

无论我们通过浏览器打开网站、访问网页,还是通过脚本对URL网址进行访问,本质上都是对HTTP服务器的请求,浏览器上所呈现的、控制台所显示的都是HTTP服务器对我们请求的响应。
以打开我的个人网站为例,我们在地址栏输入“zmister.com”,浏览器上呈现的是下图:
我们按F12打开网页调试工具,选择“network”选项卡,可以看到我们对zmister.com的请求,以及zmister.com给我们的响应:
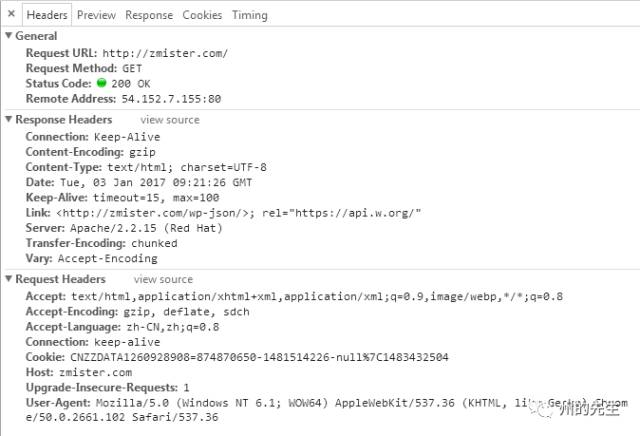

通常HTTP消息包括客户机向服务器的请求消息和服务器向客户机的响应消息。这两种类型的消息由一个起始行,一个或者多个头域,一个指示头域结束的空行和可选的消息体组成。
我们看上面对zmister.com的HTTP示例来说明:
1、HTTP概览
Request URl:表示请求的URL
Request Method:表示请求的方法,此处为GET。除此之外,HTTP的请求方法还有OPTION、HEAD、POST、DELETE、PUT等,而最常用的就是GET和POST方法:
POST:
向指定资源提交数据,请求服务器进行处理(例如提交表单或者上传文件)。数据被包含在请求本文中。这个请求可能会创建新的资源或修改现有资源,或二者皆有。
GET:
向指定的资源发出“显示”请求。
Status Code:显示HTTP请求和状态码,表示HTTP请求的状态,此处为200,表示请求已被服务器接收、理解和处理;
状态代码的第一个数字代表当前响应的类型,HTTP协议中有以下几种响应类型:
1xx消息——请求已被服务器接收,继续处理
2xx成功——请求已成功被服务器接收、理解、并接受
3xx重定向——需要后续操作才能完成这一请求
4xx请求错误——请求含有词法错误或者无法被执行
5xx服务器错误——服务器在处理某个正确请求时发生错误
2、HTTP请求头
Accept:表示请求的资源类型;
Cookie:为了辨别用户身份、进行 session 跟踪而储存在用户本地终端上的数据;
User-Agent:表示浏览器标识;
Accept-Language:表示浏览器所支持的语言类型;
Accept-Charset:告诉 Web 服务器,浏览器可以接受哪些字符编码;
Accept:表示浏览器支持的 MIME 类型;
Accept-Encoding:表示浏览器有能力解码的编码类型;
Connection:表示客户端与服务连接类型;
基本的HTTP介绍就结束了,如果需要更加详细的HTTP知识,推荐一本HTTP入门书《图解HTTP》
下面,我们用Python来实现一个简单的HTTP请求

这里继续用我的个人网站http://zmmister.com 作示例
打开代码编辑器,输入以下代码:
#coding:utf-8
import requests
url = "http://zmister.com"data = requests.get(url)
这样,就完成了一个简单的对zmister.com的HTTP请求。
我们看看这个请求的状态码:
data.status_code
结果返回的是:200
再看看响应的主体消息:
data.content

对这些凌乱的html源码进行处理,就需要使用到BeautifulSoup模块了,下一章咱们继续。

长按二维码
关注
