

前言
本文是Mahout实现推荐系统的又一案例,用Mahout构建图书推荐系统。与之前的两篇文章,思路上面类似,侧重点在于图书的属性如何利用。本文的数据在自于Amazon网站,由爬虫抓取获得。
目录
- 项目背景
- 需求分析
- 数据说明
- 算法模型
- 程序开发
1. 项目背景
Amazon是最早的电子商务网站之一,以网上图书起家,最后发展成为音像,电子消费品,游戏,生活用品等的综合性电子商务平台。Amazon的推荐系统,是互联网上最早的商品推荐系统,它为Amazon带来了至少30%的流量,和可观的销售利润。
如今推荐系统已经成为电子商务网站的标配,如果还没有推荐系统都不好意思,说自己是做电商的。
2. 需求分析
推荐系统如此重要,我们应该如果理解?
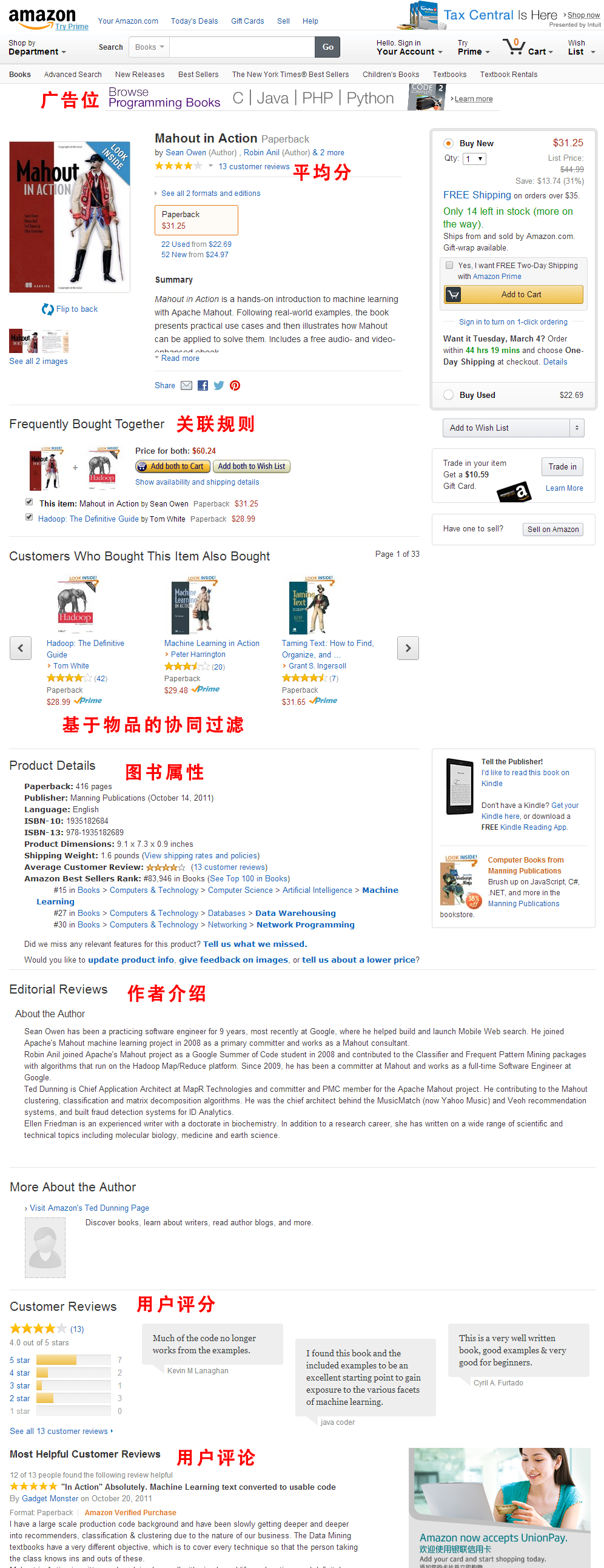
打开Amazon的Mahout In Action图书页面:
http://www.amazon.com/Mahout-Action-Sean-Owen/dp/1935182684/ref=pd_sim_b_1?ie=UTF8&refRID=0H4H2NSSR8F34R76E2TP
网页上的元素:
- 广告位:广告商投放广告的位置,网站可以靠网络广告赚钱,一般是网页最好的位置。
- 平均分:用户对图书的打分
- 关联规则:通过关联规则,推荐位
- 协同过滤:通过基于物品的协同过滤算法的,推荐位
- 图书属性:包括页数,出版社,ISBN,语言等
- 作者介绍:有关作者的介绍,和作者的其他著作
- 用户评分:用户评分行为
- 用户评论:用户评论的内容
在网页上,其他的推荐位:
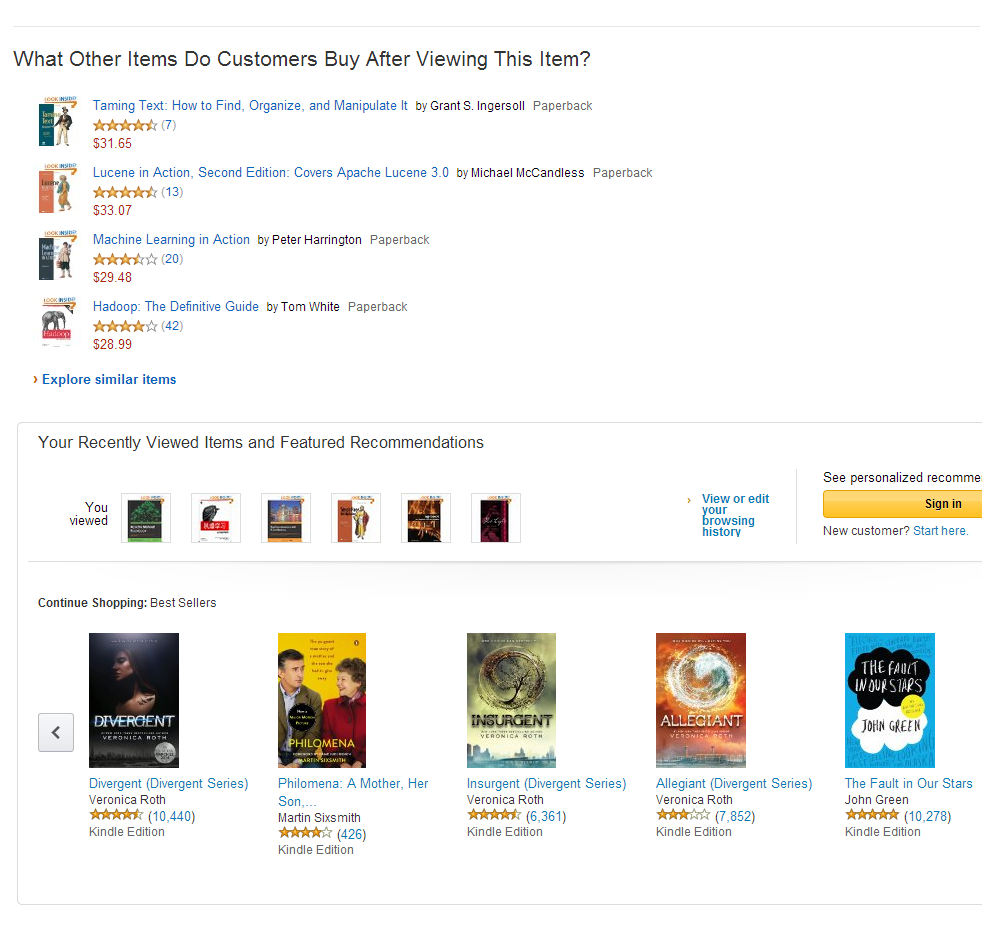
结合上面2张截图,我们不难发现,推荐对于Amazon的重要性。除了最明显的广告位给了能直接带来利润的广告商,网页中有4处推荐位,分别从不同的维度,用不同的推荐算法,猜用户喜欢的商品。
3. 数据说明
2个数据文件:
- rating.csv :用户评分行为数据
- users.csv :用户属性数据
1). book-ratings.csv
- 3列数据:用户ID,图书ID, 用户对图书的评分
- 记录数: 4000次的图书评分
- 用户数: 200个
- 图书数: 1000个
- 评分:1-10
数据示例
1,565,3
1,807,2
1,201,1
1,557,9
1,987,10
1,59,5
1,305,6
1,153,3
1,139,7
1,875,5
1,722,10
2,977,4
2,806,3
2,654,8
2,21,8
2,662,5
2,437,6
2,576,3
2,141,8
2,311,4
2,101,3
2,540,9
2,87,3
2,65,8
2,501,6
2,710,5
2,331,9
2,542,4
2,757,9
2,590,7
2). users.csv
- 3列数据:用户ID,用户性别,用户年龄
- 用户数: 200个
- 用户性别: M为男性,F为女性
- 用户年龄: 11-80岁之间
数据示例
1,M,40
2,M,27
3,M,41
4,F,43
5,F,16
6,M,36
7,F,36
8,F,46
9,M,50
10,M,21
11,F,11
12,M,42
13,F,40
14,F,28
15,M,25
16,M,68
17,M,53
18,F,69
19,F,48
20,F,56
21,F,36
4. 算法模型
本文主要介绍Mahout的基于物品的协同过滤模型,其他的算法模型将不再这里解释。
针对上面的数据,我将用7种算法组合进行测试:有关Mahout算法组合的详细解释,请参考文章:从源代码剖析Mahout推荐引擎
7种算法组合
- userCF1: EuclideanSimilarity+ NearestNUserNeighborhood+ GenericUserBasedRecommender
- userCF2: LogLikelihoodSimilarity+ NearestNUserNeighborhood+ GenericUserBasedRecommender
- userCF3: EuclideanSimilarity+ NearestNUserNeighborhood+ GenericBooleanPrefUserBasedRecommender
- itemCF1: EuclideanSimilarity + GenericItemBasedRecommender
- itemCF2: LogLikelihoodSimilarity + GenericItemBasedRecommender
- itemCF3: EuclideanSimilarity + GenericBooleanPrefItemBasedRecommender
- slopeOne:SlopeOneRecommender
对上面的算法进行算法评估,有关于算法评估的详细解释,请参考文章:Mahout推荐算法API详解
- 查准率:
- 召回率(查全率):
5. 程序开发
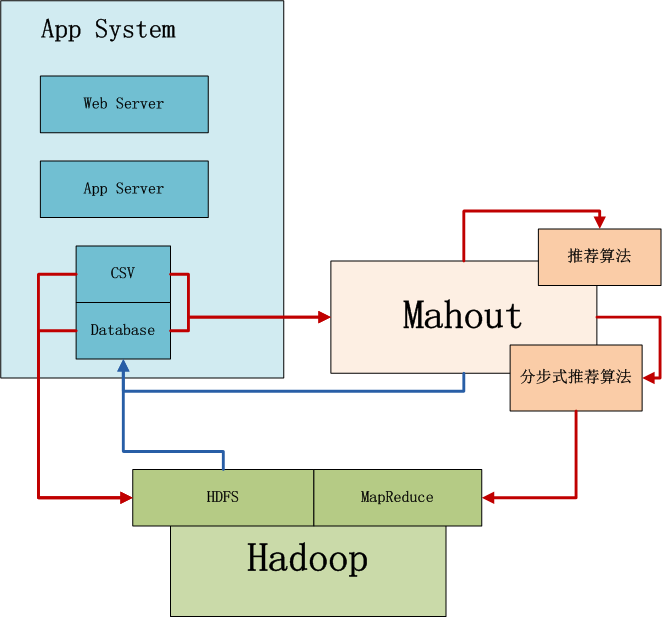
系统架构:Mahout中推荐过滤算法支持单机算法和分步式算法两种。
- 单机算法: 在单机内存计算,支持多种算法推荐算法,部署运行简单,修正处理数据量有限
- 分步式算法: 基于Hadoop集群运行,支持有限的几种推荐算法,部署运行复杂,支持海量数据
开发环境
- Win7 64bit
- Java 1.6.0_45
- Maven3
- Eclipse Juno Service Release 2
- Mahout-0.8
- Hadoop-1.1.2
开发环境mahout版本为0.8。 请参考文章:用Maven构建Mahout项目
新建Java类:
- BookEvaluator.java, 选出“评估推荐器”验证得分较高的算法
- BookResult.java, 对指定数量的结果人工比较
- BookFilterGenderResult.java,只保留男性用户的图书列表
1). BookEvaluator.java, 选出“评估推荐器”验证得分较高的算法
源代码
package org.conan.mymahout.recommendation.book;
import java.io.IOException;
import org.apache.mahout.cf.taste.common.TasteException;
import org.apache.mahout.cf.taste.eval.RecommenderBuilder;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.neighborhood.UserNeighborhood;
import org.apache.mahout.cf.taste.similarity.ItemSimilarity;
import org.apache.mahout.cf.taste.similarity.UserSimilarity;
public class BookEvaluator {
final static int NEIGHBORHOOD_NUM = 2;
final static int RECOMMENDER_NUM = 3;
public static void main(String[] args) throws TasteException, IOException {
String file = "datafile/book/rating.csv";
DataModel dataModel = RecommendFactory.buildDataModel(file);
userEuclidean(dataModel);
userLoglikelihood(dataModel);
userEuclideanNoPref(dataModel);
itemEuclidean(dataModel);
itemLoglikelihood(dataModel);
itemEuclideanNoPref(dataModel);
slopeOne(dataModel);
}
public static RecommenderBuilder userEuclidean(DataModel dataModel) throws TasteException, IOException {
System.out.println("userEuclidean");
UserSimilarity userSimilarity = RecommendFactory.userSimilarity(RecommendFactory.SIMILARITY.EUCLIDEAN, dataModel);
UserNeighborhood userNeighborhood = RecommendFactory.userNeighborhood(RecommendFactory.NEIGHBORHOOD.NEAREST, userSimilarity, dataModel, NEIGHBORHOOD_NUM);
RecommenderBuilder recommenderBuilder = RecommendFactory.userRecommender(userSimilarity, userNeighborhood, true);
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
return recommenderBuilder;
}
public static RecommenderBuilder userLoglikelihood(DataModel dataModel) throws TasteException, IOException {
System.out.println("userLoglikelihood");
UserSimilarity userSimilarity = RecommendFactory.userSimilarity(RecommendFactory.SIMILARITY.LOGLIKELIHOOD, dataModel);
UserNeighborhood userNeighborhood = RecommendFactory.userNeighborhood(RecommendFactory.NEIGHBORHOOD.NEAREST, userSimilarity, dataModel, NEIGHBORHOOD_NUM);
RecommenderBuilder recommenderBuilder = RecommendFactory.userRecommender(userSimilarity, userNeighborhood, true);
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
return recommenderBuilder;
}
public static RecommenderBuilder userEuclideanNoPref(DataModel dataModel) throws TasteException, IOException {
System.out.println("userEuclideanNoPref");
UserSimilarity userSimilarity = RecommendFactory.userSimilarity(RecommendFactory.SIMILARITY.EUCLIDEAN, dataModel);
UserNeighborhood userNeighborhood = RecommendFactory.userNeighborhood(RecommendFactory.NEIGHBORHOOD.NEAREST, userSimilarity, dataModel, NEIGHBORHOOD_NUM);
RecommenderBuilder recommenderBuilder = RecommendFactory.userRecommender(userSimilarity, userNeighborhood, false);
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
return recommenderBuilder;
}
public static RecommenderBuilder itemEuclidean(DataModel dataModel) throws TasteException, IOException {
System.out.println("itemEuclidean");
ItemSimilarity itemSimilarity = RecommendFactory.itemSimilarity(RecommendFactory.SIMILARITY.EUCLIDEAN, dataModel);
RecommenderBuilder recommenderBuilder = RecommendFactory.itemRecommender(itemSimilarity, true);
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
return recommenderBuilder;
}
public static RecommenderBuilder itemLoglikelihood(DataModel dataModel) throws TasteException, IOException {
System.out.println("itemLoglikelihood");
ItemSimilarity itemSimilarity = RecommendFactory.itemSimilarity(RecommendFactory.SIMILARITY.LOGLIKELIHOOD, dataModel);
RecommenderBuilder recommenderBuilder = RecommendFactory.itemRecommender(itemSimilarity, true);
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
return recommenderBuilder;
}
public static RecommenderBuilder itemEuclideanNoPref(DataModel dataModel) throws TasteException, IOException {
System.out.println("itemEuclideanNoPref");
ItemSimilarity itemSimilarity = RecommendFactory.itemSimilarity(RecommendFactory.SIMILARITY.EUCLIDEAN, dataModel);
RecommenderBuilder recommenderBuilder = RecommendFactory.itemRecommender(itemSimilarity, false);
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
return recommenderBuilder;
}
public static RecommenderBuilder slopeOne(DataModel dataModel) throws TasteException, IOException {
System.out.println("slopeOne");
RecommenderBuilder recommenderBuilder = RecommendFactory.slopeOneRecommender();
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
return recommenderBuilder;
}
}
控制台输出:
userEuclidean
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:0.33333325386047363
Recommender IR Evaluator: [Precision:0.3010752688172043,Recall:0.08542713567839195]
userLoglikelihood
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:2.5245869159698486
Recommender IR Evaluator: [Precision:0.11764705882352945,Recall:0.017587939698492466]
userEuclideanNoPref
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:4.288461538461536
Recommender IR Evaluator: [Precision:0.09045226130653267,Recall:0.09296482412060306]
itemEuclidean
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:1.408880928305655
Recommender IR Evaluator: [Precision:0.0,Recall:0.0]
itemLoglikelihood
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:2.448554412835434
Recommender IR Evaluator: [Precision:0.0,Recall:0.0]
itemEuclideanNoPref
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:2.5665197873957957
Recommender IR Evaluator: [Precision:0.6005025125628134,Recall:0.6055276381909548]
slopeOne
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:2.6893078179405814
Recommender IR Evaluator: [Precision:0.0,Recall:0.0]
可视化“评估推荐器”输出:
推荐的结果的平均距离
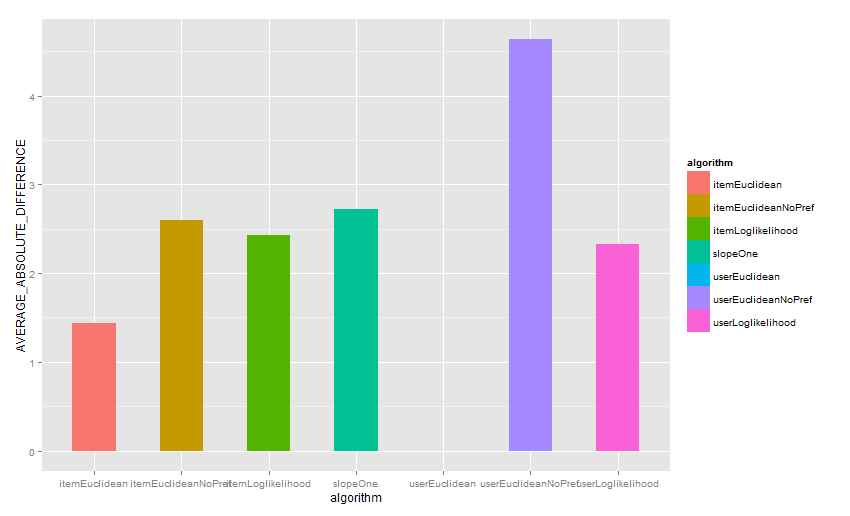
推荐器的评分
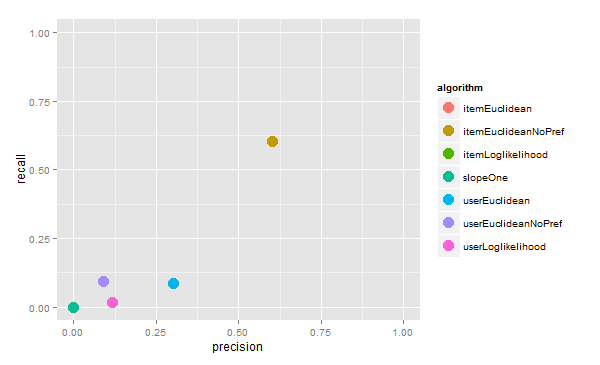
只有itemEuclideanNoPref算法评估的结果是非常好的,其他算法的结果都不太好。
2). BookResult.java, 对指定数量的结果人工比较
为得到差异化结果,我们分别取4个算法:userEuclidean,itemEuclidean,userEuclideanNoPref,itemEuclideanNoPref,对推荐结果人工比较。
源代码
package org.conan.mymahout.recommendation.book;
import java.io.IOException;
import java.util.List;
import org.apache.mahout.cf.taste.common.TasteException;
import org.apache.mahout.cf.taste.eval.RecommenderBuilder;
import org.apache.mahout.cf.taste.impl.common.LongPrimitiveIterator;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
public class BookResult {
final static int NEIGHBORHOOD_NUM = 2;
final static int RECOMMENDER_NUM = 3;
public static void main(String[] args) throws TasteException, IOException {
String file = "datafile/book/rating.csv";
DataModel dataModel = RecommendFactory.buildDataModel(file);
RecommenderBuilder rb1 = BookEvaluator.userEuclidean(dataModel);
RecommenderBuilder rb2 = BookEvaluator.itemEuclidean(dataModel);
RecommenderBuilder rb3 = BookEvaluator.userEuclideanNoPref(dataModel);
RecommenderBuilder rb4 = BookEvaluator.itemEuclideanNoPref(dataModel);
LongPrimitiveIterator iter = dataModel.getUserIDs();
while (iter.hasNext()) {
long uid = iter.nextLong();
System.out.print("userEuclidean =>");
result(uid, rb1, dataModel);
System.out.print("itemEuclidean =>");
result(uid, rb2, dataModel);
System.out.print("userEuclideanNoPref =>");
result(uid, rb3, dataModel);
System.out.print("itemEuclideanNoPref =>");
result(uid, rb4, dataModel);
}
}
public static void result(long uid, RecommenderBuilder recommenderBuilder, DataModel dataModel) throws TasteException {
List list = recommenderBuilder.buildRecommender(dataModel).recommend(uid, RECOMMENDER_NUM);
RecommendFactory.showItems(uid, list, false);
}
}
控制台输出:只截取部分结果
...
userEuclidean =>uid:63,
itemEuclidean =>uid:63,(984,9.000000)(690,9.000000)(943,8.875000)
userEuclideanNoPref =>uid:63,(4,1.000000)(723,1.000000)(300,1.000000)
itemEuclideanNoPref =>uid:63,(867,3.791667)(947,3.083333)(28,2.750000)
userEuclidean =>uid:64,
itemEuclidean =>uid:64,(368,8.615385)(714,8.200000)(290,8.142858)
userEuclideanNoPref =>uid:64,(860,1.000000)(490,1.000000)(64,1.000000)
itemEuclideanNoPref =>uid:64,(409,3.950000)(715,3.830627)(901,3.444048)
userEuclidean =>uid:65,(939,7.000000)
itemEuclidean =>uid:65,(550,9.000000)(334,9.000000)(469,9.000000)
userEuclideanNoPref =>uid:65,(939,2.000000)(185,1.000000)(736,1.000000)
itemEuclideanNoPref =>uid:65,(666,4.166667)(96,3.093931)(345,2.958333)
userEuclidean =>uid:66,
itemEuclidean =>uid:66,(971,9.900000)(656,9.600000)(918,9.577709)
userEuclideanNoPref =>uid:66,(6,1.000000)(492,1.000000)(676,1.000000)
itemEuclideanNoPref =>uid:66,(185,3.650000)(533,3.617307)(172,3.500000)
userEuclidean =>uid:67,
itemEuclidean =>uid:67,(663,9.700000)(987,9.625000)(486,9.600000)
userEuclideanNoPref =>uid:67,(732,1.000000)(828,1.000000)(113,1.000000)
itemEuclideanNoPref =>uid:67,(724,3.000000)(279,2.950000)(890,2.750000)
...
我们查看uid=65的用户推荐信息:
查看user.csv数据集
> user[65,]
userid gender age
65 65 M 14
用户65,男性,14岁。
以itemEuclideanNoPref的算法的推荐结果,查看bookid=666的图书评分情况
> rating[which(rating$bookid==666),]
userid bookid pref
646 44 666 10
1327 89 666 7
2470 165 666 3
2697 179 666 7
发现有4个用户对666的图书评分,查看这4个用户的属性数据
> user[c(44,89,165,179),]
userid gender age
44 44 F 76
89 89 M 40
165 165 F 59
179 179 F 68
这4个用户,3女1男。
我们假设男性和男性有相同的图书兴趣,女性和女性有相同的图书偏好。因为用户65是男性,所以我们接下来排除女性的评分者,只保留男性评分者的评分记录。
3). BookFilterGenderResult.java,只保留男性用户的图书列表
源代码
package org.conan.mymahout.recommendation.book;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import org.apache.mahout.cf.taste.common.TasteException;
import org.apache.mahout.cf.taste.eval.RecommenderBuilder;
import org.apache.mahout.cf.taste.impl.common.LongPrimitiveIterator;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.recommender.IDRescorer;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
public class BookFilterGenderResult {
final static int NEIGHBORHOOD_NUM = 2;
final static int RECOMMENDER_NUM = 3;
public static void main(String[] args) throws TasteException, IOException {
String file = "datafile/book/rating.csv";
DataModel dataModel = RecommendFactory.buildDataModel(file);
RecommenderBuilder rb1 = BookEvaluator.userEuclidean(dataModel);
RecommenderBuilder rb2 = BookEvaluator.itemEuclidean(dataModel);
RecommenderBuilder rb3 = BookEvaluator.userEuclideanNoPref(dataModel);
RecommenderBuilder rb4 = BookEvaluator.itemEuclideanNoPref(dataModel);
long uid = 65;
System.out.print("userEuclidean =>");
filterGender(uid, rb1, dataModel);
System.out.print("itemEuclidean =>");
filterGender(uid, rb2, dataModel);
System.out.print("userEuclideanNoPref =>");
filterGender(uid, rb3, dataModel);
System.out.print("itemEuclideanNoPref =>");
filterGender(uid, rb4, dataModel);
}
/**
* 对用户性别进行过滤
*/
public static void filterGender(long uid, RecommenderBuilder recommenderBuilder, DataModel dataModel) throws TasteException, IOException {
Set userids = getMale("datafile/book/user.csv");
//计算男性用户打分过的图书
Set bookids = new HashSet();
for (long uids : userids) {
LongPrimitiveIterator iter = dataModel.getItemIDsFromUser(uids).iterator();
while (iter.hasNext()) {
long bookid = iter.next();
bookids.add(bookid);
}
}
IDRescorer rescorer = new FilterRescorer(bookids);
List list = recommenderBuilder.buildRecommender(dataModel).recommend(uid, RECOMMENDER_NUM, rescorer);
RecommendFactory.showItems(uid, list, false);
}
/**
* 获得男性用户ID
*/
public static Set getMale(String file) throws IOException {
BufferedReader br = new BufferedReader(new FileReader(new File(file)));
Set userids = new HashSet();
String s = null;
while ((s = br.readLine()) != null) {
String[] cols = s.split(",");
if (cols[1].equals("M")) {// 判断男性用户
userids.add(Long.parseLong(cols[0]));
}
}
br.close();
return userids;
}
}
/**
* 对结果重计算
*/
class FilterRescorer implements IDRescorer {
final private Set userids;
public FilterRescorer(Set userids) {
this.userids = userids;
}
@Override
public double rescore(long id, double originalScore) {
return isFiltered(id) ? Double.NaN : originalScore;
}
@Override
public boolean isFiltered(long id) {
return userids.contains(id);
}
}
控制台输出:
userEuclidean =>uid:65,
itemEuclidean =>uid:65,(784,8.090909)(276,8.000000)(476,7.666667)
userEuclideanNoPref =>uid:65,
itemEuclideanNoPref =>uid:65,(887,2.250000)(356,2.166667)(430,1.866667)
我们发现,由于只保留男性的评分记录,数据量就变得比较少了,基于用户的协同过滤算法,已经没有输出的结果了。基于物品的协同过滤算法,结果集也有所变化。
对于itemEuclideanNoPref算法,输出排名第一条为ID为887的图书。
我再进一步向下追踪:查询哪些用户对图书887进行了打分。
> rating[which(rating$bookid==887),]
userid bookid pref
1280 85 887 2
1743 119 887 8
2757 184 887 4
2791 186 887 5
有4个用户对图书887评分,再分别查看这个用户的属性
> user[c(85,119,184,186),]
userid gender age
85 85 F 31
119 119 F 49
184 184 M 27
186 186 M 35
其中2男,2女。由于我们的算法,已经排除了女性的评分,我们可以推断图书887的推荐应该来自于2个男性的评分者的推荐。
分别计算用户65,与用户184和用户186的评分的图书交集。
rat65<-rating[which(rating$userid==65),]
rat184<-rating[which(rating$userid==184),]
rat186<-rating[which(rating$userid==186),]
> intersect(rat65$bookid ,rat184$bookid)
integer(0)
> intersect(rat65$bookid ,rat186$bookid)
[1] 65 375
最后发现,用户65与用户186都给图书65和图书375打过分。我们再打分出用户186的评分记录。
> rat186
userid bookid pref
2790 186 65 7
2791 186 887 5
2792 186 529 3
2793 186 375 6
2794 186 566 7
2795 186 169 4
2796 186 907 1
2797 186 821 2
2798 186 720 5
2799 186 642 5
2800 186 137 3
2801 186 744 1
2802 186 896 2
2803 186 156 6
2804 186 392 3
2805 186 386 3
2806 186 901 7
2807 186 69 6
2808 186 845 6
2809 186 998 3
用户186,还给图书887打过分,所以对于给65用户推荐图书887,是合理的。
我们通过一个实际的图书推荐的案例,更进一步地了解了如何用Mahout构建推荐系统。
作者介绍:
张丹,R语言中文社区专栏特邀作者,《R的极客理想》系列图书作者,民生银行大数据中心数据分析师,前况客创始人兼CTO。
10年IT编程背景,精通R ,Java, Nodejs 编程,获得10项SUN及IBM技术认证。丰富的互联网应用开发架构经验,金融大数据专家。个人博客 http://fens.me, Alexa全球排名70k。
著有《R的极客理想-工具篇》、《R的极客理想-高级开发篇》,合著《数据实践之美》,新书《R的极客理想-量化投资篇》(即将出版)。

《R的极客理想-工具篇》京东购买快速通道:https://item.jd.com/11524750.html
《R的极客理想-高级开发篇》京东购买快速通道:https://item.jd.com/11731967.html
《数据实践之美》京东购买快速通道:https://item.jd.com/12106224.html