SCAD的提出
据说学术界有一种现象叫做『大牛挖坑,小牛灌水』。而我等『小菜』就只有『吹水』的份了。
不过还真不要小看本『小菜』,根据著名的『六度分割理论』,我跟大牛的距离也是近的很呢。
不信我跟你算算。将我引入统计学习领域大门的钟威老师,师承自统计学习大牛 Runze Li老师,而Runze Li老师的导师居然是统计学习领域的泰斗级人物范剑青老师,Jianqing Fan!
看来六度分割理论还真有那么一点道理呀!
Runze Li老师在变量选择方法的研究中,有着非常突出的成果,著名的SCAD惩罚方法即由他在其博士论文中首次提出。而变量选择作为统计学习领域的一大热点,当然不可不知一二。于是,我们今天来学习一下Runze Li老师提出的SCAD惩罚方法。
八卦结束,切入正题。
论文笔记
SCAD的提出源自于论文 Variable Selection via Nonconcave Penalized Likelihood and its Oracle Properties。以下是这篇学术论文的学习笔记。
摘要
本文提出了一种用于同时达到选择变量和预测模型系数的目的的方法——SCAD。这种方法的罚函数是对称且非凹的,并且可处理奇异阵以产生稀疏解。此外,本文提出了一种算法用于优化对应的带惩罚项的似然函数。这种方法具有广泛的适用性,可以应用于广义线性模型,强健的回归模型。借助于波和样条,还可用于非参数模型。更进一步地,本文证明该方法具有Oracle性质。模拟的结果显示该方法相比主流的变量选择模型具有优势。并且,模型的预测误差公式显示,该方法实用性较强。
SCAD的理论理解
在总结了现有模型的一些缺点之后,本文提出构造罚函数的一些目标:
罚函数是奇异的(singular)
连续地压缩系数
对较大的系数产生无偏的估计
SCAD模型的Oracle性质,使得它的预测效果跟真实模型别无二致。
并且,这种方法可以应用于高维非参数建模。
SCAD的目标函数如下:
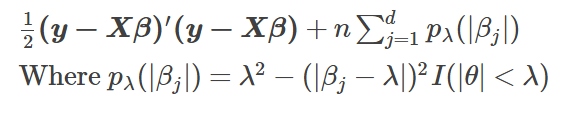
SCAD的罚函数与$\theta$的(近似)关系如下图所示。

可见,罚函数可以用二阶泰勒展开逼近。
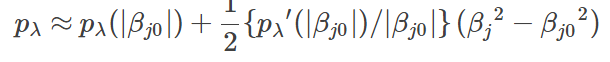
Hard Penality,lasso,SCAD的系数压缩情况VS系数真实值的情况如下图所示。

可以看到,lasso压缩系数是始终有偏的,Hard penality是无偏的,但压缩系数不连续。而SCAD既能连续的压缩系数,也能在较大的系数取得渐近无偏的估计。
这使得SCAD具有Oracle性质。
SCAD的缺点
SCAD的实现
SCAD迭代公式
SCAD的目标函数如下:
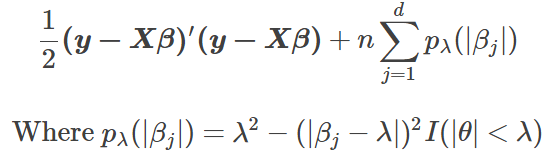
在βj0≠0βj0≠0时,罚函数可以用二阶泰勒展开逼近。
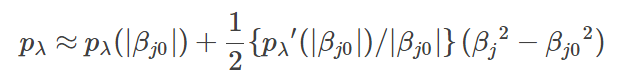
从而,有如下迭代公式:
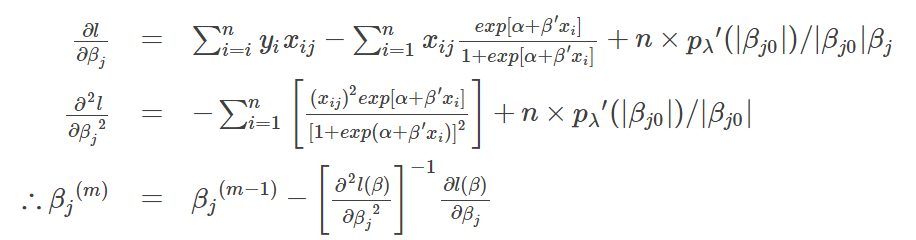
根据以上公式,代入迭代步骤,即可实现算法。
SCAD的R实现
library(MASS)
Simu_Multi_Norm<-function(x_len, sd = 1, pho = 0.5){
V <- matrix(data = NA, nrow = x_len, ncol = x_len)
for(i in 1:x_len){
for(j in 1:x_len){
V[i,j] <- pho^abs(i-j)
}
}
V<-(sd^2) * V
return(V)
}
set.seed(123)
X<-mvrnorm(n = 200, mu = rep(0,10), Simu_Multi_Norm(x_len = 10,sd = 1, pho = 0.5))
beta<-c(1,2,0,0,3,0,0,0,-2,0)
prob<-exp( X %*% beta)/(1+exp( X %*% beta))
y<-rbinom(n = 200, size = 1,p = prob)
mydata<-data.frame(X = X, y = y)
b_real<-beta
p_lambda<-function(theta,lambda = 0.025){
p_lambda<-sapply(theta, function(x){
if(abs(x)< lambda){
return(lambda^2 - (abs(x) - lambda)^2)
}else{
return(lambda^2)
}
}
)
return(p_lambda)
}
p_lambda_d<-function(theta,a = 3.7,lambda = 0.025){
if(abs(theta) > lambda){
if(a * lambda > theta){
return((a * lambda - theta)/(a - 1))
}else{
return(0)
}
}else{
return(lambda)
}
}
loglikelihood_SCAD<-function(X, y, b){
linear_comb<-as.vector(X %*% b)
ll<-sum(y*linear_comb) + sum(log(1/(1+exp(linear_comb)))) - nrow(X)*sum(p_lambda(theta = b))
return (ll)
}
b.best_GS<-b.best
b0<-b.best_GS
b1<-b0
b.best_SCAD<-b0
ll.old<-loglikelihood_SCAD(X = X,y = y, b = b0)
diff<-1
iter<-0
epsi<-1e-10
max_iter<-100000
b_history<-list(data.frame(b0))
ll_list<-list(ll.old)
while(diff > epsi & iter < max_iter){
for(j in 1:length(b_real)){
if(abs(b0[j]) < 1e-06){
next()
}else{
linear_comb<-as.vector(X %*% b0)
nominator<-sum(y*X[,j] - X[,j] * exp(linear_comb)/(1+exp(linear_comb))) +
nrow(X)*b0[j]*p_lambda_d(theta = b0[j])/abs(b0[j])
denominator<- -sum(X[,j]^2 * exp(linear_comb)/(1+exp(linear_comb))^2) +
nrow(X)*p_lambda_d(theta = b0[j])/abs(b0[j])
b0[j]<-b0[j] - nominator/denominator
if(abs(b0[j]) < 1e-06){
b0[j] <- 0
}
}
}
ll.new<- loglikelihood_SCAD(X = X, y = y, b = b0)
if(ll.new > ll.old){
b.best_SCAD<-b0
}
diff<- abs((ll.new - ll.old)/ll.old)
ll.old <- ll.new
iter<- iter+1
b_history[[iter]]<-data.frame(b0)
ll_list[[iter]]<-ll.old
}
b_hist<-do.call(rbind,b_history)
ll_hist<-do.call(rbind,ll_list)
iter
ll.best<-max(ll_hist)
ll.best
b.best_SCAD
cbind(coeff_glm,b.best,b.best_SCAD,b_real)
library(ncvreg)
my_ncvreg<-ncvreg(X,y,family = c("binomial"),penalty = c("SCAD"),lambda = 2)
my_ncvreg$beta
my_ncvreg<-ncvreg(X,y,family = c("binomial"),penalty = c("SCAD"))
summary(my_ncvreg)
my_ncvreg$beta
scad_cv<-cv.ncvreg(X,y,family = c("binomial"),penalty='SCAD')
scad_cv$lambda.min
mySCAD=ncvreg(X,y,family = c("binomial"),penalty='SCAD',lambda=scad_cv$lambda.min)
summary(mySCAD)
ncv_SCAD<-mySCAD$beta[-1]
myFinalResults<-cbind(无惩罚项回归=coeff_glm, GS迭代 = b.best,
GS_SCAD迭代 = b.best_SCAD, ncvreg = ncv_SCAD,真实值 = b_real)
save(myFinalResults,file = "myFinalResults.rda")
