本项目GitHub地址
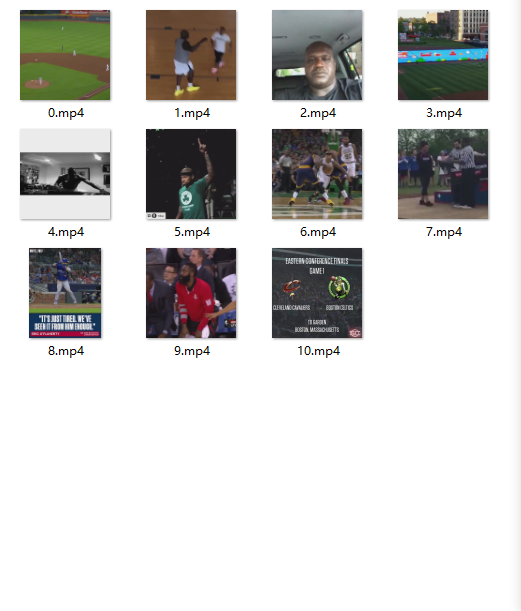
效果图
测试运行:

下载的图片:

下载的视频:
设备必须安装:
- python3
- selenium,bs4模块
- PhantomJS(你也可以自行改为Chrome或者Firefox)
- vpn(本人使用的是付费版green vpn)
相关文档
文件结构
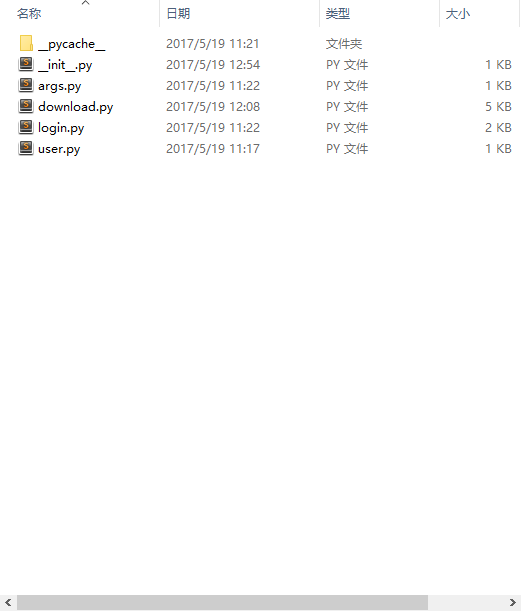
- 一个顶层模块包含ins_deliver类
- 4个小模块:
源码详解
args模块:
PhantomJS_executable_path = "C:/Users/Administrator/Downloads/phantomjs-2.1.1-windows/phantomjs-2.1.1-windows/bin/phantomjs.exe"
service_args = ['--proxy=127.0.0.1:1080', '--proxy-type=socks5']
login_url = "https://www.instagram.com/"
img_form = ".png"
video_form = ".mp4"
- PhantomJS_executable_path - phantomjs浏览器运行文件的所在目录
- service_args - 你的vpn在机器上运行的ip和端口以及一些代理参数,本人使用的green vpn是运行在1080端口,shadowsocks和tor等其他代理同理设置,就是要根据端口设置而已
- login_url - Instagram登陆页面
- img_form, video_form - 图片和视频的默认保存格式
user模块
class User(object):
"""docstring for user"""
def __init__(self, account, password, pic_num = 20, video_num = 10):
self._account = account
self._password = password
self._pic_num = pic_num
self._video_num = video_num
def get_account(self):
return self._account
def get_password(self):
return self._password
def get_pic_num(self):
return self._pic_num
def get_video_num(self):
return self._video_num
- _account - Instagram账号
- _password - 密码
- _pic_num - 要下载个人ins主页上多少图片(按照ins的顺序非时间先后)
- _video_num - 要下载个人ins主页上多少视频(按照ins的顺序非时间先后)
login模块
login模块负责Instagram账号登陆,并且获取你ins主页上关注用户发表的ins内容,只有一个login函数,返回值是一个webdriver的PhantomJS浏览器对象,还有需要下载的图片和视频的BeautifulSoup对象列表:
def login(User):
"""
省略
"""
return driver, img, video
login细节如下:
启动PhantomJS浏览器:
driver = webdriver.PhantomJS(executable_path = args.PhantomJS_executable_path, service_args = args.service_args)
发送get请求,打开ins登陆页面:
driver.get(args.login_url)
找到如下含有“请登陆”字样的a标签:

请登录
a = driver.find_elements_by_tag_name("a")
login_a = a[2]
login_a.click()
输入账号密码,开始登陆:
account = driver.find_element_by_xpath("//input[@name='username']")
account.clear()
account.send_keys(User.get_account())
print("账号输入完成!")
passwd = driver.find_element_by_xpath("//input[@name='password']")
passwd.clear()
passwd.send_keys(User.get_password())
print("密码输入完成!")
button = driver.find_element_by_class_name("_ah57t")
button.click()
print("开始登陆!")
driver.implicitly_wait(0.5)
获取ins主页下要下载的图片和视频列表(BeautifulSoup对象):
bObj = BeautifulSoup(driver.page_source, "html.parser")
img = bObj.findAll("img", {"class": "_icyx7"})
video = bObj.findAll("video", {"class": "_c8hkj"})
当当前页面的图片和视频数量小于要求的数量时,使页面下拉自动加载:
while index_pic < int(User.get_pic_num()) or index_video < int(User.get_video_num()):
driver.execute_script("window.scrollTo(0,document.body.scrollHeight);")
driver.implicitly_wait(0.5)
download模块:
make_folder函数,负责创建存储图片和视频的文件夹:
参数:
def make_folder(User):
folder_name = User.get_account()
while os.path.exists(folder_name):
folder_name = input("文件夹已存在,请输入新的数据存储文件夹名称:")
os.makedirs(folder_name + "/pics")
os.makedirs(folder_name + "/videos")
return folder_name
download函数,负责下载登陆后主页的ins图片和视频
参数:
- imgs - 要下载的图片BeautifulSoup对象列表
- videos - 要下载的视频BeautifulSoup对象列表
- User - 登陆用户User对象
def download(imgs, videos, User):
img_limit = int(User.get_pic_num())
video_limit = int(User.get_video_num())
folder_name = make_folder(User)
index = 0
for img in imgs:
if index > img_limit:
break
urlretrieve(img["src"], folder_name + "/pics/" + str(index) + args.img_form)
time.sleep(0.5)
index += 1
index = 0
for video in videos:
if index > video_limit:
break
urlretrieve(video["src"], folder_name + "/videos/" + str(index) + args.video_form)
time.sleep(0.5)
index += 1
print("下载完毕!")
download_content_by_url函数根据某条ins内容的url下载其中的图片和视频
此函数课进行下载的页面类似如下:
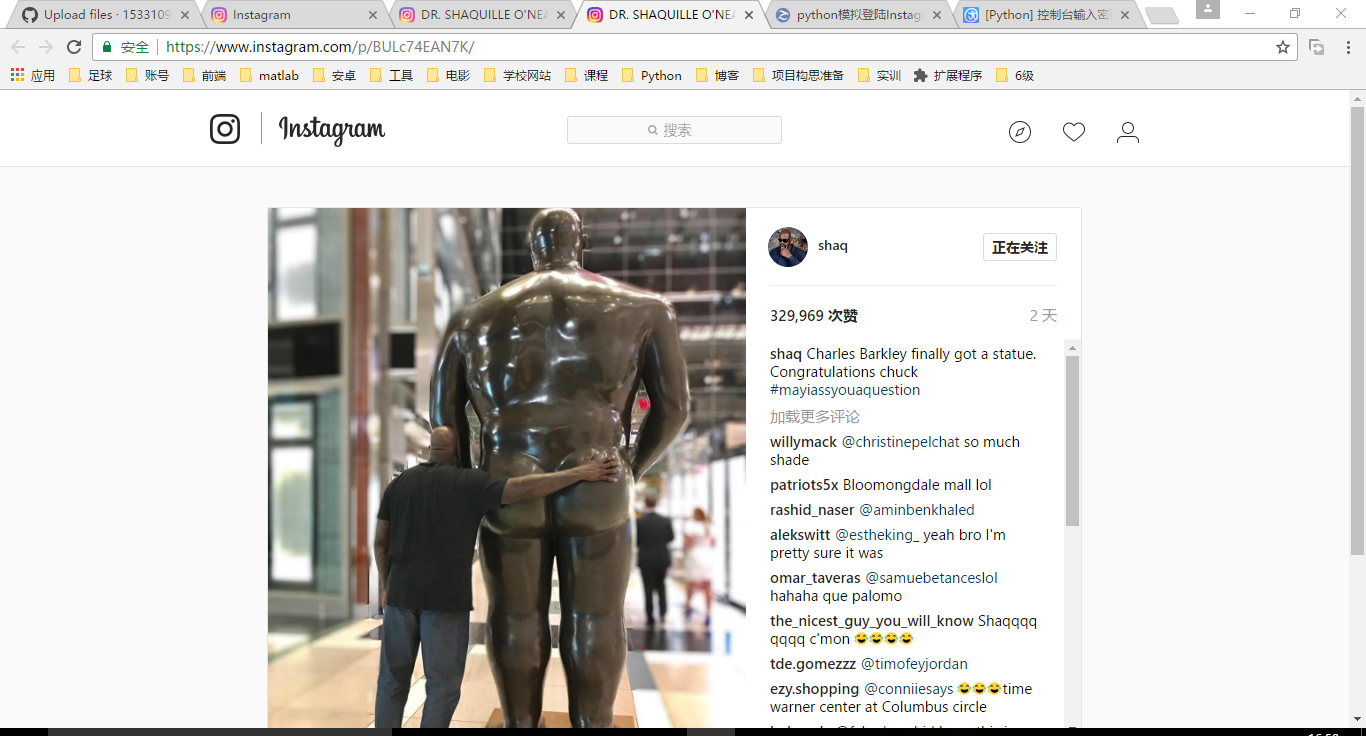
大鲨鱼的一条ins
参数:
def download_content_by_url(driver, url, folder_name):
driver.get(url)
bObj = BeautifulSoup(driver.page_source, "html.parser")
img = bObj.find("img", {"class": "_icyx7"})
video = bObj.find("video", {"class": "_c8hkj"})
while os.path.exists(folder_name):
folder_name = input("文件夹已存在,请重新命名:")
if img:
os.makedirs(folder_name + "/pics")
urlretrieve(img["src"], folder_name + "/pics/pic" + args.img_form)
if video:
os.makedirs(folder_name + "/videos")
urlretrieve(video["src"], folder_name + "/videos/video", args.video_form)
download_contents_by_url函数根据其他某个ins用户的主页进行下载图片和视频
此函数可进行下载的页面类似如下:
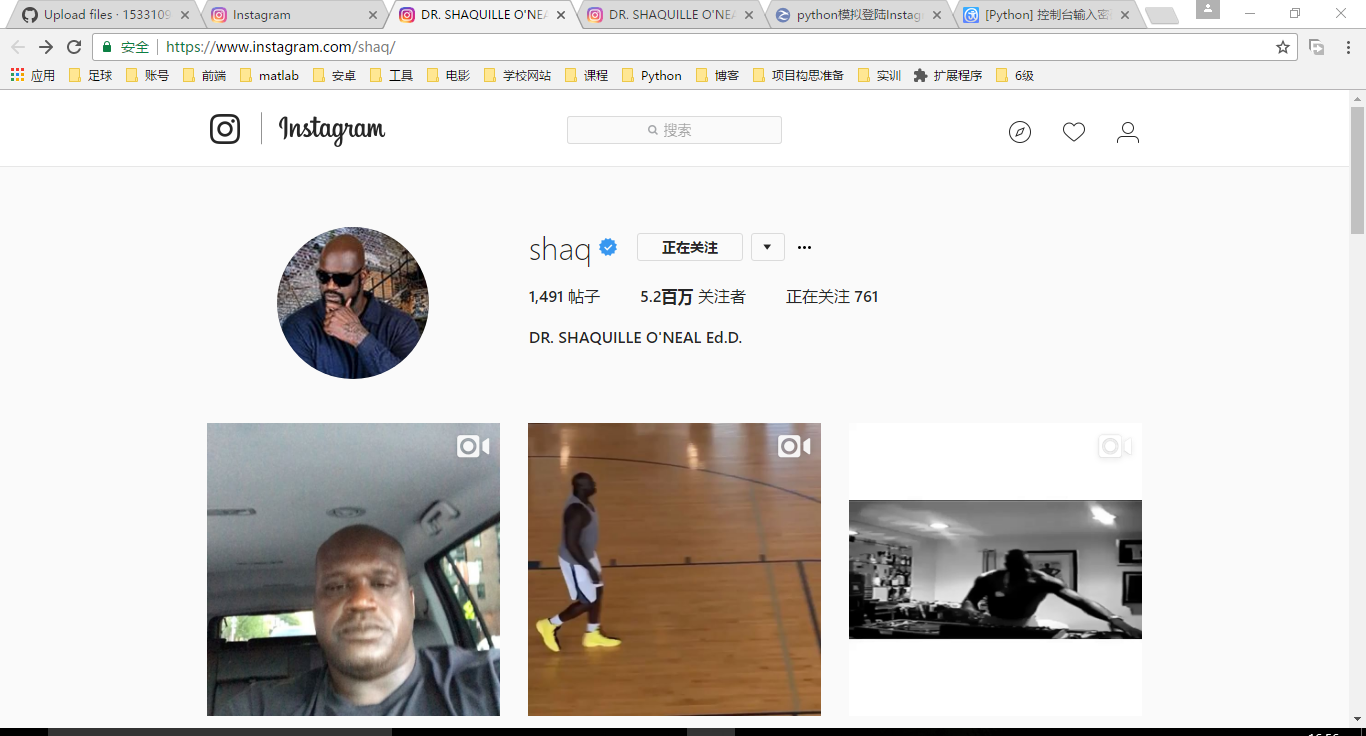
大鲨鱼的ins主页
参数:
def download_contents_by_url(driver, url, folder_name, num_pic, num_video):
"""
省略
"""
完整代码:
代码有点点多,不方便全部展示,详情请看我的GitHub(注:main是测试脚本,不过你也可以像我一样在命令行中进行运行测试)

