![送给每一个jr的[重浮力]python爬虫虎扑BXJ福利教程](https://pic4.zhimg.com/v2-5653c4a461947dfd125f4c918119d057_r.png)
知乎和虎扑都是我自己喜欢的平台。
虎扑的步行街的确刷掉了我很多的生命,但是也收获了很多jr的正能量和归属感。
我是一个不怎么爱收藏的浮力的良好青年,但是怎奈发帖必须要福利图呢?
我是一个为jr着想,知道很多朋友都想要收藏步行街的福利图。
所以秉着这样高尚的精神,我用爬虫收藏了步行街的福利图。因为发帖数量真的很多,所以只能下载了部分。授人以鱼不如授人以渔,我也想分享自己写的python的爬虫。
如果你们不会python,没关系!文末有我下载好的福利压缩文件,放心拿去用。
新手友好型教程,需要的朋友可以拿去练手。
主要用的库是urllib,urllib2和正则匹配
1、获得发帖页面地址
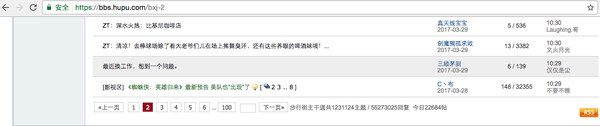
这里我们看到每一个页面的地址组成方式是https://bbs.hupu.com/bxj 加 "-" 加你浏览的页数。意思就是如果你要看第100页的内容,你的网站地址就https://bbs.hupu.com/bxj-100。
那么我们就可以很容易构建出前100个页面地址
def get_pages(url):
pages = list() #新建一个list
for i in range(1,100,1):
new_url = url+"-"+str(i) #构建一个完整的地址
pages.append(new_url)
return pages
你可以运行这个函数,看看最后的结果是不是你想要的那些页面的地址
2、进入每个页面,获得每个帖子地址
我们来看下第一个页面的源代码。

很容易看到每个帖子的链接格式:
<a id="" href="/xxxxxxxx.html">xxxxxxxxxxxxxxxx</a>
href="/xxxxxxxx.html
显然不是一个完整的链接。我们点击进入之后,可以看到完整的链接是https://bbs.hupu.com/xxxxxxxx.html
所以我们找到了如何构建每个帖子的地址。在之前我们先要请求每个发帖页面
def get_links(url): #url参数就是之前获得的一个页面地址
urls = list()
req = urllib2.Request(url)
html = urllib2.urlopen(req).read()
basic_url = 'https://bbs.hupu.com'
#<a id="" href="/xxxxxxxx.html">xxxxxxxxxxxxxxxx</a>
#通过正则匹配所要的内容
pattern = re.compile(r'''<a id="" href="https://ask.hellobi.com/(/\d+.html)''')
for links in re.findall(pattern,html):
links = basic_url + links #构建帖子地址
urls.append(links)
return links
3、进入每个帖子,获得图片链接
这里我随机进入一个帖子看看咯
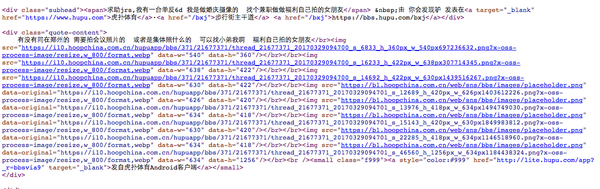 这是他的源代码,可以看到链接如下
这是他的源代码,可以看到链接如下
<img src="https://i10.hoopchina.com.cn/hupuapp/bbs/371/21677371/thread_21677371_20170329094700_s_6833_h_360px_w_540px697236632.png?x-oss-process=image/resize,w_800/format,webp" data-w="540" data-h="360"/>
可以用下面正则匹配。
pattern = re.compile(r'''https://i10.hoopchina.com.cn/.+?jpeg''')
def get_img(url,i):#参数是每个图片的地址和变量i
n = 1
#这里是我下载目的地址
file_path = '/Volumes/Elements/python_project/hupu/'
req = urllib2.Request(url)
html = urllib2.urlopen(req).read()
pattern = re.compile(r'''https://i10.hoopchina.com.cn/.+?jpeg''')
for links in list(set(re.findall(pattern,html))):
#文件名有i+n组成
filename = file_path+str(i)+ "-"+str(n)+".jpg"
urllib.urlretrieve(links,filename=filename)
n +=1
4、最后将函数合起来
bxj = 'https://bbs.hupu.com/bxj'
page_list = get_pages(bxj)
alllinks = list()
#将所有页面中的所有帖子链接添加到alllinks列表中
for page in page_list:
alllinks += get_links(page)
#访问每一个帖子
i = 1
for img_link in alllinks:
try:
#开始下载图片
get_img(img_link,i)
i +=1
print img_link,"has been downloaded"
time.sleep(2)
except:
print img_link,"no pictures"
测试代码效果如下。
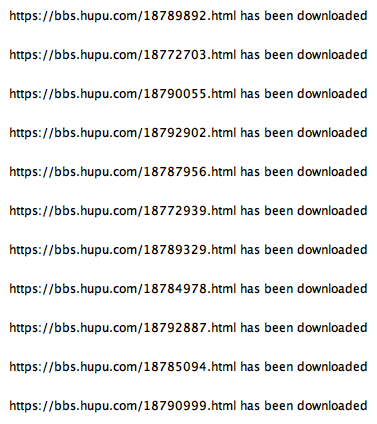
这是我上周测试的内容:
虎扑福利集合.zip 链接: https://pan.baidu.com/s/1byWXNS 密码: savb
如果你想要最新的图片,欢迎私信,我也可以帮你下载一下。 哈哈
其实步行街中,除了福利图,还有好多有意思的图片。
封面来自@二院画师
