(本讲相关数据请在公众号后台回复:“R第一讲”四个字获得)
昨天已经装好了R和Rstudio了,我习惯使用Rstudio,因为它除了美观外还有许多便利之处,以后的使用中大家就可以慢慢体会了,学校机房用的是R,我平常用的是Rstudio,所以有时候突然从Rstudio转到R会很不适应呢。
现在打开Rstudio。我们会发现R是单一的界面,而Rstudio为四个象限的界面。左上为脚本区;左下为控制台(同R的操作界面);右上为变量和环境;右下为视图区。

刚开始,你的界面不是这样,要自己根据自己的习惯和爱好自己设置,包括字体和背景的颜色以及界面的面板布局。下面介绍一下怎么设置。
tools —> Global Options

颜色在“Appearance” 里,界面的面板布局在“Pane Layout”里

Appearance

Pane Layout:如下图,面板布局正好对应于你的界面

上图中的红框处是可以选择的,如下图

以上是开篇附加的题外话,分割线以下开始正题。
本讲相关数据请在公众号后台回复:“R第一讲”四个字即可获得。
1、如何将Excel表格中的数据导入R软件中?
要对数据进行处理,第一步当然是先知道怎么将数据导入到R中,我们最常用的数据保存形式是Excel表格。后台回复“R第一讲”四个字获得,Excel表格是xls格式,需要将格式改成“csv”才能被R识别出来。
(大家获得的数据已经是csv格式了,改格式很简单,直接将后缀改掉或者打开文件后“另存为”自己想要的格式)
非常简单,你只需要在脚本框或控制台输入以下一组代码:
(脚本框输入后便于保存,而且可以一口气写完代码后再查看,但想要运行代码就需要选中需要运行的代码然后按住“Ctrl+R”或“Ctrl+Enter”使脚本在控制台上运行;控制台上则不同每写一行代码后只需要点击“Enter”就可以实时运行代码。我喜欢在脚本框输代码,后面的代码都是在脚本框输入的)
read.table(file = "e:\\Rwork/Datafolder/data001.csv",header = T,sep = ",")

我知道看到代码你就凌乱了,别方,且听我解释。上面的代码 read.table()是一个函数,括号内……
等等,函数是什么鬼?
嗯,问得好,计算机语言中函数跟我们中学学的概念可是大不相同的,你只要知道它是function(功能)就好了,函数是计算机语言中原有的,不能更改,每个函数都有自己特定的功能,以后接触多了就好理解了,别方哈。所以下次提到函数,你脑海里别再蹦出中学的各种线条或函数表达式,而要在心里默念:这是一种功能。所以read.table()的功能就是“读取表格”咯,简单吧。
括号内的内容就是在告诉机器(电脑)该怎么读取表格,它用到了参数(Arguments)的概念,每个参数之间用逗号隔开,上面的file、header、sep就是3个参数,分别代表“文件、表头、分隔符”,所以就是在告诉电脑我要读取的文件在电脑哪个地方,读进来之后要不要表头,要根据什么分隔符来辨认出数据(电脑很笨的——额,人类的角度这样认为——,一个表格我们一眼就看得出数据是被表格的横竖的线条分开的,但是电脑只会从头到尾读,只有读到“分隔符”的时候它才知道数据在这里需要被分开,csv格式的文件看起来也是横竖线条分隔数据的,但是R读进去后其实将横竖线条读成了逗号(“,”))。
参数file后面的引号内的内容就是告诉电脑文件的位置;参数header后面的“T”是“TRUE(真的)”的缩写,是告诉电脑我要保留表头,不要表头的话就写F(即FALSE);sep就是分隔符的意思了。
啊,终于解释完了,现在我来帮助机器将上面那一条代码翻译给你们人类听吧(其实这还不是最原始的代码,最原始的代码是“0”和“1”排列组合的,这个再解释就太多了,感兴趣的自己去找资料了解一下,不知道也不影响后面学习)。
上面的代码从左到右翻译出来就是:我现在要执行读取表格的功能,你要去e盘下,打开Rwork文件夹,再打开Datafolder文件夹,读取"data001.csv"这个文件。读取时要保留第一行的表头,数据之间的分隔符号是逗号。
嗯,上面的一条代码就是在跟电脑说这些的。当然,上述文件夹的位置可以是任意的,看你把“data001”这个文件放在哪里了。
上面的介绍虽然有些繁琐,但是对于初学者还是很有必要了解的,以后就不会一直翻译了。
表格已经读进来了,可是难道我每次用都要输入那一串代码吗?当然不用,你只需要将第一次读取的信息存储在一个变量中,变量是你自己随便取名的,但不能取函数的名字,由字母、符号、数字都行,开头必须是字母,我这里变量取的是“x”,用了一个赋值符号连接“<-”(减号和小于号),对了,R中写代码必须都是输入法在英文状态下写,否则识别会出错误。存储后,下次我们要用表格就直接输入“x”就行了。
2、如何查看表格中的前几行内容?
输入x[50,]

运行后就会显示出表格的前50行的所有内容,中括号用来表示一个变量内容中的位置,逗号前为行,逗号后为列,[20,10]就表示变量中的第20行第10列;不写行或列,比如[,10]或[20,],就分别代表显示出第10列的所有内容或第20行的所有内容。(所以这里的中括号(“[ , ]”)本身其实也是函数,它的功能就是给变量所存储的数据进行定位)
(其实从大多数函数的格式上看,上述表达应该长这样的:“[50, ](x)”,但是可能由于美观和便利性等原因,它最终发展成了现在的形式)
当然还有一个函数也可以只显示前几行但它不如前一种方法自由:
head(x)
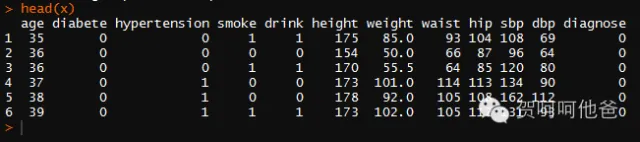
3、如何从总体中随机抽取样本?
"data001.csv"这个文件有278个病例,前169个为正常人(对照组),后109个为糖尿病患者(实验组)。
如果我们要从对照组和实验组中分别抽取30个样本出来进行研究,该怎么做呢?
我们先做一个简单的随机抽样,来说明随机抽样是怎么操作的。
比如,我们要从278个病例中随机抽取100个样本该怎么操作?首先病人的序列号为1—278,我们其实只需要从1到278这278个数字中随机抽取100个序列号,然后将表格中(即变量x)与序列号对应的序列号和全部信息提取出来,这样就是整个的思路。
先调用sample()这个函数抽取序列号,并将所得的100个序列号存储在变量a1中(序列号为随机抽取的,所以每个人得到的数据肯定不一样)

我们再将变量x中是a1中的序列的病例信息调取出来,并储存在新的变量“newdata_x1”中:

这样,我们就得到了100个随机抽取的病例样本。
再回到前面的问题“如果我们要从对照组和实验组中分别抽取30个样本出来进行研究,该怎么做呢?”,代码如下,聪明的你,应该可以推测出来(这里的“c()”是什么?往下看):

这里唯一不同的就是出现了一个“c()”,当然,它也是一个函数,而且是R中最多、最简单、最基本的函数(你以后会反复看到c函数的),表示“集合”的意思,所以代码中C函数里有两个抽样,这两个抽样取得的数据就组成了一个集合,最终一起存储在变量a2中。这样就得到了由30个对照组和30个实验组的病例组成的样本了。
到这里你已经学会如何用R进行简单的随机抽样了。在数据挖掘中常常需要将挖掘的数据对象分成“训练集”和“测试集”,“训练集”用来构造模型,“测试集”用来检测模型的可靠性。那么问题来了:
4、怎样将数据随机分成“训练集”和“测试集”?
这里我们假设要从这278个病例中随机抽取150个病例作为“训练集”,剩下的病例(128例)都作为“测试集”。

这只是“训练集”,那“测试集”呢,278个病例现在已经被随机的抽走了150例了,剩余的128例已经“面目全非”,该怎么得到呢?你可能会说,抽走了,剩余的不就是了,对啊,可是你怎么告诉电脑,你得跟它说,让它听得懂的话,要站在它的角度用它的思维去考虑。我们这样做:

我们只是在变量a3的前面加了一个减号(“-”),这个减号就代表278例中除了被抽走的a3以外的数据。
"训练集"和"测试集"都已经分别保存在“train”和“test”这两个变量中,但它们都还只是软件中的变量,我需要把它保存成两个表格文件,方便以后使用,该怎么办呢?
5、如何将储存在变量中的数据导出到Excel表格?
我们要用到“写出文件”的函数,即write.csv( ).

它括号内的两个参数,第一个放需要导出的变量,第二个参数(file)写明想要文件保存在电脑的哪个位置,以及保存为什么名字。你输入后,控制台看似没有什么反应,但只要没有报错,就说明文件已经保存了,你可以去相应的文件夹查看。

6、R基于向量的基本运算
R的计算是基于“向量”的计算,“向量”也不是我们中学学的有方向和大小的量,你就简单的记成“集合”吧,“集合”?对,熟悉吧?就是上面提到的“c()”函数了,所以R中向量“1:5”和“c(1:5)”是完全等价的(“1:5”读作“1到5”,即1,2,3,4,5),如下:

计算器中的四则运算在R中操作是完全一样的,这个太简单了,大家自己去试试,我要强调的是R中的这种“向量”处理的思想和意识,就是把一个集合当做一个整体来运算,下面通过代码感受一下

这里举得例子,集合只是很小的数据,其实它完全可以书表格等等各种数据形式,所以可以想象到它的便利和高效了。
7、R的矩阵运算
所谓“矩阵”就是二维的数据阵列,完全可以理解为是R中的表格,可以创造矩阵的主要有2个函数:
matrix()函数和array()函数,matrix即矩阵,array是数组的意思,下面以1到20这20个数据为例,创造4行5列的矩阵:

matrix()中的参数分别为数据(1:20),行(4),列(5),排列方式(按照行排列)
array()数组的参数则是数据(1:20)和维度(dim),而维度中一维即行数为4,二维即列数为5,其实是可以产生三维数字的,只不过在此只用了前两个维度产生矩阵,产生三维数组的情况

矩阵也可以进行四则运算运算,由于不是这里的重点,简要介绍转置和合并。
转置就是将矩阵的行列颠倒转换位置,对应的函数为t()函数:如下

感受一下A和t(A)的区别。
合并就是将多个矩阵合并为一个矩阵的过程,按照行合并的函数为rbind();按照列合并的函数为cbind()函数。我们在创建一个数字全部为2的也为3行4列的矩阵使它跟A进行合并:

8、用R进行统计学的描述性分析(统计指标和统计图)
(1)常见的统计指标
有平均值(mean)、和(sum)、排序(sort)、中位数(median)、方差(var)、标准差(sd)、最大值(max)、最小值(min)等。它们对应的函数就是括号中的英文,非常简单、简洁吧?
我们现在继续用上面的数据,仅拿出患者的“age”年龄一项进行上面的这些统计指标分析。最开始的变量x还记得吧?我们将278个病例表格数据存储在其中,我们现在用head()函数看看它的前几项,确保它还在

嗯,看来真的还在。再将所有的年龄(age)数据调取出来并存在变量“age_data”中,年龄数据是变量x中的第一列,可以用前面学过的“x[ ,1]”调取出来,如下:

这就得到了278个年龄数据。
下面求这278个年龄数据的常规的统计指标:

怎么样?感受到它的“简洁”了吧。干净利落!
(2)统计图
这里简单介绍直方图(hist)、正态性检验(QQ图)、相关分析(cor.test)、一元线性回归(linear、abline)。
直方图
用hist()函数,我们画出年龄的直方图:

hist的参数中,第一个参数(data_age)为数据(即上文的年龄);第二个参数(col)为直方的颜色,第四个参数(border)为边框的颜色。参数的值都是可以自己设置的。我们来看一下效果:

图形出现在右下角的视图框中,点击放大镜(Zoom),可以将图放大,并可以保存为图片。

QQ图:
用qqnorm()和qqline()来进行正态性检验,我们还是检查年龄的正态性


相关分析
用cor.test()函数可以进行相关分析,此处涉及两个变量,我们再加入变量x中的收缩压(sbp)这组数据与年龄进行分析,看年龄与收缩压之间的相关性(sbp是表格中的第10列数据,故变量sbp_data <- x[,10]):

相关分析结果如下:

P值为3.283*10的负6次方,有显著差异,相关系数为0,27487,所以年龄与收缩压正相关。
一元线性回归:
既然年龄与收缩压有线性相关,接下来就进行回归分析了。
用lm()函数可以得到一元回归模型的回归系数,用abline()函数可以将直线模型画在散点图上:

分析结果显示常数项为111.0538;回归系数为0.4428.
所以因变量Y(收缩压)与自变量X(年龄)之间的回归模型即为:
Y=111.0538+0.4428X
下面用abline()函数将回归模型整合到散点图中去:

结果如下:

第一讲终于讲解完了。欢迎继续关注。下周(第二讲)内容:回归分析(包括多重线性回归、Logistic回归、Cox回归分析)
再次提示:本讲相关数据请在公众号后台回复:“R第一讲”四个字即可获得
【本文为原创文章,欢迎转发分享】
公众号转载请加[微信号:Heherpapa2016],获得本人授权后方可转载
未经授权禁止转载
“贺呵呵他爸”是一个个人公众号,旨在敦促自己不断学习,同时为大家分享个人的学习总结。内容涵盖:【神经科学】、【癫痫】、【统计与R软件】、【读书】
如果你喜欢,欢迎按下图方式关注我的公众号

首医医学硕士|贺呵呵他爸
微信ID:Heherpapa 长按二维码关注微互动
长按二维码关注微互动
