kettle作为etl工具同步数据到hive,直接使用表输出或者插入更新组件出现速度秒级一条的尴尬,为了解决这种输出端数据同步瓶颈及缓解给领导交代的窘态,在项目中使用了Hadoop File Output组件,流程如下:
一、连接hadoop配置
1、点击kettle big data 配置文件
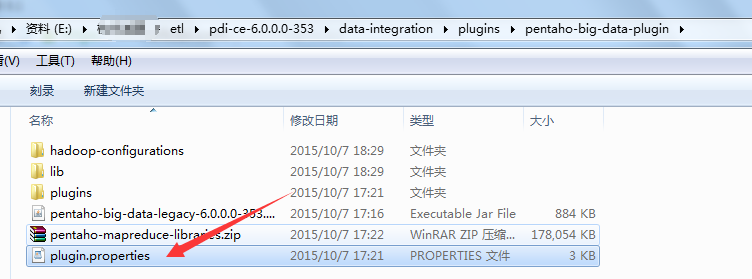
2、修改active.hadoop.configuration值为hdp47(对应与下一步hadoop配置文件)
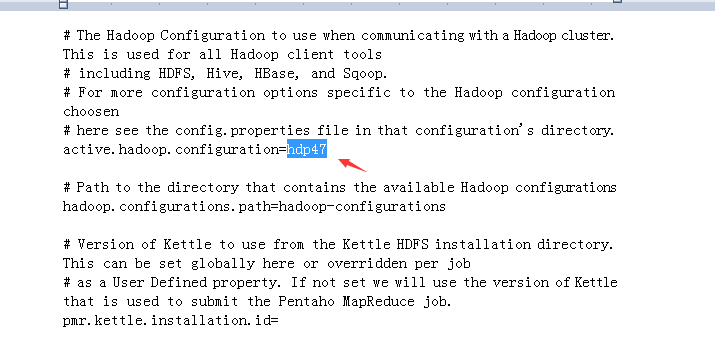
3、修改hadoop-configurations下一个文件名字为上述active.hadoop.configuration对应名字
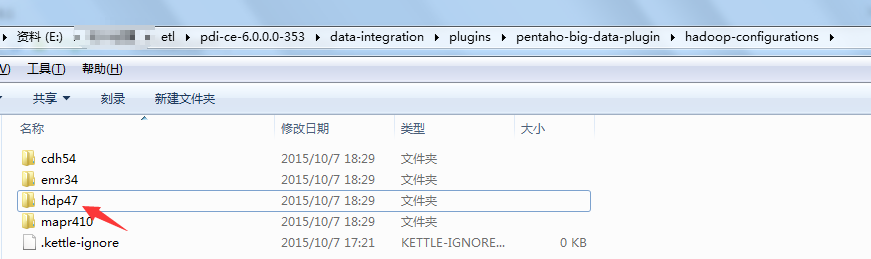
4、copy集群的配置文件到hdp47下,并覆盖
需要的文件:core-site.xml、hbase-site.xml、mapred-site.xml、yarn-site.xml
5、copy集群夹包inceptor-driver.jar(本集群使用星环)到hdp47/lib下
二、Hadoop File Output的使用
1、编辑连接:选择主对象树种 Hadoop clusters 右击新建
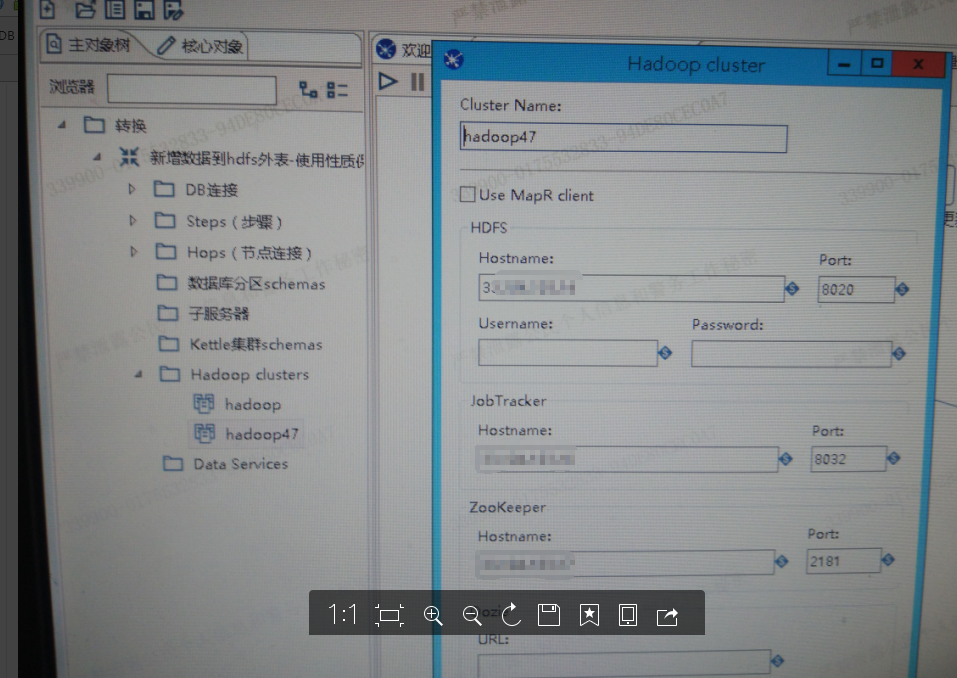
其中:Cluster Name 自定义集群名字;Hdfs Hostname为集群active Namenode ip,端口默认为8020;JobTracker为集群运用resource manager 权限的节点ip,端口默认为8032;ZooKeeper Hostname为对应节点ip,默认端口为2181;Oozie可不填。
点击测试:
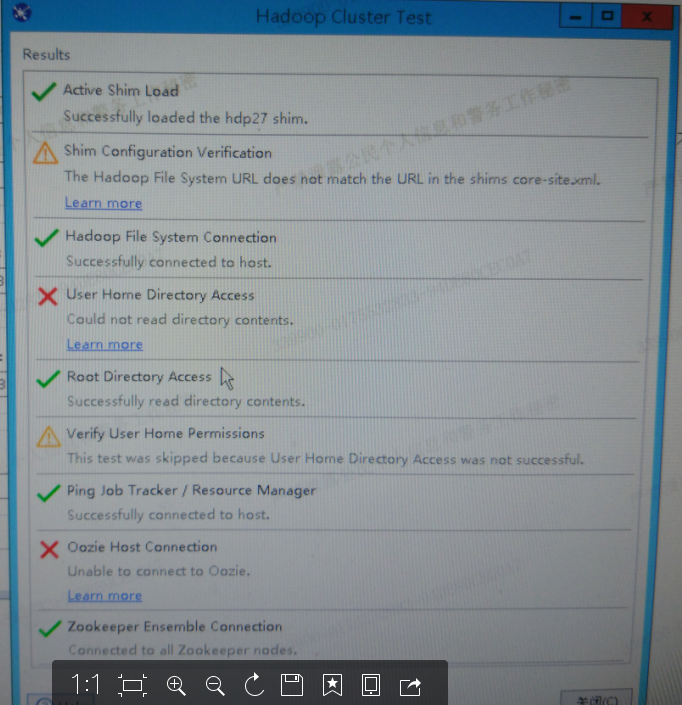
ok,连接成功!
2、新建转换,选择big Data下的Hadoop File Input

3、选择新建好的Hadoop cluster ,点击浏览指定数据存放hdfs位置
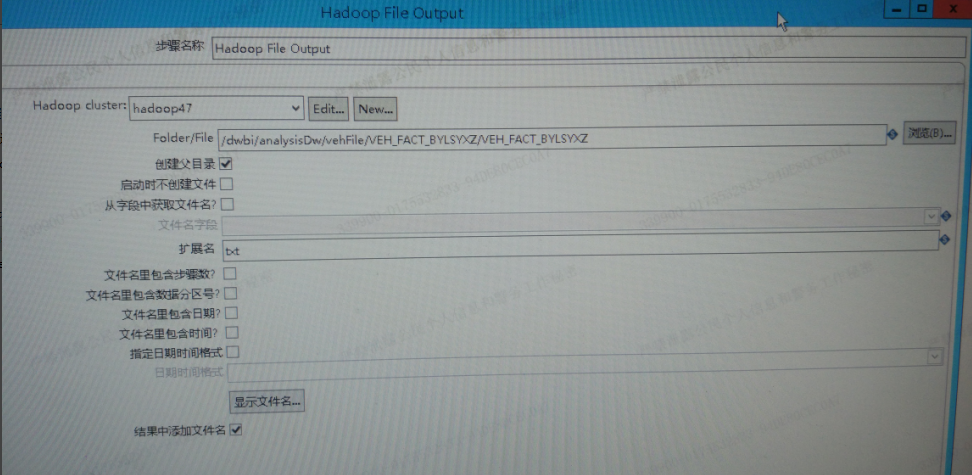
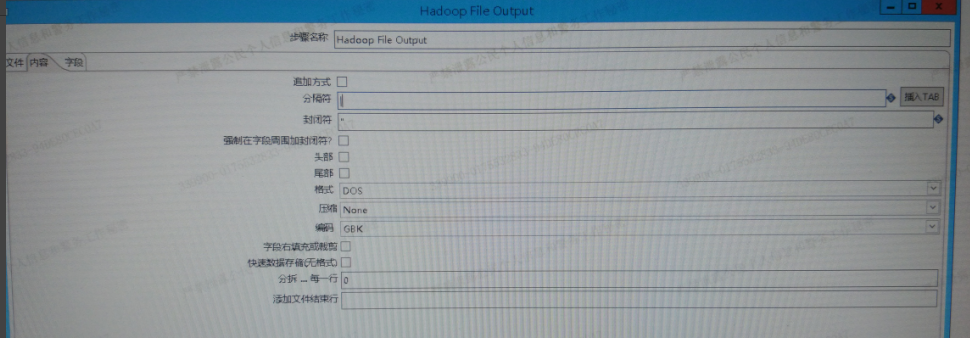
4、内容tab,可选择是否追加数据,分隔符选择要与hive外表字段分割符相对应(row format delimited fields terminated by '|' loaction '/../../文件位置'),
格式默认为dos(注:当导入数据到hive中字段出现特殊字符时,可在此选择为Unix~经验之谈)
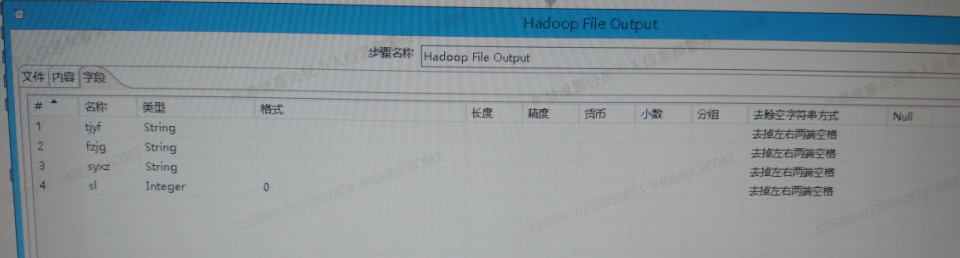
5、字段tab,获取字段并选择最小宽带
6、点击确定,程序成功运行
7、通过hdfs查看同步的对应数据
查看数据:
Hdfs dfs -cat /dwbi/basicDw/drivinglicense/drivinglicense.txt
查看hdfs文件行数:
Hdfs dfs -cat /dwbi/basicDw/drivinglicense/part-m* | wc -l
统计文件大小:
hadoop fs -count /dwbi/basicDw/drivinglicense/part-m*
8、测试集群连接出现错误: noclassdeffouderror could not initlatize class org.apache.hadoop.hdfs.server.namenode.namenode
解决办法:
运行:
find /usr/lib -name "*.jar" -exec grep -Hsli 'org/apache/hadoop/hdfs/server/namenode/Namenode' {} \;
然后版jar包放到 hdp47/lib下
华青莲日常点滴,方便自己成长他人!
