本文的两大贡献:
- 给出了爬取经纬度数据的方法。
- 给出了搜房网(房天下)爬取的可实现解决方案。爬该网站的困难有二:其网页是压缩过的以及网站只给出100页的内容。
本系列文章介绍了爬取链家和搜房网(房天下)数据的方法。
房产中介网站爬虫实战(Python BS4+多线程)(一)
房产中介网站爬虫实战(Python BS4+多线程)(二)
0.废话
房地产市场向来是大数据分析的“重灾区”,它的数据易获得,且对每个人都有切肤之痛,所以无论是数据分析的菜鸟还是老鸟都纷纷投入其中,渴望着用大数据来改变自己的下半辈子生活。
鉴于本人没有买房需求,就只爬租房的数据了。
1.链家
1.1 爬取思路
链家网有两种查看房屋列表的方式:一是列表,二是地图,如下图所示。前者只显示100页,每页20条,后者以我的技术爬不下来。然而前者的问题被我解决,因此通过前者的途径进行爬取。
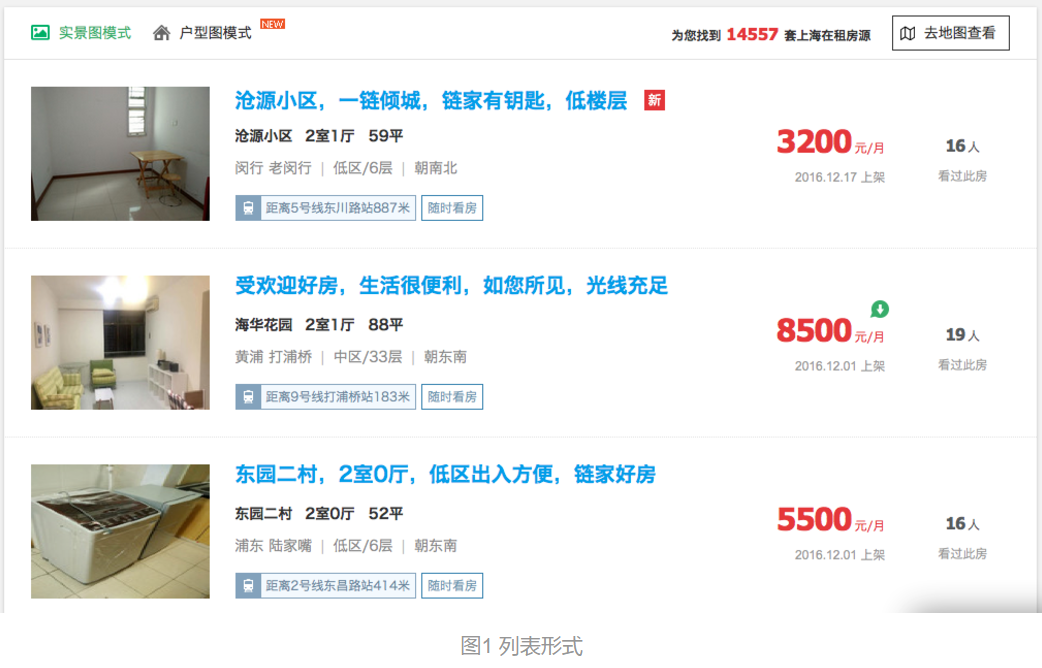
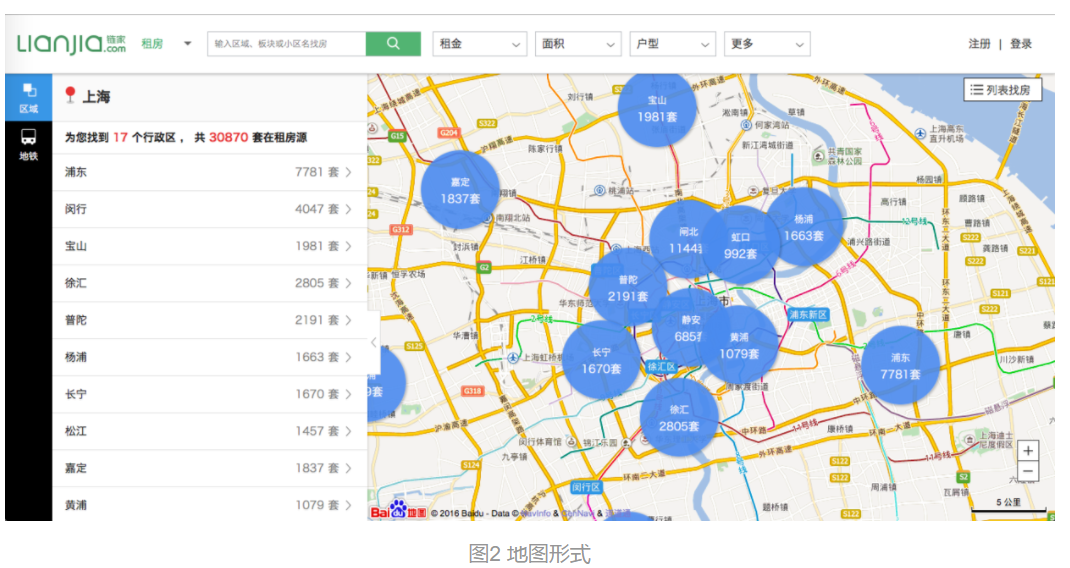
链家网在搜房的时候是二层结构,第一层是列表,可以爬取到每一个房子的唯一链接;第二层是访问这个链接,以爬取各房子的详细信息。
所以我采取的策略是先把所有的链接都爬下来,再依次去爬获取房屋信息。
1.2 解决只显示100页问题
如图,明明有12000+条的房源,却只显示2000条(100页×20条)。
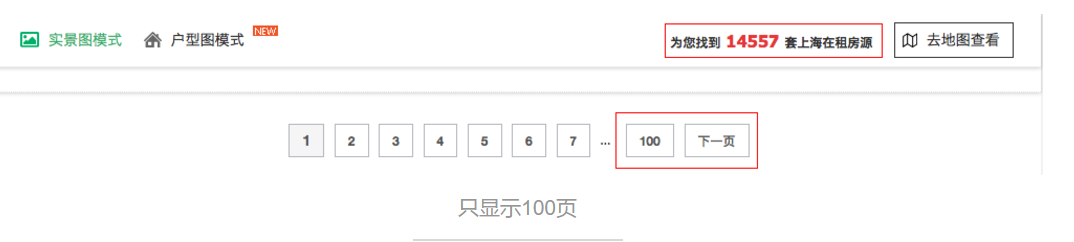
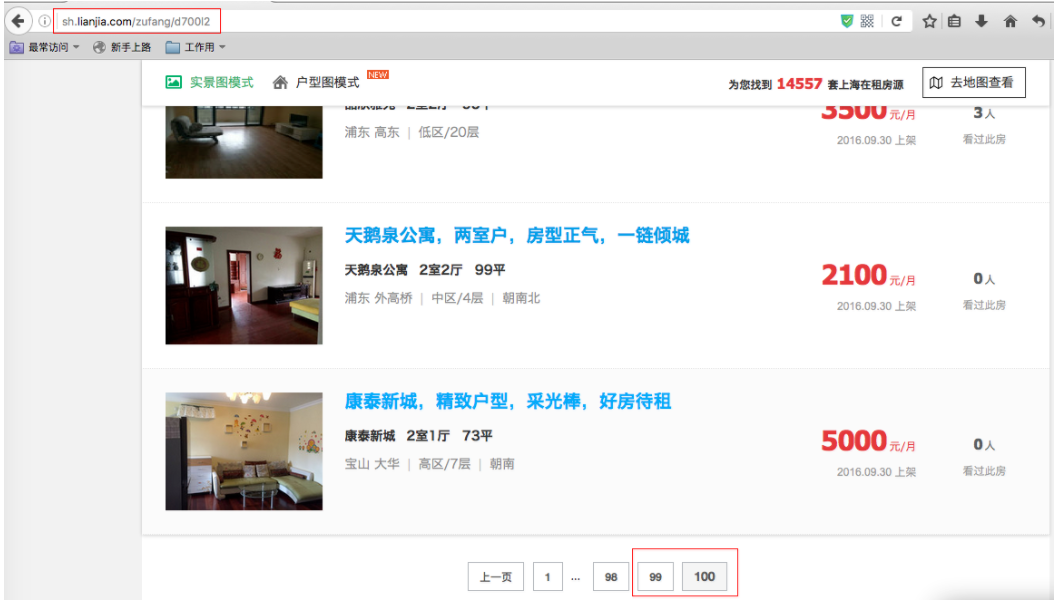
实际页数已经到700页,然而页尾的页数仍然显示100
由此得到判断一共页码数的计算公式:总房源数除以20后向上取整,例如上图显示14557套房源,则总页数是728。
1.3 第一步:获取链接
import urllib
from bs4 import BeautifulSoup
import inspect
from multiprocessing.dummy import Pool as ThreadPool
import math
import datetime
starturl="http://sh.lianjia.com/zufang/d1l2"
req = urllib.request.Request(starturl)
content = urllib.request.urlopen(req).read()
soup = BeautifulSoup(content, "lxml")
page = soup.find_all('a')
pagenum1 = page[-2].get_text()
totalpage = int(math.ceil(float(soup.h2.span.get_text())/20))
first_urlset = []
for i in range(1, totalpage + 1):
url = "http://sh.lianjia.com/zufang/d" + str(i) + "l2"
first_urlset.append(url)
def read_url(url):
req = urllib2.Request(url)
fails = 0
while fails < 5:
try:
content = urllib.request.urlopen(req, timeout=20).read()
break
except:
fails += 1
print inspect.stack()[1][3] + ' occused error'
soup = BeautifulSoup(content, "lxml")
return soup
def get_houselinks(url):
soup = read_url(url)
firstlinkset = soup.find_all('h2')
firstlinkset = firstlinkset[1:]
houselink = ['http://sh.lianjia.com' + i.a['href'] for i in firstlinkset]
return houselink
pool = ThreadPool(4)
finalset = pool.map(get_houselinks, first_urlset)
pool.close()
pool.join()
today = datetime.date.today().strftime("%Y%m%d")
f = open("%s" %'lj_links' + today + '.txt',"w")
f.write(str(finalset))
f.close()
注1:在首页获得房源数量,可以算出总共的有效页数,计算方法如上文,math.ceil()即为向上取整。
注2:如上文,获得所有页数。
注3:封装的一个BeautifulSoup的解析小函数,为了应对由于网络错误带来的读取网页失败。inspect.stack()[1][3]用来获取当前运行的类名/函数名,从而可以知道是这里发生了错误。
注4:因为所有的链接都在h2标签的子标签.a里,['href']是为了获得链接,只要是链接都是以href表示的。
注5:拼接成完整的链接。
注6:关于多线程的说明,参见我另一篇文章中的描述《用Python爬取妹子图——基于BS4+多线程的处理》。这里需要说明的是:pool.map输出的是列表类型,是两个列表的嵌套,最外层的列表的长度是len(first_urlset),代表有多少页,此列表中的每个元素是一个列表,代表每一页中的房源链接,该列表长度为len(houselink)。
注7:记录下每一次链接更新的结果。
1.4 第二步:获取信息
这一步的结果是生成基本信息表。
import os
import inspect
import urllib
from bs4 import BeautifulSoup
import re
from sqlalchemy import create_engine
import sqlite3
import pandas as pd
from multiprocessing.dummy import Pool as ThreadPool
from itertools import chain
import glob
txtlist = glob.glob(os.path.join("", 'lj_links*.txt'))
temp1 = {}
for i in txtlist:
temp1[i] = os.path.getmtime(i)
filename = sorted(temp1.items(),key=lambda item:item[1],reverse = True)[0][0]
f = open(filename,"r")
finalset = eval(f.read())
fullset = list(chain(*finalset))
alreadylist = []
conn=sqlite3.connect('%s' %'SHRENT.db')
cur=conn.cursor()
query = 'select URL from basic_information'
alreadylist = list(pd.read_sql(query, conn)['URL'])
fullset = list(set(fullset).union(set(alreadylist)).difference(set(alreadylist)))
errorlist = []
engine = create_engine('sqlite:///%s' %'SHRENT.db', echo = False)
def read_url(url):
req = urllib.request.Request(url)
fails = 0
while fails < 5:
try:
content = urllib.request.urlopen(req, timeout=20).read()
break
except:
fails += 1
print(inspect.stack()[1][3] + ' occused error')
raise
soup = BeautifulSoup(content, "lxml")
return soup
def save(urlset):
title = []
price = []
room = []
area = []
floor1 = []
floor2 = []
direct = []
district1 = []
district2 = []
onsaledate = []
xiaoqu = []
address = []
number = []
longitude = []
latitude = []
URL = []
try:
soup = read_url(urlset)
title.append(soup.find('h1', class_ = 'main').get_text())
price1 = soup.find('div', class_ = 'price').get_text()
price.append(int(re.findall(r'\d+', price1)[0]))
room.append(soup.find('div', class_ = 'room').get_text().strip())
area1 = soup.find('div', class_ = 'area').get_text()
area.append(int(re.findall(r'\d+', area1)[0]))
floor_ori = soup.find_all('td')[1].get_text()
floor1.append(floor_ori.split("/")[0])
floor2.append(int(re.findall(r'\d+', floor_ori.split("/")[1])[0]))
direct.append(soup.find_all('td')[3].get_text().strip())
district_ori = soup.find_all('td')[5].get_text()
district1.append(district_ori.split(" ")[0])
district2.append(district_ori.split(" ")[1])
onsaledate.append(soup.find_all('td')[7].get_text())
xiaoqu.append(soup.p.get_text().strip())
address.append(soup.find_all('p')[1].get_text().strip())
number.append(soup.find('span', class_ = 'houseNum').get_text()[5:])
temp1 = str(soup.find_all('div', class_='around js_content')[0])
temp2 = re.findall(r'\d+\.\d+',temp1)
longitude.append(temp2[1])
latitude.append(temp2[0])
URL.append(urlset)
except:
errorlist.append(urlset)
df_dic = {'title':title, 'price':price, 'room':room, 'area':area, 'floor1':floor1, 'floor2':floor2, \
'direct':direct, 'district1':district1, 'district2':district2, 'onsaledate':pd.to_datetime(onsaledate), \
'xiaoqu': xiaoqu, 'address': address, 'number':number, 'longitude':longitude, 'latitude':latitude, 'URL':URL, \
'source':"链家"}
try:
dataset = pd.DataFrame(df_dic, index = number)
dataset = dataset.drop(['number'], axis = 1)
except:
dataset = pd.DataFrame()
dataset.to_sql('basic_information', engine, if_exists = 'append')
pool = ThreadPool(4)
pool.map(save, fullset)
pool.close()
pool.join()
f = open('Notsaved.txt', 'w')
print(errorlist, file = f)
f.close()
注1:这是防止数据获取中断时,再次获取数据不会重复的机制。fullset是全部的待更新信息的链接,alreadylist是已经更新信息成功的链接。
1.5 第三步:更新价格
from sqlalchemy import create_engine
import sqlite3
import pandas as pd
from multiprocessing.dummy import Pool as ThreadPool
import datetime
import re
import urllib
from bs4 import BeautifulSoup
import inspect
today = datetime.date.today().strftime("%Y%m%d")
conn=sqlite3.connect('SHRENT.db')
engine = create_engine('sqlite:///%s' %'SHRENT.db', echo = False)
query1 = "select URL from basic_information"
urlist_basic = list(pd.read_sql(query1, conn)['URL'])
query2 = 'select * from price_temp'
try:
alreadylist = list(pd.read_sql(query2, conn)['URL'])
except:
alreadylist = []
urlist2 = list(set(urlist_basic).union(set(alreadylist)).difference(set(alreadylist)))
def read_url(url):
req = urllib.request.Request(url)
fails = 0
while fails < 5:
try:
content = urllib.request.urlopen(req, timeout=20).read()
break
except:
fails += 1
print(inspect.stack()[1][3] + ' occused error')
soup = BeautifulSoup(content, "lxml")
return soup
errorlist = []
def save_price(urls):
soup = read_url(urls)
price = []
number = []
URLs = []
try:
price1 = soup.find('div', class_ = 'price').get_text()
price.append(int(re.findall(r'\d+', price1)[0]))
number.append(soup.find('span', class_ = 'houseNum').get_text()[5:])
URLs.append(urls)
except:
errorlist.append(urls)
df_dic = {'URL': URLs, 'price' + today : price, 'number':number}
try:
dataset = pd.DataFrame(df_dic, index = number)
dataset = dataset.drop(['number'], axis = 1)
except:
dataset = pd.DataFrame()
dataset.to_sql('price_temp', engine, if_exists = 'append')
pool = ThreadPool(4)
pool.map(save_price, urlist2)
pool.close()
pool.join()
f = open('Notupdated.txt', 'w')
print(errorlist, file = f)
f.close()
df1 = pd.read_sql("select * from price", conn)
df2 = pd.read_sql("select * from price_temp", conn)
df = pd.merge(df1, df2, how='outer', on=['index', 'URL'])
df = df.set_index('index')
df.to_sql('price', engine, if_exists = 'replace')
cu=conn.cursor()
cu.execute('DROP TABLE price_temp')
conn.close()
注1:price是已有的专门存放价格的表格,price_temp是本次更新的价格信息的表格,price_temp更新完成后,与price进行合并。
以上是爬取链家信息的方法,接下来的系列文章会讲如何爬取房天下的信息。
(未完待续...)
