目标网址This is a python demo page
主要使用BeautifulSoup的findall_all方法
>>> import requests
>>> r = requests.get('http://python123.io/ws/demo.html')
>>> demo = r.text
>>> demo
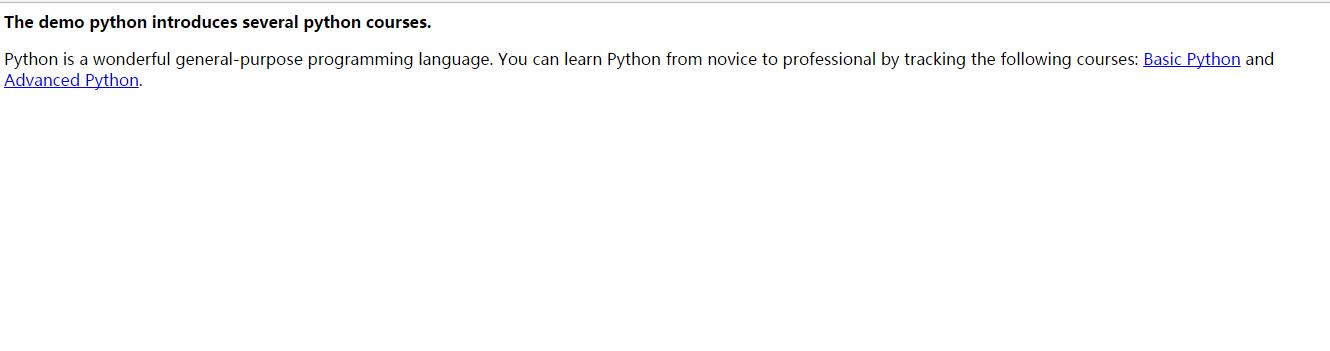
'<html><head><title>This is a python demo page</title></head>\r\n<body>\r\n<p class="title"><b>The demo python introduces several python courses.</b></p>\r\n<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\r\n<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p>\r\n</body></html>'
find_all( name , attrs , recursive , string , **kwargs )
返回一个列表内心,存储查找的结果
.name : 对标签名称的检索字符串
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(demo,'html.parser')
>>> soup.find_all('a')
[<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>, <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>]
>>> soup.find_all(['a','b'])
[<b>The demo python introduces several python courses.</b>, <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>, <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>]
>>> for tag in soup.find_all(True):
print(tag.name)
#True 可以匹配任何值,下面代码查找到所有的tag,但是不会返回字符串节点
html
head
title
body
p
b
p
a
a
>>> import re
>>> for tag in soup.find_all(re.compile('b'))#正则:
print(tag.name)
body
b
.attrs : 对标签属性的前所字符串,可标注属性检索
>>> soup.find_all('p','course')
[<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>]
>>> soup.find_all(id = 'link1')
[<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>]
>>> import re
>>> soup.find_all(id=re.compile('link'))
[<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>, <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>]
.recursive : 是否对子孙全部检索,默认True
>>> soup.find_all('a')
[<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>, <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>]
>>> soup.find_all('a',recursive=False)
[]
.string : <>...</>中字符串区域的检索字符串
>>> soup
<html><head><title>This is a python demo page</title></head>
<body>
<p class="title"><b>The demo python introduces several python courses.</b></p>
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>
</body></html>
>>> soup.find_all(string='Basic Python')
['Basic Python']
>>> import re
>>> soup.find_all(string=re.compile('python'))
['This is a python demo page', 'The demo python introduces several python courses.']
Tips:
<tag>(..) 等价于 <tag>.find_all(..)
soup(..) 等价于 soup.find_all(..)
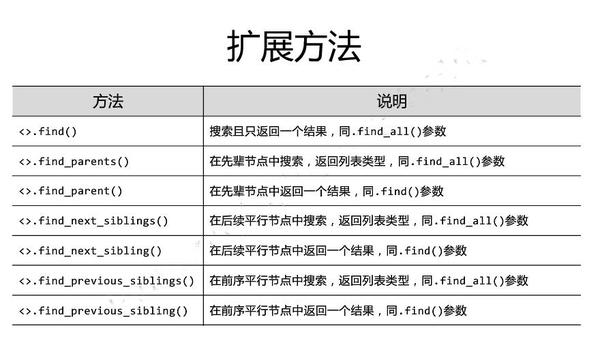
来源:Python网络爬虫与信息提取_北京理工大学_中国大学MOOC(慕课)
