前言
好久没写文章了,前段时间在准备程序猿考试。
我今天很认真,就不发表情了!说到做到!
之前说好的二手房的数据分析也没能如期发出来,因为要查文献了解一下业务知识,所以还在进行中。
最近迷上了NLP
今天介绍一下结巴(jieba)分词框架
作为一种小规模分词
效果还是不错的
接下来我们开始一起看看吧
运行环境和模块安装
运行环境:Python 3.X
首先:
cmd下 pip install jieba
建议使用 pip3 install jieba (特别是那些同时装了Python2和3的朋友,以后装模块可以用pip2和pip3区分)
安装完成后
如果导入没报错,就表示安装完成了!恭喜
# -*- coding:utf-8 -*-
import sys
import os
import jieba #导入结巴分词库
#设置utf-8输出环境
#reload(sys)
#sys.setdefaultencoding('utf-8')
结巴分词模式
结巴分词模块有三种分词模式:
1.全模式
2.精确模式
3.搜索引擎模式
#结巴分词--全模式
sent='天善智能是一个专注于商业智能BI、数据分析、数据挖掘和大数据技术领域的技术社区 www.hellobi.com 。内容从最初的商业智能 BI 领域也扩充到了数据分析、数据挖掘和大数据相关 的技术领域,包括 R、Python、SPSS、Hadoop、Spark、Hive、Kylin等,成为一个专注于数据领域的垂直社区。天善智能致力于构建一个基于数据领域的生态圈,通过社区链接一切 与数据相关的资源:例如数据本身、人、数据方案供应商和企业,与大家一起共同努力推动大数据、商业智能BI在国内的普及和发展。'
wordlist=jieba.cut(sent,cut_all=True)
print("|".join(wordlist))
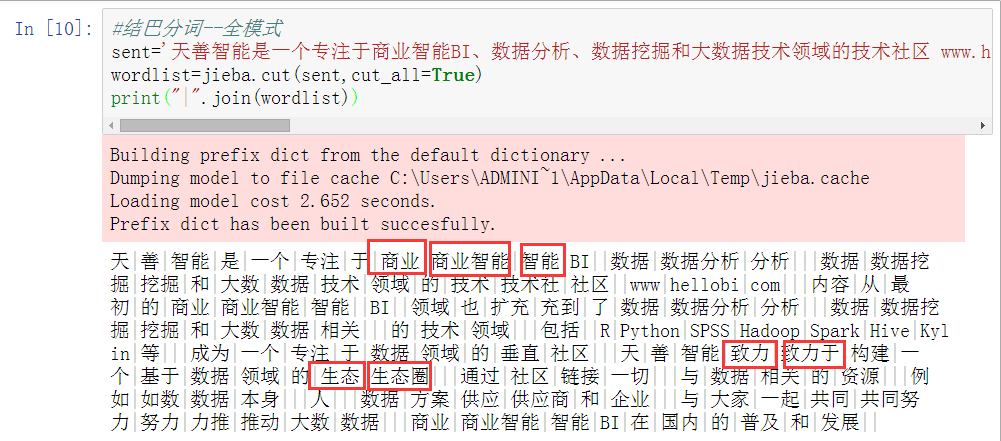
全模式:把句子中所有可以成词的词语都扫描出来,速度非常快,但是不能解决歧义。
这种全模式,会根据字典,将所有出现的字词全部匹配划分,所以会出现重复,显然,这不是我们需要的。
#结巴分词--精确切分
wordlist=jieba.cut(sent)#cut_all=Flase
print("|".join(wordlist))
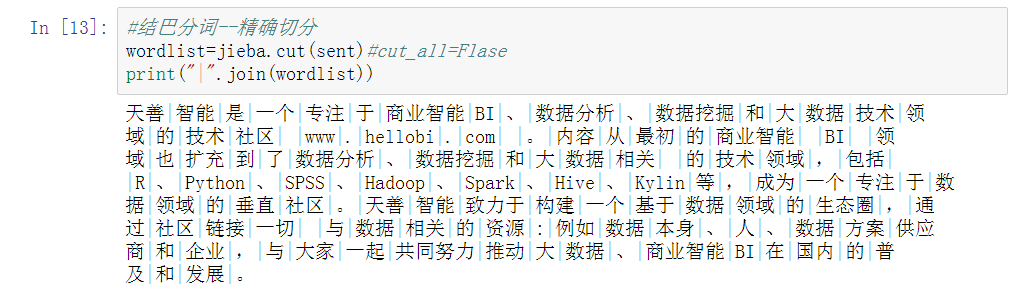
精确模式:试图将句子最精确地切开,适合文本分析(类似LTP分词方式)
而这种精确模式就比较接近我们想要的了。
#结巴分词--搜索引擎模式
wordlist=jieba.cut_for_search(sent)
print('|'.join(wordlist))
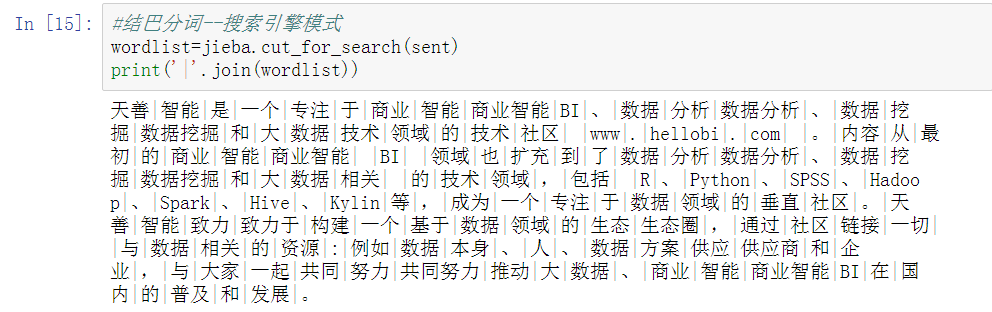
搜索引擎模式:在精确模式的基础上对长词再次切分,提高召回率,适合用于搜索引擎分词。
这种搜索引擎模式也不错呢,更加细化了。
发现新问题--增加用户自定义词典
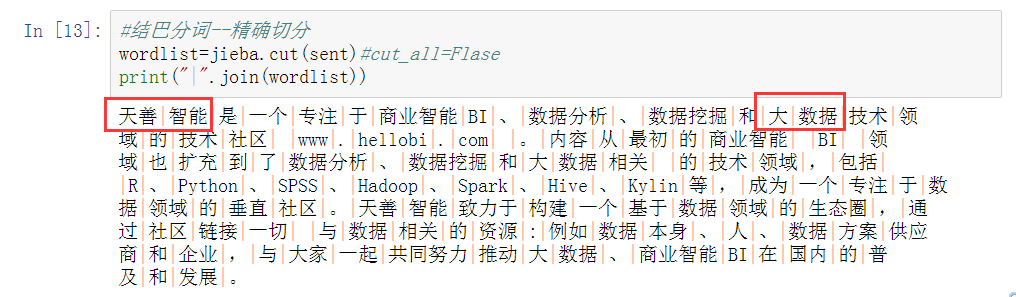
回看精确模式的结果,发现有些新词汇或者专业词汇,例如:天善智能、大数据,这些不应该再被切分,所以在默认词典的基础上,我们可以加载自定义的词典。
使用闪电搜索软件(强推,超好用)搜jieba
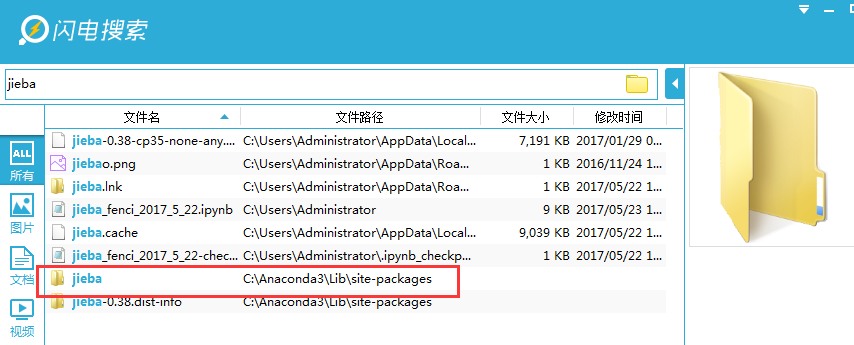
进入我的jieba模块目录
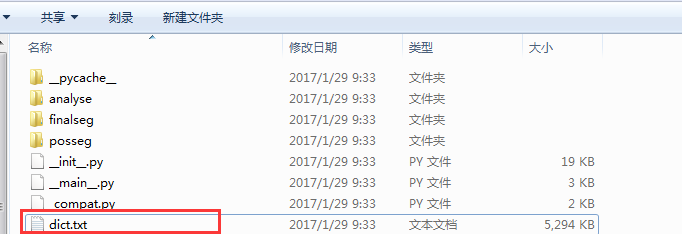
看到有个dict的词典,打开
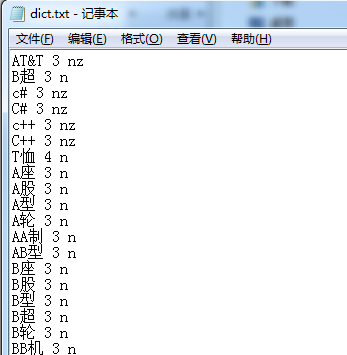
发现有 1.词 2.数字(代表词频,越高越容易匹配到) 3.词性
为了方便,我们自己定义添加一个词典命名为userdict.txt

注意:一定要UTF-8编码
然后保存在同一个目录如下:
接下来就是见证奇迹的时刻了:
#使用用户词典
jieba.load_userdict('C:\\Anaconda3\\Lib\\site-packages\\jieba\\userdict.txt')#加载外部 用户词典
sent='天善智能是一个专注于商业智能BI、数据分析、数据挖掘和大数据技术领域的技术社区 www.hellobi.com 。内容从最初的商业智能 BI 领域也扩充到了数据分析、数据挖掘和大数据相关 的技术领域,包括 R、Python、SPSS、Hadoop、Spark、Hive、Kylin等,成为一个专注于数据领域的垂直社区。天善智能致力于构建一个基于数据领域的生态圈,通过社区链接一切 与数据相关的资源:例如数据本身、人、数据方案供应商和企业,与大家一起共同努力推动大数据、商业智能BI在国内的普及和发展。'
wordlist=jieba.cut(sent)#cut_all=Flase
print("|".join(wordlist))

天善智能分对了,大数据还是没分对!
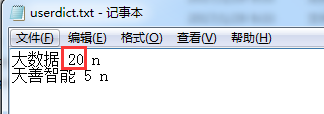
把大数据词频调到20(可能大 和 数据 两个词在默认词典词频挺高)
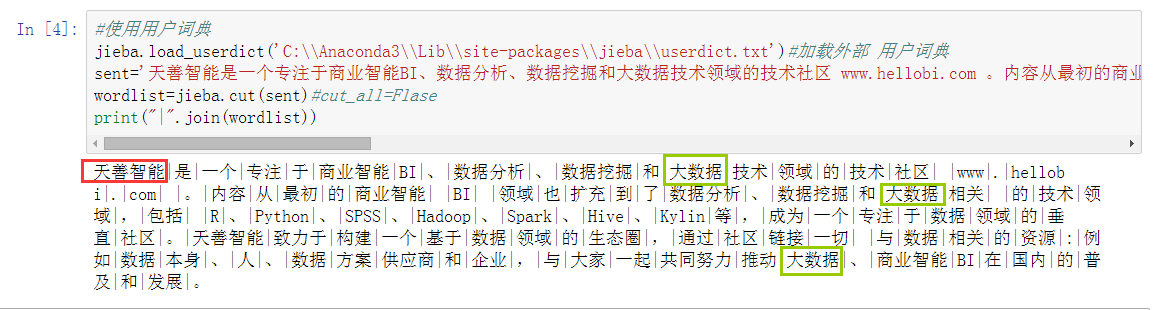
再次运行,大功告成~
哈哈,下次写一篇pyltp的哈工大分词模块(比jieba更厉害哦~)
参考文献:NLP汉语自然语言处理原理与实践 郑捷




