两个简单的可视化来直观感受一下该 LinearSVM 的性能: