我们日常生活中接触到的大部分数据都是以文本的形式存在。如何高效地处理文本数据,将看似杂乱无章的数据整理成可以进行统计分析的规则数据,是『数据玩家』必备的一项重要技能。
今天,我们要学习的『正则表达式』和『字符处理函数』将助你成为点石成金的数据魔法师。
正则表达式
在进行爬虫任务的时候,部分情况下,我们可以使用Xpath来提取我们需要的网页信息。但是,当我们需要的数据以一定的规则隐藏在一段文字中时,就不可避免地要使用到正则表达式。
正则表达式是对字符串类型数据进行匹配判断,提取等操作的一套逻辑公式。
处理字符串类型数据方面,高效的工具有Perl和Python。如果我们只是偶尔接触文本处理任务,则学习Perl无疑成本太高;如果常用Python,则可以利用成熟的正则表达式模块:re库;如果常用R,则使用Hadley大神开发的stringr包则已经能够游刃有余。
下面,我们先简要介绍重要并通用的正则表达式规则。接着,总结一下stringr包中重要的字符处理函数。
如果有时间,我将后续补充一个综合的使用案例。
元字符
正则表达式中,有12个字符被保留用作特殊用途。他们分别是:
[ ] \ ^ $ . | ? * + ( )
它们的作用如下:
[ ]:括号内的任意字符将被匹配;
\:具有两个作用:- 1.对元字符进行转义
- 2.一些以
\开头的特殊序列表达了一些字符串组
^:匹配字符串的开始.将^置于character class的首位表达的意思是取反义。如[^5]表示匹配除了”5”以外的任何字符。
$:匹配字符串的结束。但将它置于character class内则消除了它的特殊含义。如[akm$]将匹配’a’,’k’,’m’或者’$’.
.:匹配除换行符以外的任意字符。
|:或者
?:前面的字符(组)最多被匹配一次
*:前面的字符(组)将被匹配零次或多次
+:前面的字符(组)将被匹配一次或多次
( ):表示一个字符组,括号内的字符串将作为一个整体被匹配。
重复

转义
如果我们想查找元字符本身,如”?”和”*“,我们需要提前告诉编译系统,取消这些字符的特殊含义。这个时候,就需要用到转义字符\,即使用\?和\*.当然,如果我们要找的是\,则使用\\进行匹配。
注:R中的转义字符则是双斜杠:\\
R中预定义的字符组
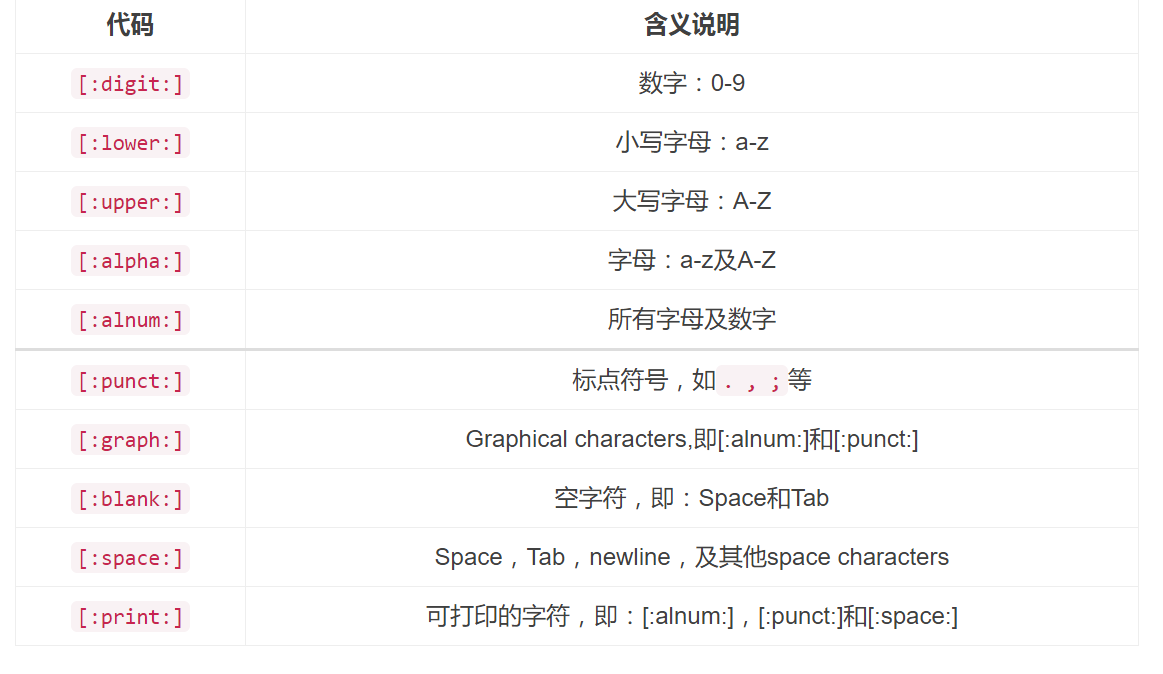
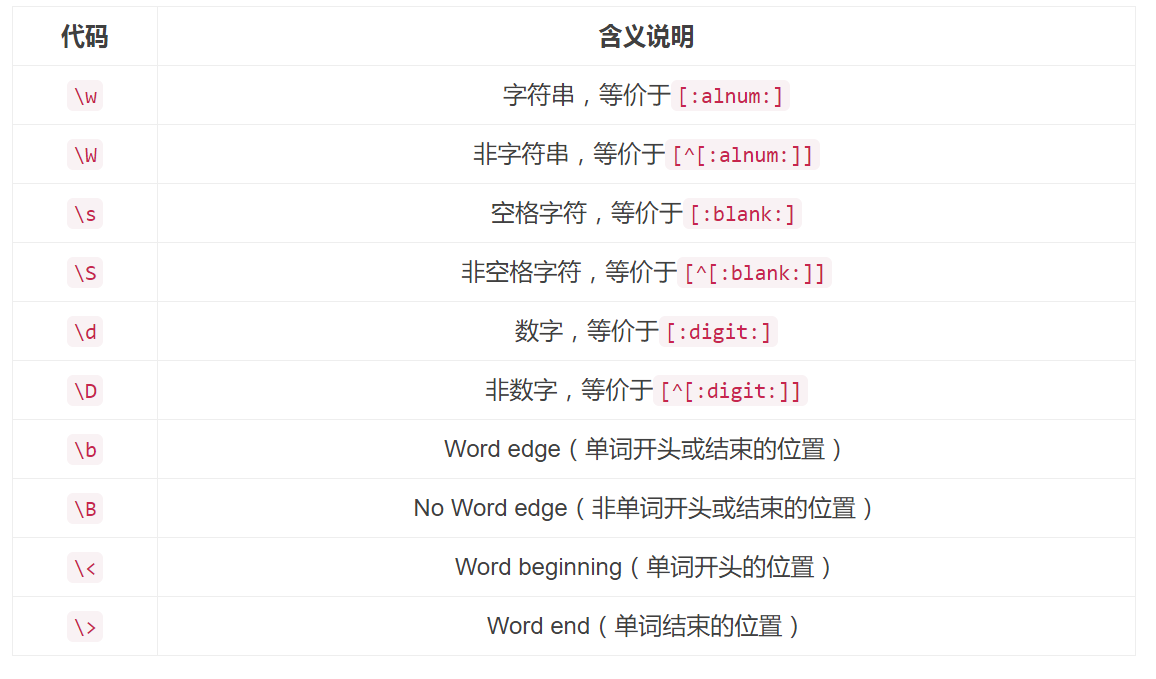
代表字符组的特殊符号
stringr包中的重要函数
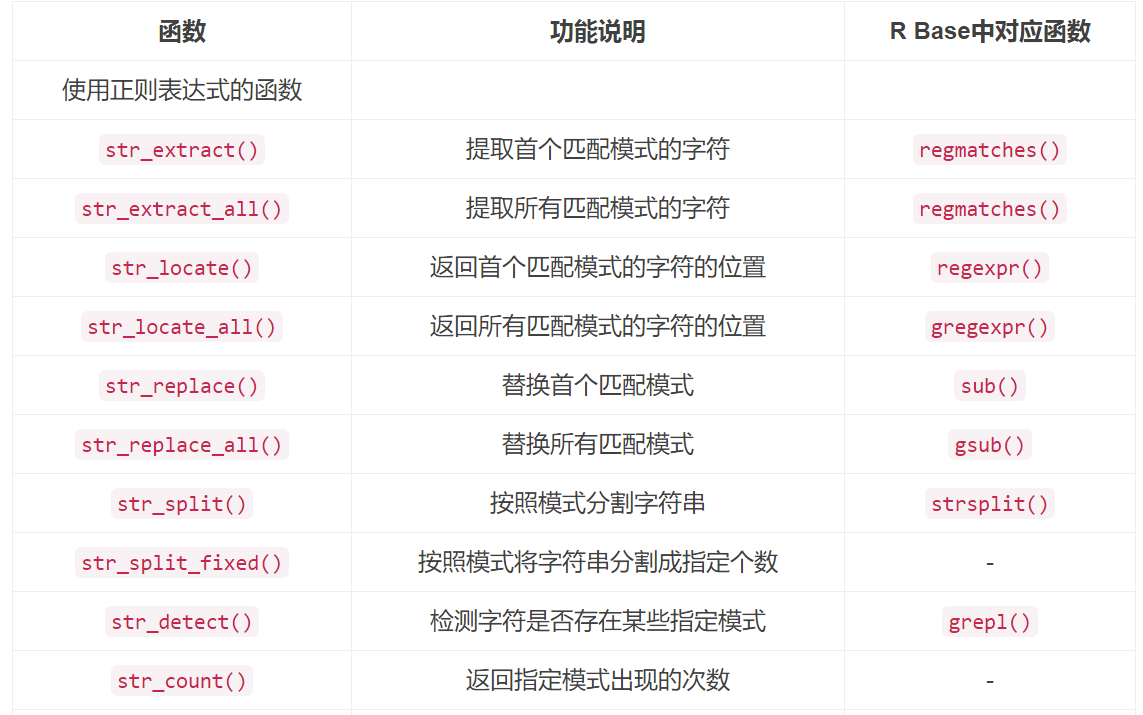
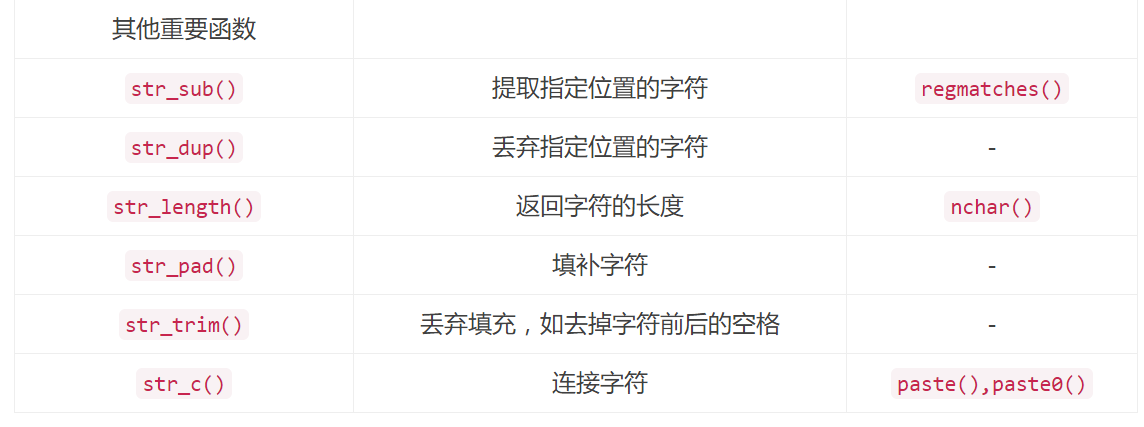
可见,stringr包中的字符处理函数更丰富和完整(其实还有更多函数),并且更容易记忆。或许速度也会更快。
其他相关的重要函数
windows下处理字符串类型数据最头疼的无疑是编码问题了。这里介绍几个编码转换相关的函数。

参考文献:
