
这是菜鸟学Python的第76篇原创文章
阅读本文大概需要8分钟
上一篇我们讲了关于Python excel的基础知识,今天我们要实战一下.我从Google下载了1992-2008年美国人名排名榜,抽取了其中5年的数据,每年最火的2000个人名,男女各1000名,这个1000名是当年最流行的名字,从第一名排到第1000名。共计10000个人美国人名形成的一个较大的excel数据表格,今天我们就对这个大表格进行初步挖掘一下,看看这些数据背后能告诉我们什么故事~~
今天虽然讲的是Excel的实战运用,但是用到了很多以前学习的知识,算是一个小小的综合练习,希望能对大家有帮助
1.10000美国人名的表格长啥样
这张大的Excel文件是'baby_names.xlsx',长什么样呢,一共有5个sheets,每个sheet都是对应的年份:'1992','1996','2000','2004','2008'
内容如下:
第一行是文本介绍:比如1992出生的美国人,有1000个人,名字按照流行程度排序
第二行是标题:Rank,Male Name,Female Name
第3行-1002行:都是对应的数据:
第一列是:排名名次
第二列是:男孩名字
第三列是:女孩名字
2.我们想挖掘出什么
我们初步可以挖一下以下几个方面:
1.10000美国人里面谁的名字最长的是谁,名字最短的那个
2.10000美国人里面的名字首字母都是用从A-Z,哪个首字母的人最多,有没有什么禁忌,哪个首字母是美国人不太愿意用的
3.我们中国人名字3个字的比较多,那么10000美国人里面多长的名字会比较火
4.1992-2008排名前5的名字,经过16年的变化,这些火的名字是不是持久不衰,哪个是一直很吃香的好名字的
3.读取Excel
a).我们的数据结构用一个大的字典BABY_DATA存储所有的数据
b).用xlrd模块读取excel文件,并读取所有的sheets名字

c).写一个函数extract_each_sheet
根据每个sheet名字,把所有的数据都读到BABY_DATA字典里面

d).看一下BABY_DATA长什么样
from pprint import pprint
pprint(BABY_DATA) #美化打印一下
>>

4.探秘:最长和最短的名字
查找单个sheet里面的名字最短和最长

思路步骤:
a).上面我们已经构建好了10000人名的大字典,下面就是对这个字典不停的挖掘,提取数据
b).我们通过年限和性别,得到对应的人名数据
c).利用sorted把人名按照长度排序
d).取这个排序好的列表的第一,就是名字最长的
e).取这个排序好的列表的倒数第一,就是名字最短的
5.探秘:10000人内男女名字最长和最短
看看从1992到2008,每年男女名字最长和最短的,有没有什么规律

结论:
发现16年的变迁:
男孩的名字最长的: 出现频率最高的是Christopher,最短是Bo
女孩的名字最长的: 出现频率最高的是Jacqueline,最短是Aja
6.探秘:首字母
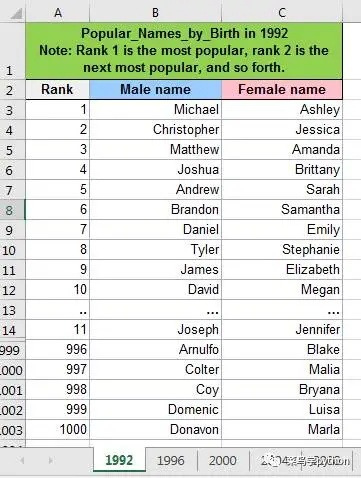
想知道哪个字母开头的人名最多,在我国百家姓里面,姓张姓王的比较多。那我们把每年2000美国人,按照字母排序,看看在老外名字里面,哪个字母开头的人名最多
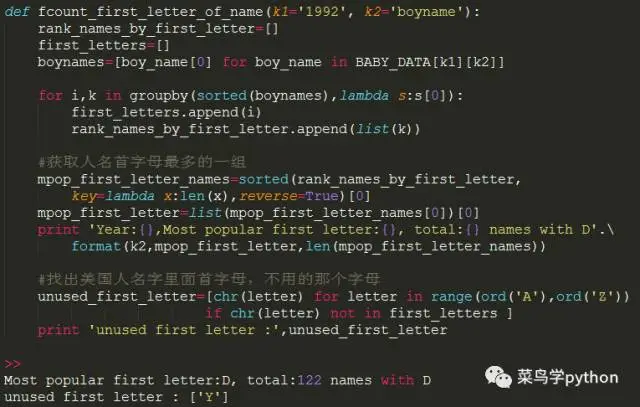
>>
Most popular first letter:D, total:122 names with D
unused first letter : ['Y']
思路步骤:
1).根据输入的2个key,得到对应的男女名字列表
2).因为每个名字的列表里面一个元组(u'Michael', 1.0),所以我们要用name[0]提取名字
3).接着我们要过滤出所有首字母相同开头的名字,这里用到一个非常重要的技巧函数,大名鼎鼎的itertools模块里的groupby函数,可以把列表里面的元素,按照某种规则排列提取
4).得到rank_names_by_first_letter列表,这个列表里面嵌套了若干个列表,这里面存的是按照首字母相同的人为子列表,我们只需要sorted
5).就可以得到首字母最多的一组
6),然后我们把所有的人名首字母过滤一下,看看那个字母是老外人名里面不喜欢开头的
结论:
上面是1992的数据,发现老外里面D开头的人名比较多,不喜欢Y开头
7.探秘:名字长度
我们中国人的名字里面一般是3个字的比较多,我们探索一下美国人的名字长度最流行是多长,这10000个老外的名字,名字长度有长有短,看看这么数据里面,那种长度的人名是比较火比较多的
先观察男孩,名字多长比较火
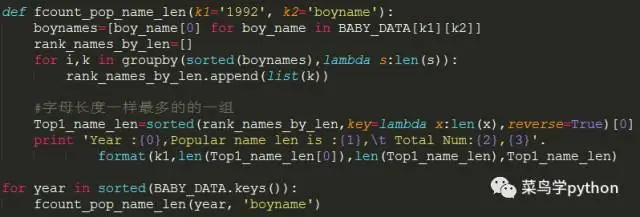
>>
Year :1992,Popular name len is :7
Year :1996,Popular name len is :7
Year :2000,Popular name len is :7
Year :2004,Popular name len is :7
Year :2008,Popular name len is :7
#观察女孩,名字多长比较火
>>
Year :1992,Popular name len is :6, Total Num:5,[u'Alysha', u'Alysia', u'Alyson', u'Alyssa', u'Amanda']
Year :1996,Popular name len is :6, Total Num:5,[u'Alisha', u'Alison', u'Alissa', u'Alivia', u'Aliyah']
Year :2000,Popular name len is :6, Total Num:6,[u'Athena', u'Aubree', u'Aubrey', u'Audrey', u'Aurora', u'Autumn']
Year :2004,Popular name len is :6, Total Num:7,[u'Athena', u'Aubree', u'Aubrey', u'Aubrie', u'Audrey', u'Aurora', u'Autumn']
Year :2008,Popular name len is :5, Total Num:6,[u'Mylee', u'Mylie', u'Nadia', u'Naima', u'Nancy', u'Naomi']
结论:
发现男孩取名的话,字母长度为7的人很多
发现女孩取名的话,字母长度为6的人很多
8.探秘:经久不衰一直很火的人名
虽然我们这5个sheets人名是按照流行程度排行的,但是1992前5的人名,16年过去了,到了2008年是否还继续火呢,我们来看一下流行趋势
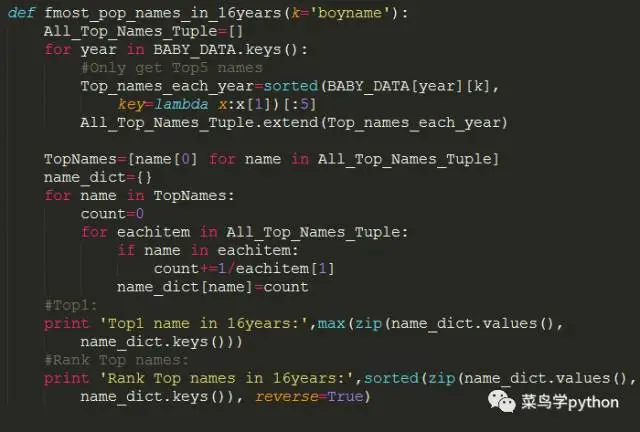
>>
Top1 name in 16years: (3.5, u'Michael')
Rank Top names in 16years: [(3.5, u'Michael'), (3.3333333333333335, u'Jacob'), (1.4166666666666665, u'Matthew'), (1.2833333333333332, u'Joshua'), (0.95, u'Christopher'), (0.5333333333333333, u'Ethan'), (0.2, u'Daniel'), (0.2, u'Andrew')]
思路步骤:
1).首先我们取每年Top5的名字,这些名字都是一个一个的tuple(人名,名次)
然后把这些tuple按照名次排序,存入All_Top_Names_Tuple
2).然后我们把每个名字取个百分比,比如1992年Michael排名第一,1996年Michael排名第二,2000年Michael排名第三
计算公司:1/1+1/2+1/3=1.83
累计得分最高的就是最火的
发现:
发现16年以来,最火的名字是叫Michael,经久不衰啊~~
女孩的大家自己去试一下
用Python处理Excel实战就讲到这里,其实还能挖掘出很多,想想如果不是1万而是1百万数据,若有时间维度的就更有趣了.上面用到的都是一些基础知识,算是开胃菜,只是做了初步的统计分析.数据分析是一门很有意思的活,是科学也是艺术。真正的数据挖掘,一定是要用到机器学习里面的很多算法,甚至是深度学习,而且需用一定的数学和统计学知识,水还蛮深的 ~~好,今天的内容就先讲到这里,欢迎大家留言讨论
历史人气文章
Python语言如何入门
同学,学Python真的不能这样学
用Python写个弹球的游戏
Python写个迷你聊天机器人|生成器的高级用法
用Python破解微软面试题|24点游戏
2道极好的Python算法题|带你透彻理解装饰器的妙用
一道Google的算法题 |Python巧妙破解
长按二维码,关注【菜鸟学python】

