
2.1.1 停用词
具体请看Python做文本挖掘的情感极性分析(基于情感词典的方法)(同1.1.4)
2.1.2 正负向语料库
来源于有关中文情感挖掘的酒店评论语料,
http://www.datatang.com/data/11936
其中正向7000条,负向3000条,当然也可以参考情感分析资源使用其他语料作为训练集。
2.1.3 验证集
Amazon上对iPhone 6s的评论,来源已不可考……

2.2.1 分词
Python做文本挖掘的情感极性分析(基于情感词典的方法)(同1.2.1)
import numpy as np
import sys
import re
import codecs
import os
import jieba
from gensim.models import word2vec
from sklearn.cross_validation import train_test_split
from sklearn.externals import joblib
from sklearn.preprocessing import scale
from sklearn.svm import SVC
from sklearn.decomposition import PCA
from scipy import stats
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.optimizers import SGD
from sklearn.metrics import f1_score
from bayes_opt import BayesianOptimization as BO
from sklearn.metrics import roc_curve, aucimport matplotlib.pyplot as plt
def parseSent(sentence):
seg_list = jieba.cut(sentence)
output = ''.join(list(seg_list)) # use space to join them
return output
2.2.2 去除停用词
Python做文本挖掘的情感极性分析(基于情感词典的方法)(同1.2.2)
2.2.3 训练词向量
模型的输入需是数据元组,那么就需要将每条数据的词语组合转化为一个数值向量,常见的转化算法有但不仅限于如下几种:



在此选用Word2Vec将语料转化成向量
def getWordVecs(wordList):
vecs = []
for word in wordList:
word = word.replace('\n', '')
try:
vecs.append(model[word])
except KeyError:
continue
# vecs = np.concatenate(vecs)
return np.array(vecs, dtype = 'float')
def buildVecs(filename):
posInput = []
with open(filename, "rb") as txtfile:
# print txtfile
for lines in txtfile:
lines = lines.split('\n ')
for line in lines:
line = jieba.cut(line)
resultList = getWordVecs(line)
# for each sentence, the mean vector of all its vectors is used to represent this sentence
if len(resultList) != 0:
resultArray = sum(np.array(resultList))/len(resultList) posInput.append(resultArray)
return posInput
# load word2vec model
model=word2vec.Word2Vec.load_word2vec_format("corpus.model.bin",binary = True)
# txtfile = [u'标准间太差房间还不如3星的而且设施非常陈旧.建议酒店把老的标准间从新改善.', u'在这个西部小城市能住上这样的酒店让我很欣喜,提供的免费接机服务方便了我的出行,地处市中心,购物很方便。早餐比较丰富,服务人员很热情。推荐大家也来试试,我想下次来这里我仍然会住这里']
posInput = buildVecs('pos.txt')
negInput = buildVecs('pos.txt')
# use 1 for positive sentiment, 0 for negativey = np.concatenate((np.ones(len(posInput)), np.zeros(len(negInput))))
X = posInput[:]
for neg in negInput:
X.append(neg)
X = np.array(X)
2.2.4 标准化
虽然笔者觉得在这一问题中,标准化对模型的准确率影响不大,当然也可以尝试其他的标准化的方法。
# standardizationX = scale(X)
2.2.5 降维
根据PCA结果,发现前100维能够cover 95%以上的variance。
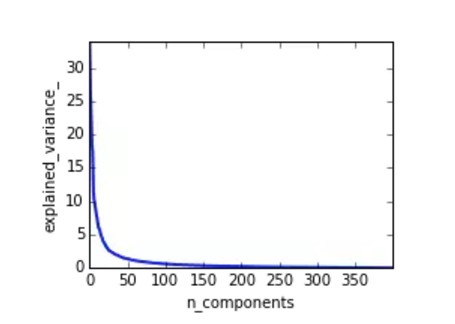
# PCA
# Plot the PCA spectrum
pca.fit(X)
plt.figure(1, figsize=(4, 3))
plt.clf()
plt.axes([.2, .2, .7, .7])
plt.plot(pca.explained_variance_, linewidth=2)
plt.axis('tight')
plt.xlabel('n_components')
plt.ylabel('explained_variance_')
X_reduced = PCA(n_components = 100).fit_transform(X)

2.3.1 SVM (RBF) + PCA
SVM (RBF)分类表现更为宽松,且使用PCA降维后的模型表现有明显提升,misclassified多为负向文本被分类为正向文本,其中AUC = 0.92,KSValue = 0.7。
"""
2.1 SVM (RBF) using training data with 100 dimensions
"""
clf = SVC(C = 2, probability = True)
clf.fit(X_reduced_train, y_reduced_train)
print 'Test Accuracy: %.2f'%
clf.score(X_reduced_test, y_reduced_test)
pred_probas = clf.predict_proba(X_reduced_test)[:,1]
print "KS value: %f" % KSmetric(y_reduced_test, pred_probas)[0]
# plot ROC curve
# AUC = 0.92
# KS = 0.7
fpr, tpr, _ = roc_curve(y_reduced_test, pred_probas)
roc_auc = auc(fpr,tpr)
plt.plot(fpr, tpr, label = 'area = %.2f' % roc_auc)
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.legend(loc = 'lower right')
plt.show()
joblib.dump(clf, "SVC.pkl")
2.3.2 MLP
MLP相比于SVM (RBF),分类更为严格,PCA降维后对模型准确率影响不大,misclassified多为正向文本被分类为负向,其实是更容易overfitting,原因是语料过少,其实用神经网络未免有些小题大做,AUC = 0.91。
"""
2.2 MLP using original training data with 400 dimensions """
model = Sequential()
model.add(Dense(512, input_dim = 400, init = 'uniform', activation = 'tanh'))
model.add(Dropout(0.5))
model.add(Dense(256, activation = 'relu'))model.add(Dropout(0.5))
model.add(Dense(128, activation = 'relu'))model.add(Dropout(0.5))
model.add(Dense(64, activation = 'relu'))model.add(Dropout(0.5))
model.add(Dense(32, activation = 'relu'))model.add(Dropout(0.5))
model.add(Dense(1, activation = 'sigmoid'))model.compile(loss = 'binary_crossentropy', optimizer = 'adam', metrics = ['accuracy'])model.fit(X_train, y_train, nb_epoch = 20, batch_size = 16)
score = model.evaluate(X_test, y_test, batch_size = 16)
print ('Test accuracy: ',score[1])
pred_probas = model.predict(X_test)
# print "KS value: %f" % KSmetric(y_reduced_test, pred_probas)[0]
# plot ROC curve
# AUC = 0.91
fpr,tpr,_ = roc_curve(y_test, pred_probas)
roc_auc = auc(fpr,tpr)
plt.plot(fpr, tpr, label = 'area = %.2f' % roc_auc)
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.legend(loc = 'lower right')plt.show()

实际上,第一种方法中的第二点缺点依然存在,但相比于基于词典的情感分析方法,基于机器学习的方法更为客观。另外由于训练集和测试集分别来自不同领域,所以有理由认为训练集不够充分,未来可以考虑扩充训练集以提升准确率。
